MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
2309.12284
0
0

Abstract
Large language models (LLMs) have pushed the limits of natural language understanding and exhibited excellent problem-solving ability. Despite the great success, most existing open-source LLMs (e.g., LLaMA-2) are still far away from satisfactory for solving mathematical problem due to the complex reasoning procedures. To bridge this gap, we propose MetaMath, a fine-tuned language model that specializes in mathematical reasoning. Specifically, we start by bootstrapping mathematical questions by rewriting the question from multiple perspectives without extra knowledge, which results in a new dataset called MetaMathQA. Then we fine-tune the LLaMA-2 models on MetaMathQA. Experimental results on two popular benchmarks (i.e., GSM8K and MATH) for mathematical reasoning demonstrate that MetaMath outperforms a suite of open-source LLMs by a significant margin. Our MetaMath-7B model achieves 66.4% on GSM8K and 19.4% on MATH, exceeding the state-of-the-art models of the same size by 11.5% and 8.7%. Particularly, MetaMath-70B achieves an accuracy of 82.3% on GSM8K, slightly better than GPT-3.5-Turbo. We release all the MetaMathQA dataset, the MetaMath models with different model sizes and the training code for public use.
Create account to get full access
Overview
- The paper explores a novel approach called "MetaMath" that allows users to bootstrap their own mathematical questions for large language models (LLMs)
- The key idea is to leverage LLMs' natural language understanding capabilities to generate and evaluate custom mathematical prompts
- This enables users to create tailored learning experiences and assess LLM performance on specific mathematical skills
Plain English Explanation
The paper introduces a technique called "MetaMath" that lets you create your own custom math problems for large language models (LLMs) to solve. LLMs are AI systems that are very good at understanding and generating human language. MetaMath harnesses this language ability to help you design math questions that are tailored to your specific needs or interests.
Rather than relying on pre-made math problems, MetaMath allows you to bootstrap your own questions from scratch. You can craft prompts that focus on particular math skills, concepts, or applications that you want to explore. The LLM then generates candidate math problems based on your input, and evaluates how well it can solve them.
This custom approach has several benefits. It lets you personalize the learning process and target areas you want to improve in. It also provides a way to test the mathematical reasoning capabilities of LLMs in more specific and nuanced ways, beyond generic benchmarks. By generating their own questions, users can gain deeper insights into the strengths and limitations of these powerful language models when it comes to math.
Technical Explanation
The core of the MetaMath framework is a prompt-based generation and evaluation system that leverages large language models (LLMs). Users provide MetaMath with a high-level description of the type of math problem they want the LLM to generate. This could be anything from basic arithmetic to advanced calculus concepts.
MetaMath then uses the LLM to iteratively refine and evaluate candidate math problems that match the user's specifications. The LLM first generates an initial math prompt, which is then assessed for qualities like mathematical correctness, difficulty level, and alignment with the user's intent. Based on this evaluation, MetaMath provides feedback to the LLM to improve the prompt. This back-and-forth continues until a satisfactory math problem is produced.
By putting the LLM in the loop, MetaMath taps into its natural language understanding and generation capabilities to bootstrap custom math questions. This contrasts with traditional approaches that rely on pre-defined math problem datasets. MetaMath's flexible, user-driven framework allows for the creation of tailored learning experiences and more nuanced assessments of LLM mathematical reasoning abilities.
Critical Analysis
The MetaMath approach presents an interesting way to leverage large language models for customized mathematical learning and evaluation. By allowing users to generate their own prompts, it enables more personalized and targeted experiences compared to static problem sets.
However, the paper does not address some potential limitations and challenges. For example, the quality and difficulty of the generated math problems may be inconsistent, as they rely on the LLM's understanding and generation capabilities. There could also be biases or blindspots in the types of math problems the LLM is able to produce, based on its training data and architecture.
Additionally, the iterative prompt refinement process may become computationally expensive, especially for more complex math concepts. The paper also does not explore the scalability of MetaMath to generate a large, diverse set of math problems for comprehensive assessment.
Further research could investigate techniques to improve the reliability, robustness, and efficiency of the MetaMath framework. Comparisons to other approaches, such as MathSensei or DeepSEEKMath, could also provide valuable insights.
Conclusion
The MetaMath paper presents a novel approach to leveraging large language models for customized mathematical learning and evaluation. By enabling users to bootstrap their own math prompts, it offers a flexible framework for creating personalized experiences and probing the mathematical reasoning capabilities of these powerful AI systems.
While the paper highlights the potential of this approach, it also raises questions about the consistency, scalability, and reliability of the generated math problems. Addressing these challenges through further research could lead to more robust and practical applications of MetaMath, with implications for both educational and assessment use cases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Mathify: Evaluating Large Language Models on Mathematical Problem Solving Tasks
Avinash Anand, Mohit Gupta, Kritarth Prasad, Navya Singla, Sanjana Sanjeev, Jatin Kumar, Adarsh Raj Shivam, Rajiv Ratn Shah
0
0
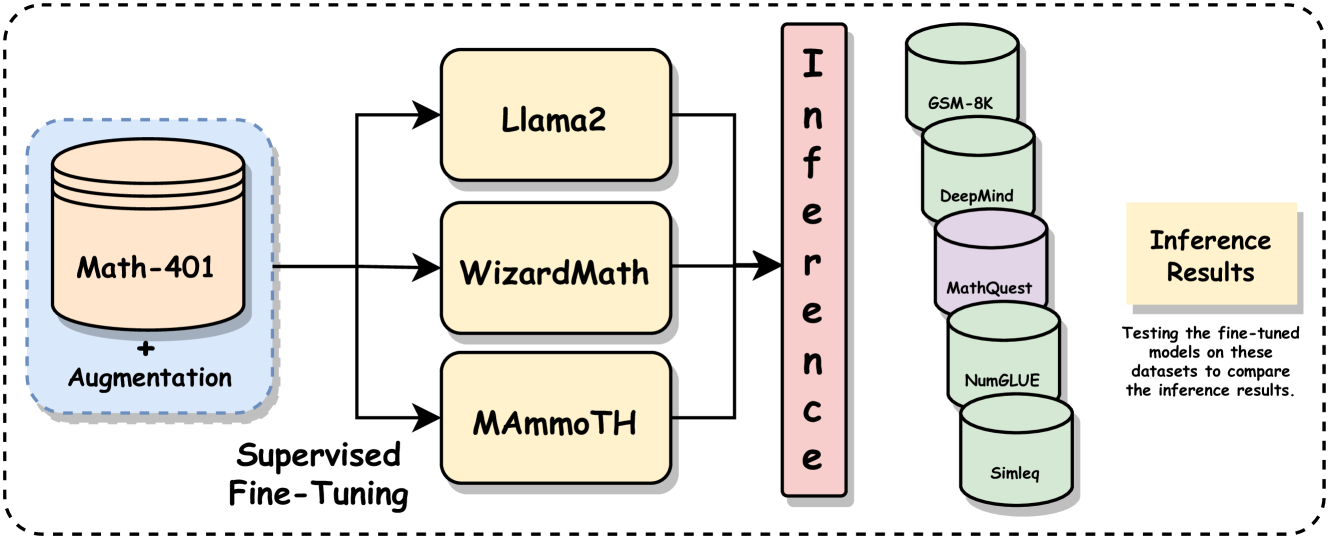
The rapid progress in the field of natural language processing (NLP) systems and the expansion of large language models (LLMs) have opened up numerous opportunities in the field of education and instructional methods. These advancements offer the potential for tailored learning experiences and immediate feedback, all delivered through accessible and cost-effective services. One notable application area for this technological advancement is in the realm of solving mathematical problems. Mathematical problem-solving not only requires the ability to decipher complex problem statements but also the skill to perform precise arithmetic calculations at each step of the problem-solving process. However, the evaluation of the arithmetic capabilities of large language models remains an area that has received relatively little attention. In response, we introduce an extensive mathematics dataset called MathQuest sourced from the 11th and 12th standard Mathematics NCERT textbooks. This dataset encompasses mathematical challenges of varying complexity and covers a wide range of mathematical concepts. Utilizing this dataset, we conduct fine-tuning experiments with three prominent LLMs: LLaMA-2, WizardMath, and MAmmoTH. These fine-tuned models serve as benchmarks for evaluating their performance on our dataset. Our experiments reveal that among the three models, MAmmoTH-13B emerges as the most proficient, achieving the highest level of competence in solving the presented mathematical problems. Consequently, MAmmoTH-13B establishes itself as a robust and dependable benchmark for addressing NCERT mathematics problems.
4/23/2024

Math-LLaVA: Bootstrapping Mathematical Reasoning for Multimodal Large Language Models
Wenhao Shi, Zhiqiang Hu, Yi Bin, Junhua Liu, Yang Yang, See-Kiong Ng, Lidong Bing, Roy Ka-Wei Lee
0
0
Large language models (LLMs) have demonstrated impressive reasoning capabilities, particularly in textual mathematical problem-solving. However, existing open-source image instruction fine-tuning datasets, containing limited question-answer pairs per image, do not fully exploit visual information to enhance the multimodal mathematical reasoning capabilities of Multimodal LLMs (MLLMs). To bridge this gap, we address the lack of high-quality, diverse multimodal mathematical datasets by collecting 40K high-quality images with question-answer pairs from 24 existing datasets and synthesizing 320K new pairs, creating the MathV360K dataset, which enhances both the breadth and depth of multimodal mathematical questions. We introduce Math-LLaVA, a LLaVA-1.5-based model fine-tuned with MathV360K. This novel approach significantly improves the multimodal mathematical reasoning capabilities of LLaVA-1.5, achieving a 19-point increase and comparable performance to GPT-4V on MathVista's minitest split. Furthermore, Math-LLaVA demonstrates enhanced generalizability, showing substantial improvements on the MMMU benchmark. Our research highlights the importance of dataset diversity and synthesis in advancing MLLMs' mathematical reasoning abilities. The code and data are available at: url{https://github.com/HZQ950419/Math-LLaVA}.
6/27/2024

Exploring Mathematical Extrapolation of Large Language Models with Synthetic Data
Haolong Li, Yu Ma, Yinqi Zhang, Chen Ye, Jie Chen
0
0
Large Language Models (LLMs) have shown excellent performance in language understanding, text generation, code synthesis, and many other tasks, while they still struggle in complex multi-step reasoning problems, such as mathematical reasoning. In this paper, through a newly proposed arithmetical puzzle problem, we show that the model can perform well on multi-step reasoning tasks via fine-tuning on high-quality synthetic data. Experimental results with the open-llama-3B model on three different test datasets show that not only the model can reach a zero-shot pass@1 at 0.44 on the in-domain dataset, it also demonstrates certain generalization capabilities on the out-of-domain datasets. Specifically, this paper has designed two out-of-domain datasets in the form of extending the numerical range and the composing components of the arithmetical puzzle problem separately. The fine-tuned models have shown encouraging performance on these two far more difficult tasks with the zero-shot pass@1 at 0.33 and 0.35, respectively.
6/5/2024
💬
InternLM-Math: Open Math Large Language Models Toward Verifiable Reasoning
Huaiyuan Ying, Shuo Zhang, Linyang Li, Zhejian Zhou, Yunfan Shao, Zhaoye Fei, Yichuan Ma, Jiawei Hong, Kuikun Liu, Ziyi Wang, Yudong Wang, Zijian Wu, Shuaibin Li, Fengzhe Zhou, Hongwei Liu, Songyang Zhang, Wenwei Zhang, Hang Yan, Xipeng Qiu, Jiayu Wang, Kai Chen, Dahua Lin
0
0
The math abilities of large language models can represent their abstract reasoning ability. In this paper, we introduce and open-source our math reasoning LLMs InternLM-Math which is continue pre-trained from InternLM2. We unify chain-of-thought reasoning, reward modeling, formal reasoning, data augmentation, and code interpreter in a unified seq2seq format and supervise our model to be a versatile math reasoner, verifier, prover, and augmenter. These abilities can be used to develop the next math LLMs or self-iteration. InternLM-Math obtains open-sourced state-of-the-art performance under the setting of in-context learning, supervised fine-tuning, and code-assisted reasoning in various informal and formal benchmarks including GSM8K, MATH, Hungary math exam, MathBench-ZH, and MiniF2F. Our pre-trained model achieves 30.3 on the MiniF2F test set without fine-tuning. We further explore how to use LEAN to solve math problems and study its performance under the setting of multi-task learning which shows the possibility of using LEAN as a unified platform for solving and proving in math. Our models, codes, and data are released at url{https://github.com/InternLM/InternLM-Math}.
5/27/2024