Information-Theoretic Generalization Bounds for Deep Neural Networks
2404.03176
0
0

Abstract
Deep neural networks (DNNs) exhibit an exceptional capacity for generalization in practical applications. This work aims to capture the effect and benefits of depth for supervised learning via information-theoretic generalization bounds. We first derive two hierarchical bounds on the generalization error in terms of the Kullback-Leibler (KL) divergence or the 1-Wasserstein distance between the train and test distributions of the network internal representations. The KL divergence bound shrinks as the layer index increases, while the Wasserstein bound implies the existence of a layer that serves as a generalization funnel, which attains a minimal 1-Wasserstein distance. Analytic expressions for both bounds are derived under the setting of binary Gaussian classification with linear DNNs. To quantify the contraction of the relevant information measures when moving deeper into the network, we analyze the strong data processing inequality (SDPI) coefficient between consecutive layers of three regularized DNN models: Dropout, DropConnect, and Gaussian noise injection. This enables refining our generalization bounds to capture the contraction as a function of the network architecture parameters. Specializing our results to DNNs with a finite parameter space and the Gibbs algorithm reveals that deeper yet narrower network architectures generalize better in those examples, although how broadly this statement applies remains a question.
Create account to get full access
Overview
- This paper proposes a new information-theoretic framework for analyzing the generalization performance of deep neural networks.
- The authors derive theoretical bounds on the generalization error of DNNs that depend on the mutual information between the network's internal representations and the input/output data.
- These bounds provide insights into how the network's architecture, training procedure, and other factors affect its ability to generalize beyond the training data.
Plain English Explanation
The paper is exploring how well deep neural networks (DNNs) can take what they've learned from training data and apply it to new, unseen data. This is called the network's "generalization" ability. The authors developed a new way of looking at this problem using information theory.
Imagine you have a neural network that's been trained to recognize different types of animals in images. The network has learned to extract certain features or "representations" from the images that allow it to distinguish between, say, dogs and cats. The key insight is that the more information the network retains about the input images and their labels, the better it will be able to generalize to new images.
The paper mathematically quantifies this idea using a concept called "mutual information" - a measure of how much information two variables (like the network's internal representations and the input/output data) share. The authors show that by bounding the mutual information, you can also bound the generalization error of the network. This provides a principled way to understand how factors like the network architecture, training procedure, and dataset can impact generalization.
Technical Explanation
The core of the paper is the derivation of new generalization bounds for deep neural networks based on information-theoretic quantities. Specifically, the authors show that the generalization error of a DNN can be upper bounded by a term that depends on the mutual information between the network's internal representations and the input/output data.
This mutual information term captures the amount of information the network is retaining about the training data, which is a key driver of its ability to generalize. The authors demonstrate that this bound can be further decomposed into terms corresponding to the network architecture, the training procedure, and properties of the data distribution.
Through this analysis, the paper provides insights into how design choices for DNNs, such as the number and size of layers, the choice of activation functions, and the training hyperparameters, can impact generalization performance. The authors validate their theoretical findings through experiments on standard benchmarks.
Critical Analysis
The proposed information-theoretic framework offers a principled approach to analyzing DNN generalization that goes beyond traditional complexity-based bounds. By focusing on the mutual information between internal representations and data, the authors capture more nuanced aspects of the learning process compared to simpler notions of model complexity.
That said, the theoretical bounds derived in the paper, while insightful, may not be tight enough to provide quantitatively accurate predictions of generalization error in practice. The authors acknowledge this limitation and suggest that the bounds could potentially be improved through further refinements of the analysis.
Additionally, the paper does not address how the information-theoretic perspective could be leveraged to directly guide the design and optimization of neural network architectures and training procedures. Extending the theory to enable more practical applications would be an interesting direction for future work.
Overall, this paper represents an important step forward in developing a deeper, more fundamental understanding of generalization in deep learning. The information-theoretic approach offers a promising avenue for further advancing the theoretical foundations of this rapidly evolving field.
Conclusion
This paper presents a novel information-theoretic framework for analyzing the generalization performance of deep neural networks. By relating the network's generalization error to the mutual information between its internal representations and the input/output data, the authors derive theoretical bounds that provide insights into how architectural choices, training procedures, and dataset properties can impact a DNN's ability to generalize.
While the bounds may not be tight enough for quantitative predictions, the information-theoretic perspective offers a principled way to reason about generalization that goes beyond traditional complexity-based analyses. This work represents an important step towards a deeper, more fundamental understanding of deep learning, with potential implications for the design of more robust and generalizable neural network models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Slicing Mutual Information Generalization Bounds for Neural Networks
Kimia Nadjahi, Kristjan Greenewald, Rickard Bruel Gabrielsson, Justin Solomon
0
0
The ability of machine learning (ML) algorithms to generalize well to unseen data has been studied through the lens of information theory, by bounding the generalization error with the input-output mutual information (MI), i.e., the MI between the training data and the learned hypothesis. Yet, these bounds have limited practicality for modern ML applications (e.g., deep learning), due to the difficulty of evaluating MI in high dimensions. Motivated by recent findings on the compressibility of neural networks, we consider algorithms that operate by slicing the parameter space, i.e., trained on random lower-dimensional subspaces. We introduce new, tighter information-theoretic generalization bounds tailored for such algorithms, demonstrating that slicing improves generalization. Our bounds offer significant computational and statistical advantages over standard MI bounds, as they rely on scalable alternative measures of dependence, i.e., disintegrated mutual information and $k$-sliced mutual information. Then, we extend our analysis to algorithms whose parameters do not need to exactly lie on random subspaces, by leveraging rate-distortion theory. This strategy yields generalization bounds that incorporate a distortion term measuring model compressibility under slicing, thereby tightening existing bounds without compromising performance or requiring model compression. Building on this, we propose a regularization scheme enabling practitioners to control generalization through compressibility. Finally, we empirically validate our results and achieve the computation of non-vacuous information-theoretic generalization bounds for neural networks, a task that was previously out of reach.
6/7/2024
🖼️
An Information-Theoretic Framework for Out-of-Distribution Generalization
Wenliang Liu, Guanding Yu, Lele Wang, Renjie Liao
0
0
We study the Out-of-Distribution (OOD) generalization in machine learning and propose a general framework that provides information-theoretic generalization bounds. Our framework interpolates freely between Integral Probability Metric (IPM) and $f$-divergence, which naturally recovers some known results (including Wasserstein- and KL-bounds), as well as yields new generalization bounds. Moreover, we show that our framework admits an optimal transport interpretation. When evaluated in two concrete examples, the proposed bounds either strictly improve upon existing bounds in some cases or recover the best among existing OOD generalization bounds.
4/1/2024
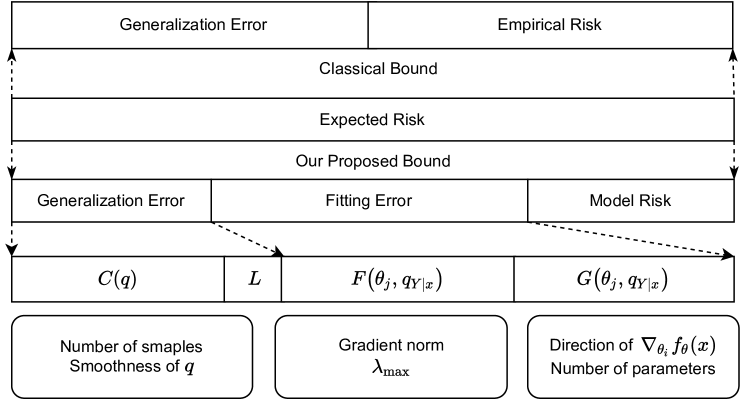
Error Bounds of Supervised Classification from Information-Theoretic Perspective
Binchuan Qi, Wei Gong, Li Li
0
0
There remains a list of unanswered research questions on deep learning (DL), including the remarkable generalization power of overparametrized neural networks, the efficient optimization performance despite the non-convexity, and the mechanisms behind flat minima in generalization. In this paper, we adopt an information-theoretic perspective to explore the theoretical foundations of supervised classification using deep neural networks (DNNs). Our analysis introduces the concepts of fitting error and model risk, which, together with generalization error, constitute an upper bound on the expected risk. We demonstrate that the generalization errors are bounded by the complexity, influenced by both the smoothness of distribution and the sample size. Consequently, task complexity serves as a reliable indicator of the dataset's quality, guiding the setting of regularization hyperparameters. Furthermore, the derived upper bound fitting error links the back-propagated gradient, Neural Tangent Kernel (NTK), and the model's parameter count with the fitting error. Utilizing the triangle inequality, we establish an upper bound on the expected risk. This bound offers valuable insights into the effects of overparameterization, non-convex optimization, and the flat minima in DNNs.Finally, empirical verification confirms a significant positive correlation between the derived theoretical bounds and the practical expected risk, confirming the practical relevance of the theoretical findings.
6/28/2024
👨🏫
Information-Theoretic Generalization Bounds for Transductive Learning and its Applications
Huayi Tang, Yong Liu
0
0
We develop generalization bounds for transductive learning algorithms in the context of information theory and PAC-Bayesian theory, covering both the random sampling setting and the random splitting setting. We show that the transductive generalization gap can be bounded by the mutual information between training labels selection and the hypothesis. By introducing the concept of transductive supersamples, we translate results depicted by various information measures from the inductive learning setting to the transductive learning setting. We further establish PAC-Bayesian bounds with weaker assumptions on the loss function and numbers of training and test data points. Finally, we present the upper bounds for adaptive optimization algorithms and demonstrate the applications of results on semi-supervised learning and graph learning scenarios. Our theoretic results are validated on both synthetic and real-world datasets.
6/11/2024