Multi-Sentence Grounding for Long-term Instructional Video

0
Sign in to get full access
Overview
- This research paper presents a strong baseline for the task of temporal video-text alignment.
- The baseline model uses a simple but effective approach to align video and text data.
- The model achieves state-of-the-art performance on various benchmark datasets.
Plain English Explanation
The paper describes a method for aligning video and text data over time. This is an important problem in multimodal language models and video understanding.
The key idea is to use a simple but powerful approach to match up the video and text. The model first encodes the video and text separately using neural networks. It then compares the encoded representations to find the best alignment between the two modalities.
This alignment allows the model to ground the text in the corresponding video segments, which is useful for tasks like video summarization and procedural video understanding.
The model achieves state-of-the-art performance, demonstrating that a well-designed baseline can be highly effective for this task.
Technical Explanation
The paper introduces a simple yet strong baseline for temporal video-text alignment. The method first encodes the video and text using separate neural networks. For the video, it uses a 3D convolutional network to extract visual features. For the text, it uses a transformer-based language model to get textual embeddings.
The key innovation is in how the model aligns the video and text. It computes the similarity between each video segment and each text segment, forming a soft alignment matrix. This matrix is then used to pool the video and text representations, producing a single aligned representation.
The authors evaluate the model on several benchmark datasets for video-text alignment. The results show that this simple baseline outperforms more complex state-of-the-art methods, establishing a new high-water mark for this task.
Critical Analysis
The paper provides a strong baseline that is straightforward to implement and achieve high performance. However, it does not explore more advanced alignment mechanisms that could potentially further improve accuracy.
Additionally, the experiments are limited to short video clips, and it's unclear how well the approach would scale to longer, more complex video-text data. There may be opportunities to enhance the model to better handle temporal dynamics and long-range dependencies.
Overall, the research makes a valuable contribution by demonstrating the effectiveness of a simple yet powerful approach for video-text alignment. The insights could inform the development of more sophisticated models in the future.
Conclusion
This paper presents a strong baseline for temporal video-text alignment, a key problem in multimodal learning and video understanding. The model uses a simple yet effective approach to match video and text data, achieving state-of-the-art performance on benchmark datasets.
The findings highlight the importance of well-designed baselines and the potential for straightforward methods to outperform more complex models. This work lays a solid foundation for further advancements in video-language alignment and integration, with applications in areas like video summarization and procedural video understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-Sentence Grounding for Long-term Instructional Video
Zeqian Li, Qirui Chen, Tengda Han, Ya Zhang, Yanfeng Wang, Weidi Xie
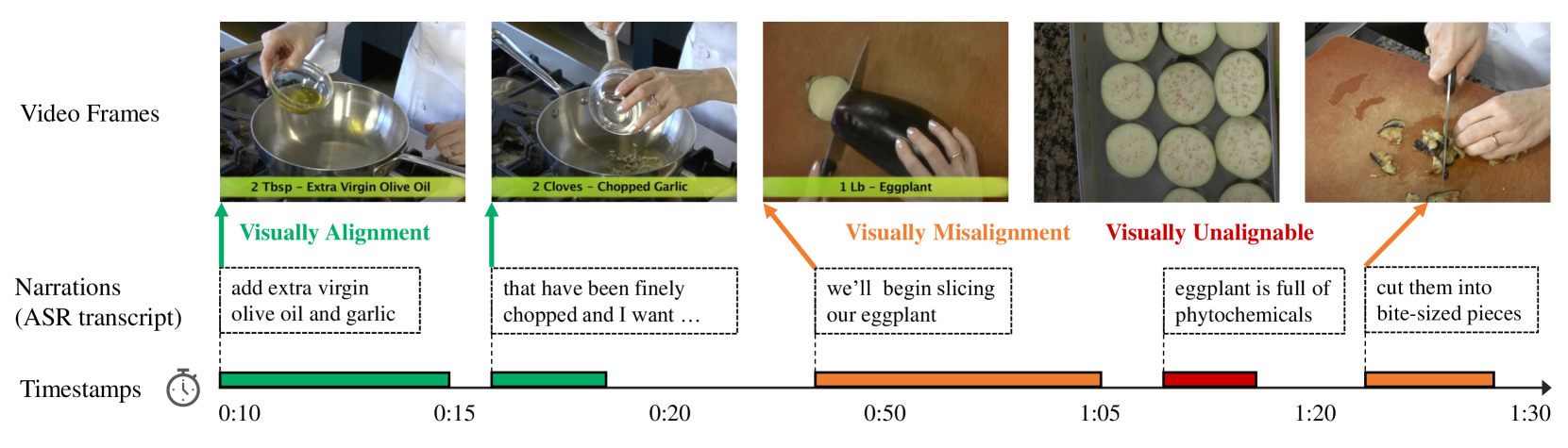
In this paper, we aim to establish an automatic, scalable pipeline for denoising the large-scale instructional dataset and construct a high-quality video-text dataset with multiple descriptive steps supervision, named HowToStep. We make the following contributions: (i) improving the quality of sentences in dataset by upgrading ASR systems to reduce errors from speech recognition and prompting a large language model to transform noisy ASR transcripts into descriptive steps; (ii) proposing a Transformer-based architecture with all texts as queries, iteratively attending to the visual features, to temporally align the generated steps to corresponding video segments. To measure the quality of our curated datasets, we train models for the task of multi-sentence grounding on it, i.e., given a long-form video, and associated multiple sentences, to determine their corresponding timestamps in the video simultaneously, as a result, the model shows superior performance on a series of multi-sentence grounding tasks, surpassing existing state-of-the-art methods by a significant margin on three public benchmarks, namely, 9.0% on HT-Step, 5.1% on HTM-Align and 1.9% on CrossTask. All codes, models, and the resulting dataset have been publicly released.
Read more7/23/2024
0
Multi-sentence Video Grounding for Long Video Generation
Wei Feng, Xin Wang, Hong Chen, Zeyang Zhang, Wenwu Zhu
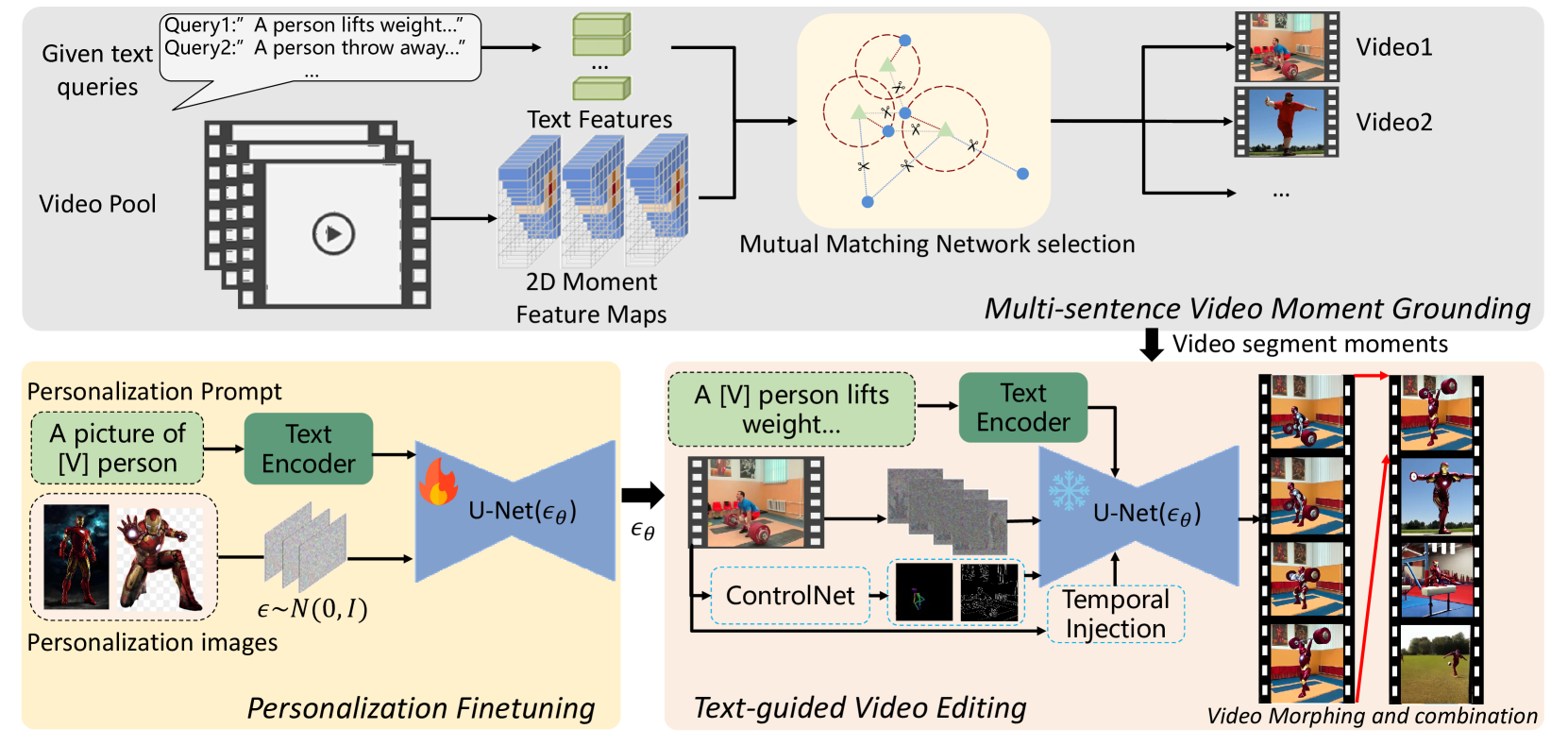
Video generation has witnessed great success recently, but their application in generating long videos still remains challenging due to the difficulty in maintaining the temporal consistency of generated videos and the high memory cost during generation. To tackle the problems, in this paper, we propose a brave and new idea of Multi-sentence Video Grounding for Long Video Generation, connecting the massive video moment retrieval to the video generation task for the first time, providing a new paradigm for long video generation. The method of our work can be summarized as three steps: (i) We design sequential scene text prompts as the queries for video grounding, utilizing the massive video moment retrieval to search for video moment segments that meet the text requirements in the video database. (ii) Based on the source frames of retrieved video moment segments, we adopt video editing methods to create new video content while preserving the temporal consistency of the retrieved video. Since the editing can be conducted segment by segment, and even frame by frame, it largely reduces the memory cost. (iii) We also attempt video morphing and personalized generation methods to improve the subject consistency of long video generation, providing ablation experimental results for the subtasks of long video generation. Our approach seamlessly extends the development in image/video editing, video morphing and personalized generation, and video grounding to the long video generation, offering effective solutions for generating long videos at low memory cost.
Read more7/19/2024

0
SynopGround: A Large-Scale Dataset for Multi-Paragraph Video Grounding from TV Dramas and Synopses
Chaolei Tan, Zihang Lin, Junfu Pu, Zhongang Qi, Wei-Yi Pei, Zhi Qu, Yexin Wang, Ying Shan, Wei-Shi Zheng, Jian-Fang Hu
Video grounding is a fundamental problem in multimodal content understanding, aiming to localize specific natural language queries in an untrimmed video. However, current video grounding datasets merely focus on simple events and are either limited to shorter videos or brief sentences, which hinders the model from evolving toward stronger multimodal understanding capabilities. To address these limitations, we present a large-scale video grounding dataset named SynopGround, in which more than 2800 hours of videos are sourced from popular TV dramas and are paired with accurately localized human-written synopses. Each paragraph in the synopsis serves as a language query and is manually annotated with precise temporal boundaries in the long video. These paragraph queries are tightly correlated to each other and contain a wealth of abstract expressions summarizing video storylines and specific descriptions portraying event details, which enables the model to learn multimodal perception on more intricate concepts over longer context dependencies. Based on the dataset, we further introduce a more complex setting of video grounding dubbed Multi-Paragraph Video Grounding (MPVG), which takes as input multiple paragraphs and a long video for grounding each paragraph query to its temporal interval. In addition, we propose a novel Local-Global Multimodal Reasoner (LGMR) to explicitly model the local-global structures of long-term multimodal inputs for MPVG. Our method provides an effective baseline solution to the multi-paragraph video grounding problem. Extensive experiments verify the proposed model's effectiveness as well as its superiority in long-term multi-paragraph video grounding over prior state-of-the-arts. Dataset and code are publicly available. Project page: https://synopground.github.io/.
Read more8/20/2024

0
Grounded Multi-Hop VideoQA in Long-Form Egocentric Videos
Qirui Chen, Shangzhe Di, Weidi Xie
This paper considers the problem of Multi-Hop Video Question Answering (MH-VidQA) in long-form egocentric videos. This task not only requires to answer visual questions, but also to localize multiple relevant time intervals within the video as visual evidences. We develop an automated pipeline to create multi-hop question-answering pairs with associated temporal evidence, enabling to construct a large-scale dataset for instruction-tuning. To monitor the progress of this new task, we further curate a high-quality benchmark, MultiHop-EgoQA, with careful manual verification and refinement. Experimental results reveal that existing multi-modal systems exhibit inadequate multi-hop grounding and reasoning abilities, resulting in unsatisfactory performance. We then propose a novel architecture, termed as Grounding Scattered Evidence with Large Language Model (GeLM), that enhances multi-modal large language models (MLLMs) by incorporating a grounding module to retrieve temporal evidence from videos using flexible grounding tokens. Trained on our visual instruction data, GeLM demonstrates improved multi-hop grounding and reasoning capabilities, setting a new baseline for this challenging task. Furthermore, when trained on third-person view videos, the same architecture also achieves state-of-the-art performance on the single-hop VidQA benchmark, ActivityNet-RTL, demonstrating its effectiveness.
Read more8/27/2024