Information Bottleneck Analysis of Deep Neural Networks via Lossy Compression
2305.08013
0
0
🤿
Abstract
The Information Bottleneck (IB) principle offers an information-theoretic framework for analyzing the training process of deep neural networks (DNNs). Its essence lies in tracking the dynamics of two mutual information (MI) values: between the hidden layer output and the DNN input/target. According to the hypothesis put forth by Shwartz-Ziv & Tishby (2017), the training process consists of two distinct phases: fitting and compression. The latter phase is believed to account for the good generalization performance exhibited by DNNs. Due to the challenging nature of estimating MI between high-dimensional random vectors, this hypothesis was only partially verified for NNs of tiny sizes or specific types, such as quantized NNs. In this paper, we introduce a framework for conducting IB analysis of general NNs. Our approach leverages the stochastic NN method proposed by Goldfeld et al. (2019) and incorporates a compression step to overcome the obstacles associated with high dimensionality. In other words, we estimate the MI between the compressed representations of high-dimensional random vectors. The proposed method is supported by both theoretical and practical justifications. Notably, we demonstrate the accuracy of our estimator through synthetic experiments featuring predefined MI values and comparison with MINE (Belghazi et al., 2018). Finally, we perform IB analysis on a close-to-real-scale convolutional DNN, which reveals new features of the MI dynamics.
Create account to get full access
Overview
- The Information Bottleneck (IB) principle provides a framework for analyzing the training of deep neural networks (DNNs).
- It tracks the dynamics of two mutual information (MI) values: between the hidden layer output and the DNN input/target.
- The training process is believed to consist of two phases: fitting and compression, where the latter phase contributes to good generalization performance.
- Estimating MI between high-dimensional random vectors is challenging, limiting previous studies to small or specific NN architectures.
Plain English Explanation
The Information Bottleneck (IB) principle offers a way to understand how deep neural networks (DNNs) learn. It looks at two key pieces of information: the connection between the network's input and its hidden layers, and the connection between the hidden layers and the target output.
During training, the network goes through two distinct phases. First, it fits the data, learning to recognize patterns and make accurate predictions. Then, it compresses the information, discarding details that aren't essential for the task at hand. This compression phase is believed to be what allows DNNs to perform well on new, unseen data - a phenomenon known as generalization.
However, measuring these information connections is tricky, especially for large, complex networks. Past studies could only analyze small networks or specific network types, like quantized neural networks.
In this paper, the researchers developed a new framework to perform IB analysis on general neural networks, even large, complex ones. They used a technique called stochastic neural networks to compress the high-dimensional data, making it possible to accurately estimate the mutual information.
Technical Explanation
The researchers' approach leverages the stochastic neural network method proposed by Goldfeld et al. (2019) and incorporates a compression step to overcome the challenges associated with high dimensionality. In other words, they estimate the mutual information (MI) between compressed representations of the high-dimensional random vectors, rather than the raw vectors themselves.
The proposed method is supported by both theoretical and practical justifications. The team demonstrates the accuracy of their MI estimator through synthetic experiments with predefined MI values, and they compare it to the MINE estimator (Belghazi et al., 2018).
Finally, the researchers perform IB analysis on a convolutional DNN that is close to real-world scale, revealing new insights about the dynamics of mutual information during the training process.
Critical Analysis
The paper addresses an important challenge in understanding the training and generalization of deep neural networks. By overcoming the limitations of previous IB analyses, the proposed framework allows for the study of more realistic and complex neural network architectures.
However, the paper does not delve into potential caveats or limitations of the method. For example, the accuracy and reliability of the MI estimator may depend on the specific network architecture, dataset, or compression technique used. Additionally, the paper does not explore the implications of the observed MI dynamics or discuss how this knowledge could be leveraged to improve network design or training.
Further research could investigate the robustness of the IB analysis framework, explore its applications in network optimization or interpretability, and examine the relationship between the observed MI patterns and other measures of network performance or generalization.
Conclusion
This paper introduces a powerful framework for conducting Information Bottleneck (IB) analysis on general deep neural networks, overcoming the limitations of previous studies. By leveraging stochastic neural networks and compression techniques, the researchers demonstrate the ability to accurately estimate mutual information in high-dimensional settings.
The insights gained from this IB analysis could lead to a deeper understanding of how deep learning models learn and generalize, with potential implications for improving network architecture design, training strategies, and interpretability. As the field of deep learning continues to advance, tools like the one presented in this paper will become increasingly valuable for unlocking the inner workings of these powerful and complex models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
↗️
Cauchy-Schwarz Divergence Information Bottleneck for Regression
Shujian Yu, Xi Yu, Sigurd L{o}kse, Robert Jenssen, Jose C. Principe
0
0
The information bottleneck (IB) approach is popular to improve the generalization, robustness and explainability of deep neural networks. Essentially, it aims to find a minimum sufficient representation $mathbf{t}$ by striking a trade-off between a compression term $I(mathbf{x};mathbf{t})$ and a prediction term $I(y;mathbf{t})$, where $I(cdot;cdot)$ refers to the mutual information (MI). MI is for the IB for the most part expressed in terms of the Kullback-Leibler (KL) divergence, which in the regression case corresponds to prediction based on mean squared error (MSE) loss with Gaussian assumption and compression approximated by variational inference. In this paper, we study the IB principle for the regression problem and develop a new way to parameterize the IB with deep neural networks by exploiting favorable properties of the Cauchy-Schwarz (CS) divergence. By doing so, we move away from MSE-based regression and ease estimation by avoiding variational approximations or distributional assumptions. We investigate the improved generalization ability of our proposed CS-IB and demonstrate strong adversarial robustness guarantees. We demonstrate its superior performance on six real-world regression tasks over other popular deep IB approaches. We additionally observe that the solutions discovered by CS-IB always achieve the best trade-off between prediction accuracy and compression ratio in the information plane. The code is available at url{https://github.com/SJYuCNEL/Cauchy-Schwarz-Information-Bottleneck}.
4/30/2024
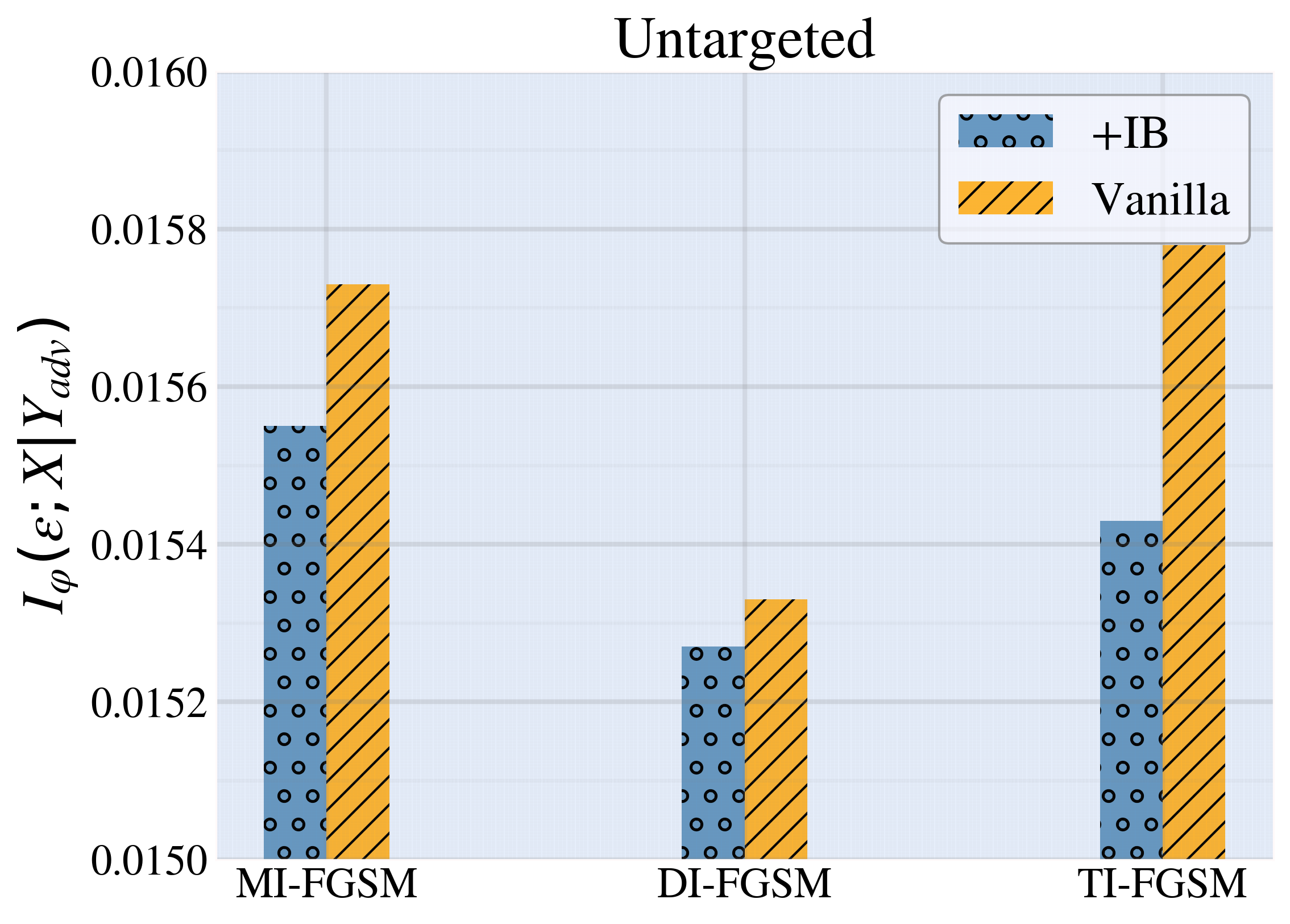
Enhancing Adversarial Transferability via Information Bottleneck Constraints
Biqing Qi, Junqi Gao, Jianxing Liu, Ligang Wu, Bowen Zhou
0
0
From the perspective of information bottleneck (IB) theory, we propose a novel framework for performing black-box transferable adversarial attacks named IBTA, which leverages advancements in invariant features. Intuitively, diminishing the reliance of adversarial perturbations on the original data, under equivalent attack performance constraints, encourages a greater reliance on invariant features that contributes most to classification, thereby enhancing the transferability of adversarial attacks. Building on this motivation, we redefine the optimization of transferable attacks using a novel theoretical framework that centers around IB. Specifically, to overcome the challenge of unoptimizable mutual information, we propose a simple and efficient mutual information lower bound (MILB) for approximating computation. Moreover, to quantitatively evaluate mutual information, we utilize the Mutual Information Neural Estimator (MINE) to perform a thorough analysis. Our experiments on the ImageNet dataset well demonstrate the efficiency and scalability of IBTA and derived MILB. Our code is available at https://github.com/Biqing-Qi/Enhancing-Adversarial-Transferability-via-Information-Bottleneck-Constraints.
6/11/2024
🤔
Towards understanding neural collapse in supervised contrastive learning with the information bottleneck method
Siwei Wang, Stephanie E Palmer
0
0
Neural collapse describes the geometry of activation in the final layer of a deep neural network when it is trained beyond performance plateaus. Open questions include whether neural collapse leads to better generalization and, if so, why and how training beyond the plateau helps. We model neural collapse as an information bottleneck (IB) problem in order to investigate whether such a compact representation exists and discover its connection to generalization. We demonstrate that neural collapse leads to good generalization specifically when it approaches an optimal IB solution of the classification problem. Recent research has shown that two deep neural networks independently trained with the same contrastive loss objective are linearly identifiable, meaning that the resulting representations are equivalent up to a matrix transformation. We leverage linear identifiability to approximate an analytical solution of the IB problem. This approximation demonstrates that when class means exhibit $K$-simplex Equiangular Tight Frame (ETF) behavior (e.g., $K$=10 for CIFAR10 and $K$=100 for CIFAR100), they coincide with the critical phase transitions of the corresponding IB problem. The performance plateau occurs once the optimal solution for the IB problem includes all of these phase transitions. We also show that the resulting $K$-simplex ETF can be packed into a $K$-dimensional Gaussian distribution using supervised contrastive learning with a ResNet50 backbone. This geometry suggests that the $K$-simplex ETF learned by supervised contrastive learning approximates the optimal features for source coding. Hence, there is a direct correspondence between optimal IB solutions and generalization in contrastive learning.
6/28/2024

Dynamic Graph Information Bottleneck
Haonan Yuan, Qingyun Sun, Xingcheng Fu, Cheng Ji, Jianxin Li
0
0
Dynamic Graphs widely exist in the real world, which carry complicated spatial and temporal feature patterns, challenging their representation learning. Dynamic Graph Neural Networks (DGNNs) have shown impressive predictive abilities by exploiting the intrinsic dynamics. However, DGNNs exhibit limited robustness, prone to adversarial attacks. This paper presents the novel Dynamic Graph Information Bottleneck (DGIB) framework to learn robust and discriminative representations. Leveraged by the Information Bottleneck (IB) principle, we first propose the expected optimal representations should satisfy the Minimal-Sufficient-Consensual (MSC) Condition. To compress redundant as well as conserve meritorious information into latent representation, DGIB iteratively directs and refines the structural and feature information flow passing through graph snapshots. To meet the MSC Condition, we decompose the overall IB objectives into DGIB$_{MS}$ and DGIB$_C$, in which the DGIB$_{MS}$ channel aims to learn the minimal and sufficient representations, with the DGIB$_{MS}$ channel guarantees the predictive consensus. Extensive experiments on real-world and synthetic dynamic graph datasets demonstrate the superior robustness of DGIB against adversarial attacks compared with state-of-the-art baselines in the link prediction task. To the best of our knowledge, DGIB is the first work to learn robust representations of dynamic graphs grounded in the information-theoretic IB principle.
4/9/2024