Case-based Explainability for Random Forest: Prototypes, Critics, Counter-factuals and Semi-factuals

0
Sign in to get full access
Overview
- This paper presents a case-based explainability approach for random forest models.
- The approach provides four types of explanations: prototypes, critics, counterfactuals, and semi-factuals.
- The explanations aim to help users understand the reasoning behind the model's predictions.
Plain English Explanation
The paper introduces a new way to explain how random forest machine learning models make their predictions. Random forests are a popular type of model that can be used for tasks like classification and regression.
The key idea is to provide four different types of explanations:
-
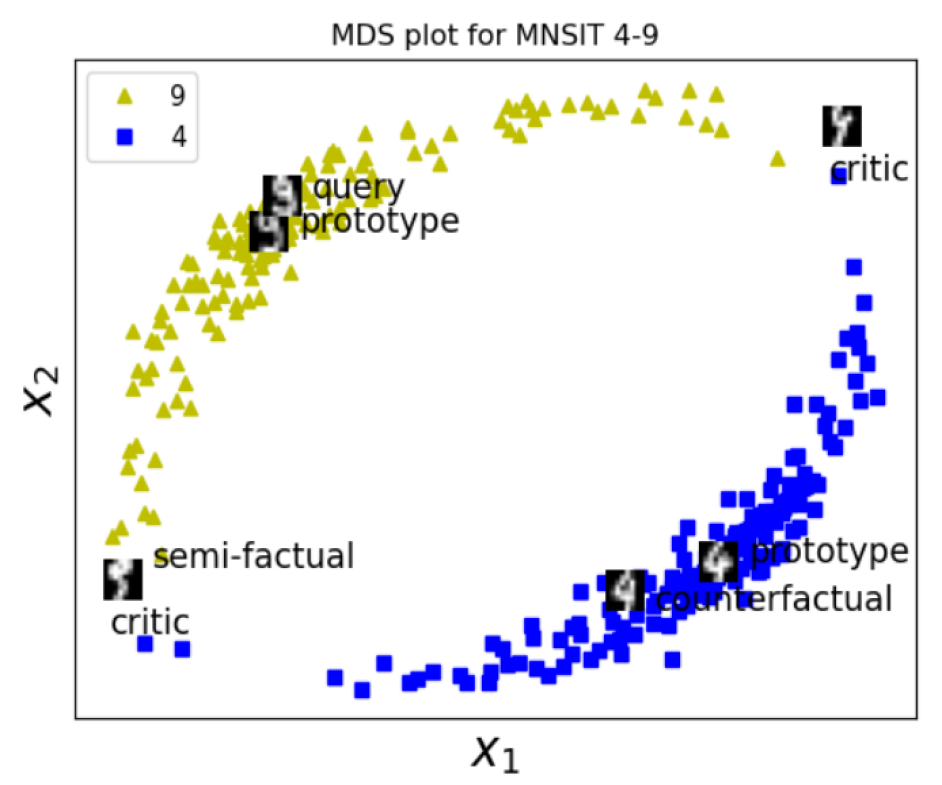
Prototypes: These are examples that are representative of the model's predictions. They show the kind of data the model considers "typical" for a given output.
-
Critics: These are examples that the model struggles with or predicts incorrectly. They highlight the limitations of the model.
-
Counterfactuals: These are examples that are similar to the input data, but would lead to a different prediction. They show how small changes could alter the model's decision.
-
Semi-factuals: These are hypothetical examples that are slightly different from the input data. They demonstrate how the model's prediction might change if certain features were altered.
Together, these four types of explanations give users a more comprehensive understanding of how the random forest model is working. The goal is to make the model's decision-making more transparent and interpretable.
Technical Explanation
The paper proposes a case-based explainability approach for random forest models. The key contributions are:
-
Prototypes: The authors identify the training examples that are most representative of each class or output. These "prototypes" provide insight into the model's notion of typical instances for each prediction.
-
Critics: The authors select training examples that the model struggles with or predicts incorrectly. These "critics" highlight the limitations of the model and the types of instances it has difficulty handling.
-
Counterfactuals: The authors generate examples that are similar to the input data but would lead to a different prediction. These "counterfactuals" demonstrate how small changes could alter the model's decision.
-
Semi-factuals: The authors create hypothetical examples that are slightly different from the input data. These "semi-factuals" show how the model's prediction might change if certain features were altered.
The authors evaluate their approach on several datasets and compare it to other explainability methods. They find that the case-based explanations provide useful insights into the model's reasoning and performance.
Critical Analysis
The paper presents a novel and comprehensive approach to explaining random forest models. The four types of explanations - prototypes, critics, counterfactuals, and semi-factuals - offer a multi-faceted view of the model's decision-making process.
One limitation of the approach is that it may not scale well to more complex models or larger datasets. The process of identifying representative examples and generating counterfactuals could become computationally intensive. Additionally, the explanations are specific to individual predictions, rather than providing global insights about the model.
Further research could explore ways to make the explanation generation more efficient and to extract higher-level insights about the model's behavior. Combining this case-based approach with other explainability techniques, such as feature importance or decision tree visualization, could also provide a richer understanding of the model.
Conclusion
This paper introduces a case-based explainability approach for random forest models that provides four types of explanations: prototypes, critics, counterfactuals, and semi-factuals. These explanations aim to help users understand the reasoning behind the model's predictions and its strengths and limitations.
The approach offers a comprehensive and interpretable way to explain the decision-making of random forest models, which can be valuable for applications where model transparency and accountability are important. While the approach has some limitations in terms of scalability, it represents an important step forward in the field of explainable AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Case-based Explainability for Random Forest: Prototypes, Critics, Counter-factuals and Semi-factuals
Gregory Yampolsky, Dhruv Desai, Mingshu Li, Stefano Pasquali, Dhagash Mehta
The explainability of black-box machine learning algorithms, commonly known as Explainable Artificial Intelligence (XAI), has become crucial for financial and other regulated industrial applications due to regulatory requirements and the need for transparency in business practices. Among the various paradigms of XAI, Explainable Case-Based Reasoning (XCBR) stands out as a pragmatic approach that elucidates the output of a model by referencing actual examples from the data used to train or test the model. Despite its potential, XCBR has been relatively underexplored for many algorithms such as tree-based models until recently. We start by observing that most XCBR methods are defined based on the distance metric learned by the algorithm. By utilizing a recently proposed technique to extract the distance metric learned by Random Forests (RFs), which is both geometry- and accuracy-preserving, we investigate various XCBR methods. These methods amount to identify special points from the training datasets, such as prototypes, critics, counter-factuals, and semi-factuals, to explain the predictions for a given query of the RF. We evaluate these special points using various evaluation metrics to assess their explanatory power and effectiveness.
Read more8/14/2024
🎯
0
Benchmarking Instance-Centric Counterfactual Algorithms for XAI: From White Box to Black Bo
Catarina Moreira, Yu-Liang Chou, Chihcheng Hsieh, Chun Ouyang, Joaquim Jorge, Jo~ao Madeiras Pereira
This study investigates the impact of machine learning models on the generation of counterfactual explanations by conducting a benchmark evaluation over three different types of models: a decision tree (fully transparent, interpretable, white-box model), a random forest (semi-interpretable, grey-box model), and a neural network (fully opaque, black-box model). We tested the counterfactual generation process using four algorithms (DiCE, WatcherCF, prototype, and GrowingSpheresCF) in the literature in 25 different datasets. Our findings indicate that: (1) Different machine learning models have little impact on the generation of counterfactual explanations; (2) Counterfactual algorithms based uniquely on proximity loss functions are not actionable and will not provide meaningful explanations; (3) One cannot have meaningful evaluation results without guaranteeing plausibility in the counterfactual generation. Algorithms that do not consider plausibility in their internal mechanisms will lead to biased and unreliable conclusions if evaluated with the current state-of-the-art metrics; (4) A counterfactual inspection analysis is strongly recommended to ensure a robust examination of counterfactual explanations and the potential identification of biases.
Read more6/12/2024
🔮
0
Counterfactual Explanations of Black-box Machine Learning Models using Causal Discovery with Applications to Credit Rating
Daisuke Takahashi, Shohei Shimizu, Takuma Tanaka
Explainable artificial intelligence (XAI) has helped elucidate the internal mechanisms of machine learning algorithms, bolstering their reliability by demonstrating the basis of their predictions. Several XAI models consider causal relationships to explain models by examining the input-output relationships of prediction models and the dependencies between features. The majority of these models have been based their explanations on counterfactual probabilities, assuming that the causal graph is known. However, this assumption complicates the application of such models to real data, given that the causal relationships between features are unknown in most cases. Thus, this study proposed a novel XAI framework that relaxed the constraint that the causal graph is known. This framework leveraged counterfactual probabilities and additional prior information on causal structure, facilitating the integration of a causal graph estimated through causal discovery methods and a black-box classification model. Furthermore, explanatory scores were estimated based on counterfactual probabilities. Numerical experiments conducted employing artificial data confirmed the possibility of estimating the explanatory score more accurately than in the absence of a causal graph. Finally, as an application to real data, we constructed a classification model of credit ratings assigned by Shiga Bank, Shiga prefecture, Japan. We demonstrated the effectiveness of the proposed method in cases where the causal graph is unknown.
Read more4/30/2024

0
Explainable bank failure prediction models: Counterfactual explanations to reduce the failure risk
Seyma Gunonu, Gizem Altun, Mustafa Cavus
The accuracy and understandability of bank failure prediction models are crucial. While interpretable models like logistic regression are favored for their explainability, complex models such as random forest, support vector machines, and deep learning offer higher predictive performance but lower explainability. These models, known as black boxes, make it difficult to derive actionable insights. To address this challenge, using counterfactual explanations is suggested. These explanations demonstrate how changes in input variables can alter the model output and suggest ways to mitigate bank failure risk. The key challenge lies in selecting the most effective method for generating useful counterfactuals, which should demonstrate validity, proximity, sparsity, and plausibility. The paper evaluates several counterfactual generation methods: WhatIf, Multi Objective, and Nearest Instance Counterfactual Explanation, and also explores resampling methods like undersampling, oversampling, SMOTE, and the cost sensitive approach to address data imbalance in bank failure prediction in the US. The results indicate that the Nearest Instance Counterfactual Explanation method yields higher quality counterfactual explanations, mainly using the cost sensitive approach. Overall, the Multi Objective Counterfactual and Nearest Instance Counterfactual Explanation methods outperform others regarding validity, proximity, and sparsity metrics, with the cost sensitive approach providing the most desirable counterfactual explanations. These findings highlight the variability in the performance of counterfactual generation methods across different balancing strategies and machine learning models, offering valuable strategies to enhance the utility of black box bank failure prediction models.
Read more7/23/2024