CARLOR @ Ego4D Step Grounding Challenge: Bayesian temporal-order priors for test time refinement

0

Sign in to get full access
Overview
- This paper explores the use of Bayesian temporal-order priors for test-time refinement in the CARLOR @ Ego4D Step Grounding Challenge.
- The authors propose a method that leverages the natural temporal structure of actions to improve the accuracy of step-level activity grounding.
- By incorporating temporal-order information as a prior during inference, the model can refine its predictions and better align with the expected sequence of steps.
Plain English Explanation
The researchers in this study are working on a computer vision task called "step grounding." This means they're trying to get a computer to understand the individual steps or actions that make up a larger activity, like making a sandwich or washing dishes.
To do this, they've developed a method that uses information about the typical order of these steps as a kind of "prior knowledge" to help the computer make better predictions. For example, the computer might know that the steps for making a sandwich usually go: 1) get bread, 2) spread condiment, 3) add fillings, 4) close sandwich. By incorporating this temporal structure, the computer can refine its predictions and align them better with the expected sequence of steps.
The key insight is that by leveraging the natural order of actions, the computer can improve its ability to correctly identify and localize the individual steps within a larger activity. This could be really helpful for applications like augmented reality, where you want the computer to have a deep understanding of what a person is doing in order to provide relevant assistance or information.
Technical Explanation
The paper introduces a Bayesian temporal-order prior that can be used to refine the step-level predictions of a base activity grounding model during test-time inference. The authors hypothesize that incorporating knowledge about the typical temporal order of steps can help the model better align its predictions with the expected sequence of actions.
Specifically, the method works as follows:
- The base grounding model produces initial step-level predictions for a given video.
- These predictions are then combined with a Bayesian temporal-order prior that encodes the likelihood of different step sequences.
- The model then refines its predictions by maximizing the joint likelihood of the step detections and their temporal ordering.
The temporal-order prior is learned from training data, capturing patterns in the typical order of steps for different activities. This prior is then applied during test-time inference to nudge the model's predictions towards more plausible step sequences.
The authors evaluate their approach on the CARLOR @ Ego4D Step Grounding Challenge dataset, demonstrating improvements in step grounding accuracy compared to a baseline that does not use the temporal-order prior. This suggests the value of incorporating structural knowledge about action sequences to enhance activity understanding in egocentric vision tasks.
Critical Analysis
The key strength of this work is the intuitive idea of leveraging the inherent temporal structure of actions to refine step-level predictions. By incorporating this prior knowledge, the model can better align its outputs with the expected sequence of steps, which is an important aspect of understanding complex activities.
That said, the paper does not explore the limitations or potential failure modes of this approach. For example, it's unclear how the method would perform on atypical or novel action sequences that deviate from the learned temporal priors. There may also be scenarios where the base grounding model makes sufficiently accurate predictions that the refinement step provides minimal benefit.
Additionally, the authors could have provided more insight into how the temporal-order priors are learned and represented. Understanding the characteristics of these priors, such as their specificity, uncertainty, and robustness, would be valuable for assessing the approach's broader applicability.
Overall, the proposed technique is a promising direction for enhancing activity understanding, but further investigation into its limitations and applicability to more diverse scenarios would strengthen the contribution.
Conclusion
This paper presents a novel method for improving step-level activity grounding by incorporating Bayesian temporal-order priors during test-time inference. The key idea is to leverage the natural structure of action sequences to refine the predictions of a base grounding model, aligning them more closely with the expected order of steps.
The authors demonstrate the effectiveness of this approach on the CARLOR @ Ego4D Step Grounding Challenge, suggesting that incorporating knowledge about typical action sequences can enhance the understanding of complex activities in egocentric vision tasks. This work highlights the value of incorporating structural domain knowledge to improve the performance of computer vision systems, which could have important implications for applications like augmented reality and human-robot interaction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CARLOR @ Ego4D Step Grounding Challenge: Bayesian temporal-order priors for test time refinement
Carlos Plou, Lorenzo Mur-Labadia, Ruben Martinez-Cantin, Ana C. Murillo
The goal of the Step Grounding task is to locate temporal boundaries of activities based on natural language descriptions. This technical report introduces a Bayesian-VSLNet to address the challenge of identifying such temporal segments in lengthy, untrimmed egocentric videos. Our model significantly improves upon traditional models by incorporating a novel Bayesian temporal-order prior during inference, enhancing the accuracy of moment predictions. This prior adjusts for cyclic and repetitive actions within videos. Our evaluations demonstrate superior performance over existing methods, achieving state-of-the-art results on the Ego4D Goal-Step dataset with a 35.18 Recall Top-1 at 0.3 IoU and 20.48 Recall Top-1 at 0.5 IoU on the test set.
Read more6/17/2024

0
Beyond Uncertainty: Evidential Deep Learning for Robust Video Temporal Grounding
Kaijing Ma, Haojian Huang, Jin Chen, Haodong Chen, Pengliang Ji, Xianghao Zang, Han Fang, Chao Ban, Hao Sun, Mulin Chen, Xuelong Li
Existing Video Temporal Grounding (VTG) models excel in accuracy but often overlook open-world challenges posed by open-vocabulary queries and untrimmed videos. This leads to unreliable predictions for noisy, corrupted, and out-of-distribution data. Adapting VTG models to dynamically estimate uncertainties based on user input can address this issue. To this end, we introduce SRAM, a robust network module that benefits from a two-stage cross-modal alignment task. More importantly, it integrates Deep Evidential Regression (DER) to explicitly and thoroughly quantify uncertainty during training, thus allowing the model to say I do not know in scenarios beyond its handling capacity. However, the direct application of traditional DER theory and its regularizer reveals structural flaws, leading to unintended constraints in VTG tasks. In response, we develop a simple yet effective Geom-regularizer that enhances the uncertainty learning framework from the ground up. To the best of our knowledge, this marks the first successful attempt of DER in VTG. Our extensive quantitative and qualitative results affirm the effectiveness, robustness, and interpretability of our modules and the uncertainty learning paradigm in VTG tasks. The code will be made available.
Read more8/30/2024

0
Training-free Video Temporal Grounding using Large-scale Pre-trained Models
Minghang Zheng, Xinhao Cai, Qingchao Chen, Yuxin Peng, Yang Liu
Video temporal grounding aims to identify video segments within untrimmed videos that are most relevant to a given natural language query. Existing video temporal localization models rely on specific datasets for training and have high data collection costs, but they exhibit poor generalization capability under the across-dataset and out-of-distribution (OOD) settings. In this paper, we propose a Training-Free Video Temporal Grounding (TFVTG) approach that leverages the ability of pre-trained large models. A naive baseline is to enumerate proposals in the video and use the pre-trained visual language models (VLMs) to select the best proposal according to the vision-language alignment. However, most existing VLMs are trained on image-text pairs or trimmed video clip-text pairs, making it struggle to (1) grasp the relationship and distinguish the temporal boundaries of multiple events within the same video; (2) comprehend and be sensitive to the dynamic transition of events (the transition from one event to another) in the video. To address these issues, we propose leveraging large language models (LLMs) to analyze multiple sub-events contained in the query text and analyze the temporal order and relationships between these events. Secondly, we split a sub-event into dynamic transition and static status parts and propose the dynamic and static scoring functions using VLMs to better evaluate the relevance between the event and the description. Finally, for each sub-event description, we use VLMs to locate the top-k proposals and leverage the order and relationships between sub-events provided by LLMs to filter and integrate these proposals. Our method achieves the best performance on zero-shot video temporal grounding on Charades-STA and ActivityNet Captions datasets without any training and demonstrates better generalization capabilities in cross-dataset and OOD settings.
Read more8/30/2024
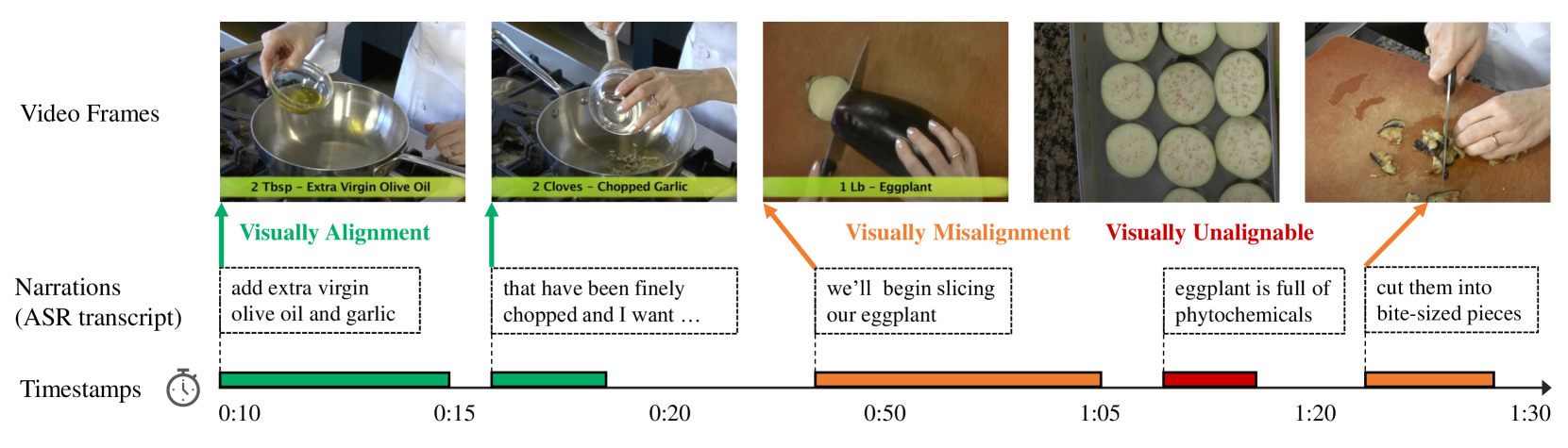
0
Multi-Sentence Grounding for Long-term Instructional Video
Zeqian Li, Qirui Chen, Tengda Han, Ya Zhang, Yanfeng Wang, Weidi Xie
In this paper, we aim to establish an automatic, scalable pipeline for denoising the large-scale instructional dataset and construct a high-quality video-text dataset with multiple descriptive steps supervision, named HowToStep. We make the following contributions: (i) improving the quality of sentences in dataset by upgrading ASR systems to reduce errors from speech recognition and prompting a large language model to transform noisy ASR transcripts into descriptive steps; (ii) proposing a Transformer-based architecture with all texts as queries, iteratively attending to the visual features, to temporally align the generated steps to corresponding video segments. To measure the quality of our curated datasets, we train models for the task of multi-sentence grounding on it, i.e., given a long-form video, and associated multiple sentences, to determine their corresponding timestamps in the video simultaneously, as a result, the model shows superior performance on a series of multi-sentence grounding tasks, surpassing existing state-of-the-art methods by a significant margin on three public benchmarks, namely, 9.0% on HT-Step, 5.1% on HTM-Align and 1.9% on CrossTask. All codes, models, and the resulting dataset have been publicly released.
Read more7/23/2024