CATGNN: Cost-Efficient and Scalable Distributed Training for Graph Neural Networks

0

Sign in to get full access
Overview
• CATGNN is a cost-efficient and scalable distributed training approach for Graph Neural Networks (GNNs) • It addresses the challenge of high memory and compute requirements of GNN training on large graphs • The proposed method leverages cooperative training and asynchronous updates to achieve better performance at lower computational cost
Plain English Explanation
CATGNN is a new way to train large graph neural networks more efficiently. Graph neural networks are a type of machine learning model that can work with data represented as interconnected nodes, like social networks or transportation systems. But training these models on big, complex graphs requires a lot of computing power and memory, which can be expensive.
CATGNN tackles this problem by using a cooperative training approach. Instead of having one central computer do all the work, CATGNN splits the training across multiple computers that work together asynchronously. This allows the training to happen faster and more cost-effectively, without losing performance compared to traditional training methods.
The key ideas behind CATGNN are:
- Splitting the graph data and training computations across multiple machines
- Allowing those machines to update the model parameters independently and asynchronously, without waiting for each other
- Carefully coordinating the updates to ensure the model converges properly, even with this distributed, asynchronous approach
By using these techniques, CATGNN can train large, complex graph neural networks more efficiently, requiring less computing power and lower costs. This makes these powerful models more accessible for real-world applications.
Technical Explanation
CATGNN is a distributed training framework for Graph Neural Networks (GNNs) that aims to reduce the high memory and compute requirements of training on large graphs. It achieves this through a cooperative and asynchronous training approach.
The key components of CATGNN are:
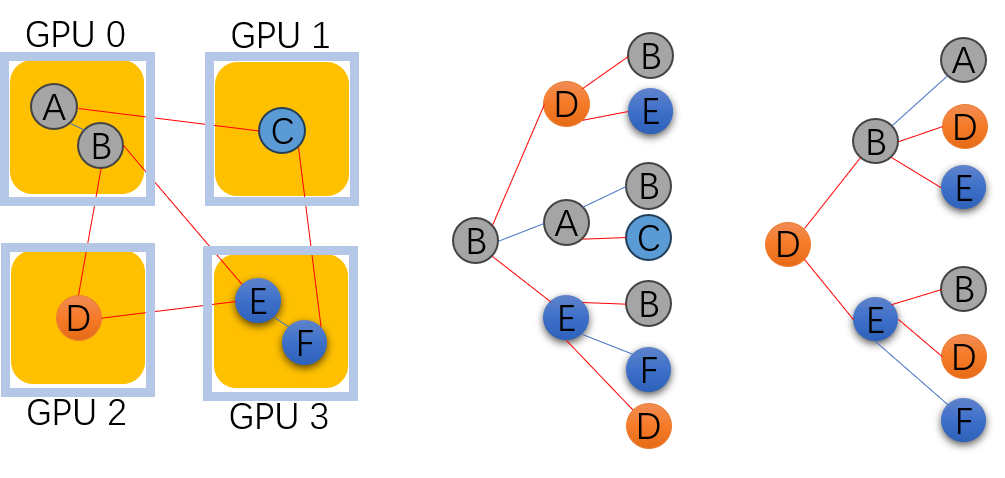
- Graph Partitioning: The input graph is partitioned across multiple worker machines, allowing the training computations to be distributed.
- Asynchronous Updates: Each worker machine updates the model parameters independently, without waiting for synchronization with other workers. This avoids the bottleneck of a central coordinator.
- Cooperative Training: CATGNN uses a cooperative training scheme, where workers share their local model updates with each other in an asynchronous manner. This helps the model converge effectively despite the distributed and asynchronous nature of the training.
CATGNN is designed to be cost-efficient and scalable, enabling GNN training on large graphs without sacrificing model performance. The authors evaluate CATGNN on several benchmark datasets and show significant improvements in training time and computational cost compared to state-of-the-art distributed GNN training approaches.
Critical Analysis
The CATGNN paper presents a novel and promising approach to address the challenges of training GNNs on large graphs. The asynchronous and cooperative training scheme is an innovative solution to the high memory and compute requirements of centralized GNN training.
However, the paper does not extensively explore the limitations of CATGNN. For example, it is unclear how CATGNN would perform on highly skewed or imbalanced graph partitions, which could impact the convergence of the distributed training. Additionally, the paper does not discuss the potential communication overhead or synchronization costs associated with the asynchronous parameter updates across workers.
Further research could investigate the robustness of CATGNN to different graph structures and partitioning strategies, as well as explore techniques to minimize the communication costs. Evaluating CATGNN on a wider range of real-world graph datasets and comparing it to a broader set of distributed GNN training baselines could also provide additional insights.
Conclusion
CATGNN offers a cost-efficient and scalable distributed training approach for Graph Neural Networks, which is a crucial advancement given the growing importance of GNNs in domains like social network analysis, recommendation systems, and drug discovery. By leveraging cooperative and asynchronous training, CATGNN can effectively train GNNs on large-scale graphs without the prohibitive memory and compute requirements of centralized training.
While the paper presents promising results, further research is needed to fully understand the limitations and explore potential improvements to the CATGNN framework. Nonetheless, this work represents an important step forward in making powerful GNN models more accessible and practical for real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CATGNN: Cost-Efficient and Scalable Distributed Training for Graph Neural Networks
Xin Huang, Weipeng Zhuo, Minh Phu Vuong, Shiju Li, Jongryool Kim, Bradley Rees, Chul-Ho Lee
Graph neural networks have been shown successful in recent years. While different GNN architectures and training systems have been developed, GNN training on large-scale real-world graphs still remains challenging. Existing distributed systems load the entire graph in memory for graph partitioning, requiring a huge memory space to process large graphs and thus hindering GNN training on such large graphs using commodity workstations. In this paper, we propose CATGNN, a cost-efficient and scalable distributed GNN training system which focuses on scaling GNN training to billion-scale or larger graphs under limited computational resources. Among other features, it takes a stream of edges as input, instead of loading the entire graph in memory, for partitioning. We also propose a novel streaming partitioning algorithm named SPRING for distributed GNN training. We verify the correctness and effectiveness of CATGNN with SPRING on 16 open datasets. In particular, we demonstrate that CATGNN can handle the largest publicly available dataset with limited memory, which would have been infeasible without increasing the memory space. SPRING also outperforms state-of-the-art partitioning algorithms significantly, with a 50% reduction in replication factor on average.
Read more4/4/2024
🧠
0
An Experimental Comparison of Partitioning Strategies for Distributed Graph Neural Network Training
Nikolai Merkel, Daniel Stoll, Ruben Mayer, Hans-Arno Jacobsen
Recently, graph neural networks (GNNs) have gained much attention as a growing area of deep learning capable of learning on graph-structured data. However, the computational and memory requirements for training GNNs on large-scale graphs make it necessary to distribute the training. A prerequisite for distributed GNN training is to partition the input graph into smaller parts that are distributed among multiple machines of a compute cluster. Although graph partitioning has been studied with regard to graph analytics and graph databases, its effect on GNN training performance is largely unexplored. As a consequence, it is unclear whether investing computational efforts into high-quality graph partitioning would pay off in GNN training scenarios. In this paper, we study the effectiveness of graph partitioning for distributed GNN training. Our study aims to understand how different factors such as GNN parameters, mini-batch size, graph type, features size, and scale-out factor influence the effectiveness of graph partitioning. We conduct experiments with two different GNN systems using vertex and edge partitioning. We found that high-quality graph partitioning is a very effective optimization to speed up GNN training and to reduce memory consumption. Furthermore, our results show that invested partitioning time can quickly be amortized by reduced GNN training time, making it a relevant optimization for most GNN scenarios. Compared to research on distributed graph processing, our study reveals that graph partitioning plays an even more significant role in distributed GNN training, which motivates further research on the graph partitioning problem.
Read more8/13/2024
🏋️
0
GraNNDis: Efficient Unified Distributed Training Framework for Deep GNNs on Large Clusters
Jaeyong Song, Hongsun Jang, Jaewon Jung, Youngsok Kim, Jinho Lee
Graph neural networks (GNNs) are one of the rapidly growing fields within deep learning. While many distributed GNN training frameworks have been proposed to increase the training throughput, they face three limitations when applied to multi-server clusters. 1) They suffer from an inter-server communication bottleneck because they do not consider the inter-/intra-server bandwidth gap, a representative characteristic of multi-server clusters. 2) Redundant memory usage and computation hinder the scalability of the distributed frameworks. 3) Sampling methods, de facto standard in mini-batch training, incur unnecessary errors in multi-server clusters. We found that these limitations can be addressed by exploiting the characteristics of multi-server clusters. Here, we propose GraNNDis, a fast distributed GNN training framework for multi-server clusters. Firstly, we present Flexible Preloading, which preloads the essential vertex dependencies server-wise to reduce the low-bandwidth inter-server communications. Secondly, we introduce Cooperative Batching, which enables memory-efficient, less redundant mini-batch training by utilizing high-bandwidth intra-server communications. Thirdly, we propose Expansion-aware Sampling, a cluster-aware sampling method, which samples the edges that affect the system speedup. As sampling the intra-server dependencies does not contribute much to the speedup as they are communicated through fast intra-server links, it only targets a server boundary to be sampled. Lastly, we introduce One-Hop Graph Masking, a computation and communication structure to realize the above methods in multi-server environments. We evaluated GraNNDis on multi-server clusters, and it provided significant speedup over the state-of-the-art distributed GNN training frameworks. GraNNDis is open-sourced at https://github.com/AIS-SNU/GraNNDis_Artifact to facilitate its use.
Read more8/14/2024
0
CDFGNN: a Systematic Design of Cache-based Distributed Full-Batch Graph Neural Network Training with Communication Reduction
Shuai Zhang, Zite Jiang, Haihang You
Graph neural network training is mainly categorized into mini-batch and full-batch training methods. The mini-batch training method samples subgraphs from the original graph in each iteration. This sampling operation introduces extra computation overhead and reduces the training accuracy. Meanwhile, the full-batch training method calculates the features and corresponding gradients of all vertices in each iteration, and therefore has higher convergence accuracy. However, in the distributed cluster, frequent remote accesses of vertex features and gradients lead to huge communication overhead, thus restricting the overall training efficiency. In this paper, we introduce the cached-based distributed full-batch graph neural network training framework (CDFGNN). We propose the adaptive cache mechanism to reduce the remote vertex access by caching the historical features and gradients of neighbor vertices. Besides, we further optimize the communication overhead by quantifying the messages and designing the graph partition algorithm for the hierarchical communication architecture. Experiments show that the adaptive cache mechanism reduces remote vertex accesses by 63.14% on average. Combined with communication quantization and hierarchical GP algorithm, CDFGNN outperforms the state-of-the-art distributed full-batch training frameworks by 30.39% in our experiments. Our results indicate that CDFGNN has great potential in accelerating distributed full-batch GNN training tasks.
Read more8/2/2024