Cauchy-Schwarz Divergence Information Bottleneck for Regression
2404.17951
0
0
↗️
Abstract
The information bottleneck (IB) approach is popular to improve the generalization, robustness and explainability of deep neural networks. Essentially, it aims to find a minimum sufficient representation $mathbf{t}$ by striking a trade-off between a compression term $I(mathbf{x};mathbf{t})$ and a prediction term $I(y;mathbf{t})$, where $I(cdot;cdot)$ refers to the mutual information (MI). MI is for the IB for the most part expressed in terms of the Kullback-Leibler (KL) divergence, which in the regression case corresponds to prediction based on mean squared error (MSE) loss with Gaussian assumption and compression approximated by variational inference. In this paper, we study the IB principle for the regression problem and develop a new way to parameterize the IB with deep neural networks by exploiting favorable properties of the Cauchy-Schwarz (CS) divergence. By doing so, we move away from MSE-based regression and ease estimation by avoiding variational approximations or distributional assumptions. We investigate the improved generalization ability of our proposed CS-IB and demonstrate strong adversarial robustness guarantees. We demonstrate its superior performance on six real-world regression tasks over other popular deep IB approaches. We additionally observe that the solutions discovered by CS-IB always achieve the best trade-off between prediction accuracy and compression ratio in the information plane. The code is available at url{https://github.com/SJYuCNEL/Cauchy-Schwarz-Information-Bottleneck}.
Create account to get full access
Overview
- The paper introduces a new approach to the Information Bottleneck (IB) principle for deep neural networks.
- The IB aims to find a representation that balances compression and prediction, using mutual information as the objective.
- The authors propose a method based on the Cauchy-Schwarz (CS) divergence, which avoids the need for mean squared error (MSE) regression and variational approximations.
- The proposed CS-IB method demonstrates improved generalization, adversarial robustness, and performance on real-world regression tasks.
Plain English Explanation
The Information Bottleneck (IB) is a popular technique used to improve the performance and interpretability of deep neural networks. The basic idea is to find a compact representation of the input data that still contains the most important information needed to make accurate predictions.
The authors of this paper have developed a new way to implement the IB using deep neural networks. Instead of the traditional approach, which relies on mean squared error (MSE) and variational inference, they use a different mathematical measure called the Cauchy-Schwarz (CS) divergence. This allows them to avoid some of the limitations of the standard IB method.
The key benefit of the CS-IB approach is that it can learn better representations of the data, leading to improved generalization and stronger adversarial robustness. The authors demonstrate that their method outperforms other deep IB techniques on a variety of real-world regression tasks.
Importantly, the solutions found by CS-IB also achieve the best trade-off between prediction accuracy and data compression, as visualized in the "information plane." This suggests that the CS-IB approach is effectively capturing the most relevant information in a compact form.
Technical Explanation
The key innovation of this paper is the use of the Cauchy-Schwarz (CS) divergence instead of the more commonly used Kullback-Leibler (KL) divergence to implement the Information Bottleneck (IB) principle.
Traditionally, the IB has been formulated in terms of the mutual information (MI) between the input and the learned representation, and the MI between the representation and the target variable. This MI is often expressed using the KL divergence, which corresponds to MSE-based regression with a Gaussian assumption.
The authors show that by using the CS divergence instead, they can avoid the need for MSE regression and variational approximations. This leads to improved generalization and adversarial robustness compared to other deep IB approaches.
Experimentally, the authors demonstrate the superior performance of their CS-IB method on six real-world regression tasks. They also observe that the solutions discovered by CS-IB consistently achieve the best trade-off between prediction accuracy and compression ratio in the information plane.
Critical Analysis
The authors provide a thorough evaluation of their CS-IB method, demonstrating its advantages over other deep IB techniques. However, the paper does not address some potential limitations or areas for further research.
For example, the authors do not discuss the computational complexity of their approach compared to the standard IB method. The use of the CS divergence may introduce additional computational overhead, which could be a concern for large-scale or real-time applications.
Additionally, the paper focuses on regression tasks, but it is unclear how well the CS-IB method would perform on classification problems. Further investigation into its applicability to a broader range of tasks would be valuable.
Finally, the authors do not explore the interpretability of the learned representations, which is often a key goal of the IB principle. Analyzing the properties and characteristics of the CS-IB representations could provide additional insights into their advantages.
Conclusion
This paper presents a novel approach to the Information Bottleneck principle for deep neural networks, using the Cauchy-Schwarz divergence instead of the traditional Kullback-Leibler divergence. The proposed CS-IB method demonstrates improved generalization, adversarial robustness, and performance on real-world regression tasks compared to other deep IB techniques.
The key benefit of the CS-IB approach is its ability to learn more effective representations of the data, as evidenced by the optimal trade-offs between prediction accuracy and data compression found in the information plane. This suggests that the CS-IB method is effectively capturing the most relevant information in a compact form, which could have important implications for the interpretability and reliability of deep neural networks.
Overall, this research represents a significant advancement in the field of Information Bottleneck and its application to deep learning, with the potential to enhance the generalization, robustness, and transparency of AI systems in a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
Information Bottleneck Analysis of Deep Neural Networks via Lossy Compression
Ivan Butakov, Alexander Tolmachev, Sofia Malanchuk, Anna Neopryatnaya, Alexey Frolov, Kirill Andreev
0
0
The Information Bottleneck (IB) principle offers an information-theoretic framework for analyzing the training process of deep neural networks (DNNs). Its essence lies in tracking the dynamics of two mutual information (MI) values: between the hidden layer output and the DNN input/target. According to the hypothesis put forth by Shwartz-Ziv & Tishby (2017), the training process consists of two distinct phases: fitting and compression. The latter phase is believed to account for the good generalization performance exhibited by DNNs. Due to the challenging nature of estimating MI between high-dimensional random vectors, this hypothesis was only partially verified for NNs of tiny sizes or specific types, such as quantized NNs. In this paper, we introduce a framework for conducting IB analysis of general NNs. Our approach leverages the stochastic NN method proposed by Goldfeld et al. (2019) and incorporates a compression step to overcome the obstacles associated with high dimensionality. In other words, we estimate the MI between the compressed representations of high-dimensional random vectors. The proposed method is supported by both theoretical and practical justifications. Notably, we demonstrate the accuracy of our estimator through synthetic experiments featuring predefined MI values and comparison with MINE (Belghazi et al., 2018). Finally, we perform IB analysis on a close-to-real-scale convolutional DNN, which reveals new features of the MI dynamics.
5/10/2024
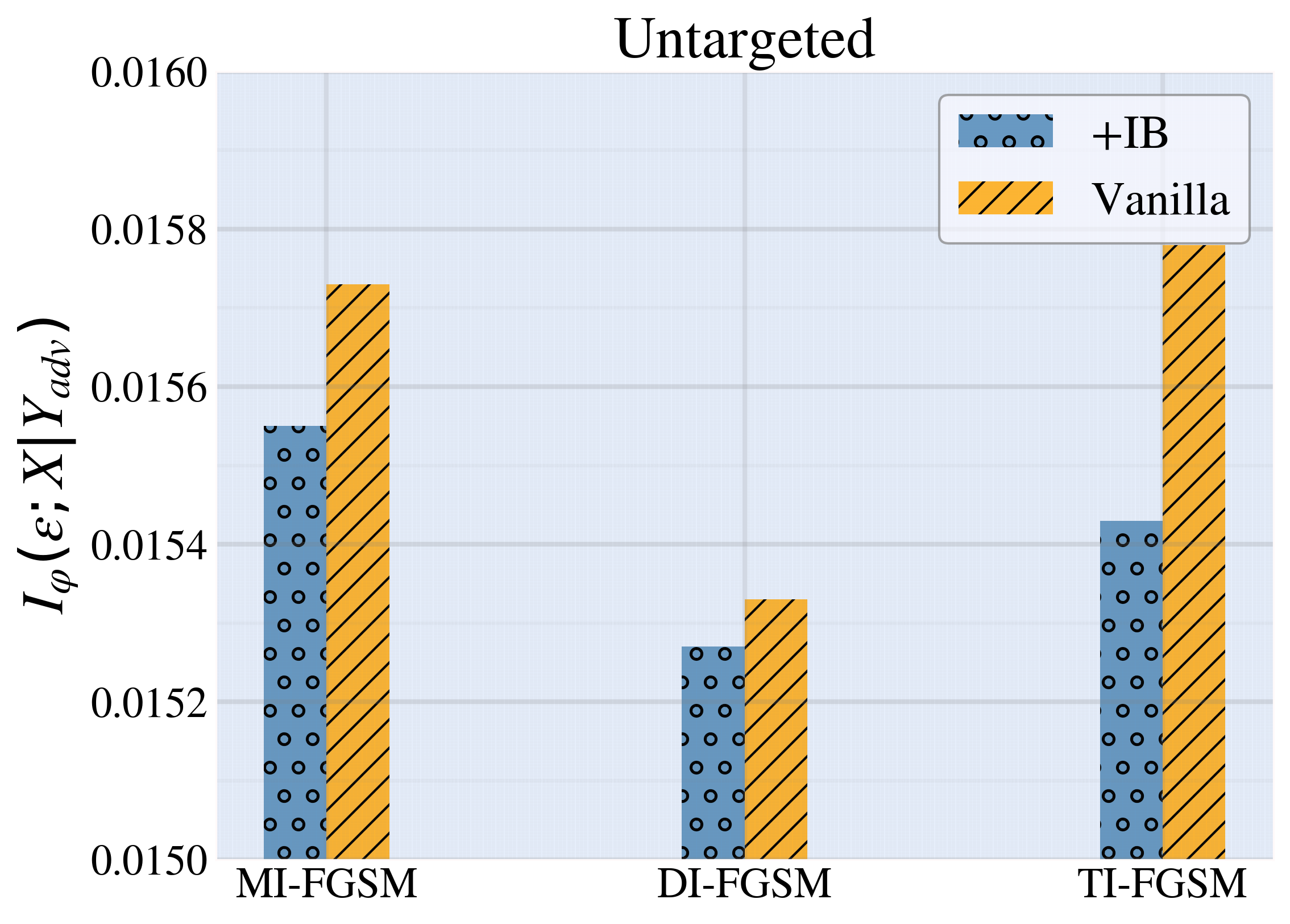
Enhancing Adversarial Transferability via Information Bottleneck Constraints
Biqing Qi, Junqi Gao, Jianxing Liu, Ligang Wu, Bowen Zhou
0
0
From the perspective of information bottleneck (IB) theory, we propose a novel framework for performing black-box transferable adversarial attacks named IBTA, which leverages advancements in invariant features. Intuitively, diminishing the reliance of adversarial perturbations on the original data, under equivalent attack performance constraints, encourages a greater reliance on invariant features that contributes most to classification, thereby enhancing the transferability of adversarial attacks. Building on this motivation, we redefine the optimization of transferable attacks using a novel theoretical framework that centers around IB. Specifically, to overcome the challenge of unoptimizable mutual information, we propose a simple and efficient mutual information lower bound (MILB) for approximating computation. Moreover, to quantitatively evaluate mutual information, we utilize the Mutual Information Neural Estimator (MINE) to perform a thorough analysis. Our experiments on the ImageNet dataset well demonstrate the efficiency and scalability of IBTA and derived MILB. Our code is available at https://github.com/Biqing-Qi/Enhancing-Adversarial-Transferability-via-Information-Bottleneck-Constraints.
6/11/2024
🌐
IB-AdCSCNet:Adaptive Convolutional Sparse Coding Network Driven by Information Bottleneck
He Zou, Meng'en Qin, Yu Song, Xiaohui Yang
0
0
In the realm of neural network models, the perpetual challenge remains in retaining task-relevant information while effectively discarding redundant data during propagation. In this paper, we introduce IB-AdCSCNet, a deep learning model grounded in information bottleneck theory. IB-AdCSCNet seamlessly integrates the information bottleneck trade-off strategy into deep networks by dynamically adjusting the trade-off hyperparameter $lambda$ through gradient descent, updating it within the FISTA(Fast Iterative Shrinkage-Thresholding Algorithm ) framework. By optimizing the compressive excitation loss function induced by the information bottleneck principle, IB-AdCSCNet achieves an optimal balance between compression and fitting at a global level, approximating the globally optimal representation feature. This information bottleneck trade-off strategy driven by downstream tasks not only helps to learn effective features of the data, but also improves the generalization of the model. This study's contribution lies in presenting a model with consistent performance and offering a fresh perspective on merging deep learning with sparse representation theory, grounded in the information bottleneck concept. Experimental results on CIFAR-10 and CIFAR-100 datasets demonstrate that IB-AdCSCNet not only matches the performance of deep residual convolutional networks but also outperforms them when handling corrupted data. Through the inference of the IB trade-off, the model's robustness is notably enhanced.
5/24/2024
🤔
Towards understanding neural collapse in supervised contrastive learning with the information bottleneck method
Siwei Wang, Stephanie E Palmer
0
0
Neural collapse describes the geometry of activation in the final layer of a deep neural network when it is trained beyond performance plateaus. Open questions include whether neural collapse leads to better generalization and, if so, why and how training beyond the plateau helps. We model neural collapse as an information bottleneck (IB) problem in order to investigate whether such a compact representation exists and discover its connection to generalization. We demonstrate that neural collapse leads to good generalization specifically when it approaches an optimal IB solution of the classification problem. Recent research has shown that two deep neural networks independently trained with the same contrastive loss objective are linearly identifiable, meaning that the resulting representations are equivalent up to a matrix transformation. We leverage linear identifiability to approximate an analytical solution of the IB problem. This approximation demonstrates that when class means exhibit $K$-simplex Equiangular Tight Frame (ETF) behavior (e.g., $K$=10 for CIFAR10 and $K$=100 for CIFAR100), they coincide with the critical phase transitions of the corresponding IB problem. The performance plateau occurs once the optimal solution for the IB problem includes all of these phase transitions. We also show that the resulting $K$-simplex ETF can be packed into a $K$-dimensional Gaussian distribution using supervised contrastive learning with a ResNet50 backbone. This geometry suggests that the $K$-simplex ETF learned by supervised contrastive learning approximates the optimal features for source coding. Hence, there is a direct correspondence between optimal IB solutions and generalization in contrastive learning.
6/28/2024