CBR-RAG: Case-Based Reasoning for Retrieval Augmented Generation in LLMs for Legal Question Answering
2404.04302
0
0
Abstract
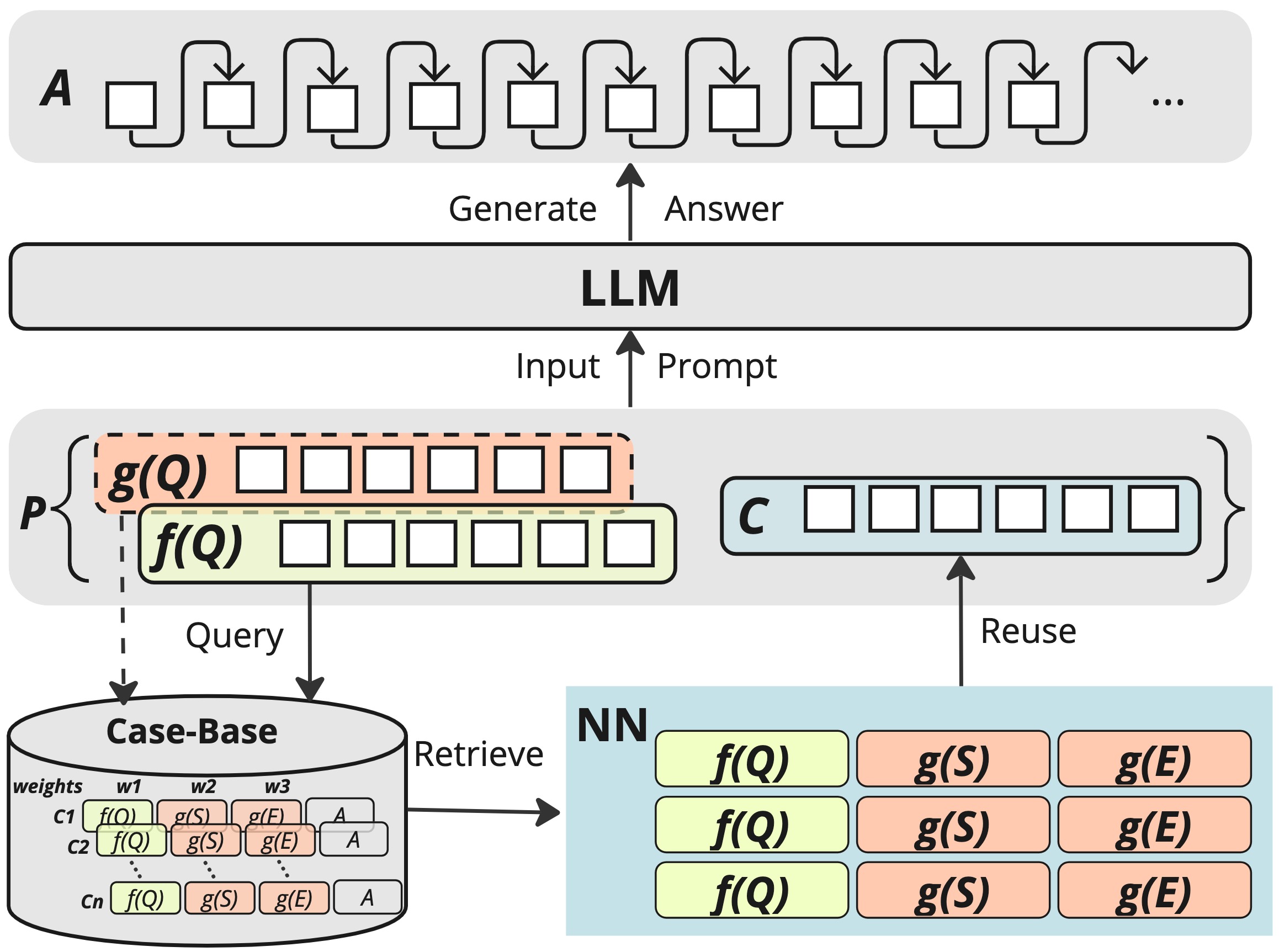
Retrieval-Augmented Generation (RAG) enhances Large Language Model (LLM) output by providing prior knowledge as context to input. This is beneficial for knowledge-intensive and expert reliant tasks, including legal question-answering, which require evidence to validate generated text outputs. We highlight that Case-Based Reasoning (CBR) presents key opportunities to structure retrieval as part of the RAG process in an LLM. We introduce CBR-RAG, where CBR cycle's initial retrieval stage, its indexing vocabulary, and similarity knowledge containers are used to enhance LLM queries with contextually relevant cases. This integration augments the original LLM query, providing a richer prompt. We present an evaluation of CBR-RAG, and examine different representations (i.e. general and domain-specific embeddings) and methods of comparison (i.e. inter, intra and hybrid similarity) on the task of legal question-answering. Our results indicate that the context provided by CBR's case reuse enforces similarity between relevant components of the questions and the evidence base leading to significant improvements in the quality of generated answers.
Create account to get full access
Overview
- This paper presents CBR-RAG, a novel approach that combines case-based reasoning (CBR) with retrieval-augmented generation (RAG) to improve legal question answering using large language models (LLMs).
- The research was funded by the SFC International Science Partnerships Fund.
Plain English Explanation
The paper introduces a new technique called CBR-RAG that aims to improve the ability of large language models to answer legal questions. Large language models are powerful AI systems that can generate human-like text, but they sometimes struggle with tasks that require in-depth knowledge or reasoning, like answering complex legal questions.
CBR-RAG combines two key ideas to address this challenge:
-
Case-Based Reasoning (CBR): This approach involves storing a database of previous "cases" or examples, and then using those cases to help solve new problems. In the context of legal question answering, the CBR component would draw on a library of past legal cases and precedents to inform the model's responses.
-
Retrieval-Augmented Generation (RAG): This technique allows the language model to dynamically retrieve relevant information from an external knowledge source while generating its response. So the model isn't just relying on its own training data, but can look up and incorporate additional context-specific information.
By combining these two ideas, CBR-RAG aims to create a more powerful and knowledgeable question-answering system for legal domains, where having access to relevant precedents and detailed information is crucial.
Technical Explanation
The core of the CBR-RAG approach is a large language model that is augmented with two key components:
-
Case-Based Retriever: This module maintains a database of past legal cases and precedents. When a new question is asked, the retriever can quickly identify the most relevant cases to include as additional context for the language model.
-
Retrieval-Augmented Generation: The language model is designed to dynamically access the case information retrieved by the CBR component, and then incorporate that external knowledge into its generated response.
The authors test this CBR-RAG approach on a legal question answering benchmark dataset. They find that it significantly outperforms standard language model baselines, demonstrating the value of combining case-based reasoning with retrieval-augmented generation.
Some key technical insights from the paper include:
- The importance of maintaining a high-quality database of legal cases and precedents for the CBR component
- Strategies for efficiently retrieving the most relevant cases for a given question
- Architectural designs that allow the language model to seamlessly integrate the retrieved case information
Critical Analysis
The authors present a compelling approach for improving legal question answering with large language models. The combination of case-based reasoning and retrieval-augmented generation seems well-suited to legal domains, where having access to relevant precedents and detailed information is crucial.
However, the paper does not address some potential limitations or areas for further research:
- The performance of the system is heavily dependent on the quality and comprehensiveness of the legal case database. Maintaining and regularly updating such a database could be challenging in practice.
- The paper does not explore how CBR-RAG might perform on more open-ended, creative legal tasks that go beyond simple question answering.
- There could be potential privacy or ethical concerns around incorporating real-world legal cases into an AI system, which the paper does not discuss.
Additionally, while the technical approach is well-explained, the paper could benefit from more discussion around the broader implications of this research. For example, how might CBR-RAG-powered legal assistants impact the legal profession, or what are the potential societal implications of AI-driven legal decision-making?
Overall, the CBR-RAG technique represents an interesting and promising step forward in legal AI, but further research and consideration of its limitations and broader impacts would be valuable.
Conclusion
This paper presents a novel approach called CBR-RAG that combines case-based reasoning and retrieval-augmented generation to improve the legal question-answering capabilities of large language models. By integrating a database of past legal cases and precedents, the system is able to provide more knowledgeable and context-relevant responses compared to standard language model baselines.
The technical insights and experimental results suggest that CBR-RAG is a promising direction for advancing the state-of-the-art in legal AI. However, the paper also highlights the need for further research to address potential limitations, such as database maintenance challenges and the broader societal implications of AI-powered legal decision-making.
Overall, the CBR-RAG approach represents an important step forward in leveraging the power of large language models for complex, knowledge-intensive tasks like legal question answering. As the field of legal AI continues to evolve, techniques like this will likely play an increasingly important role in supporting and augmenting human legal expertise.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Clustered Retrieved Augmented Generation (CRAG)
Simon Akesson, Frances A. Santos
0
0
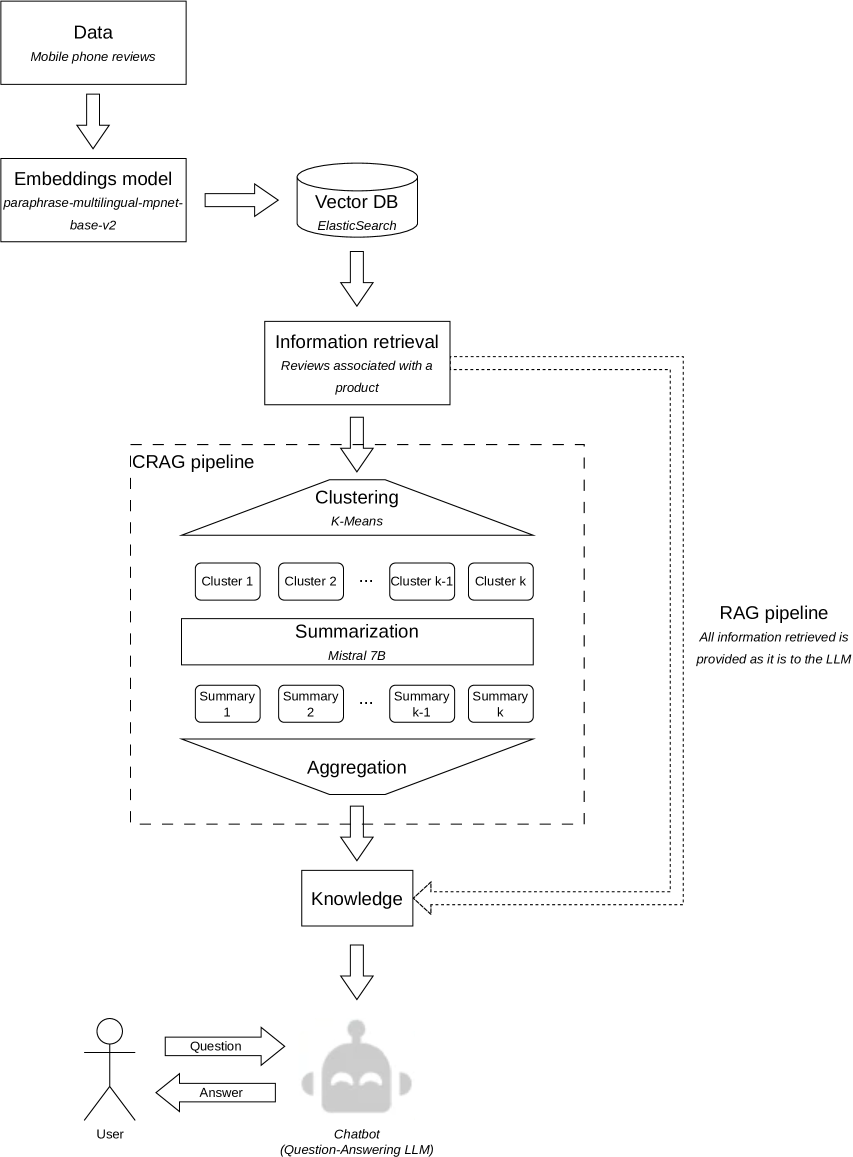
Providing external knowledge to Large Language Models (LLMs) is a key point for using these models in real-world applications for several reasons, such as incorporating up-to-date content in a real-time manner, providing access to domain-specific knowledge, and contributing to hallucination prevention. The vector database-based Retrieval Augmented Generation (RAG) approach has been widely adopted to this end. Thus, any part of external knowledge can be retrieved and provided to some LLM as the input context. Despite RAG approach's success, it still might be unfeasible for some applications, because the context retrieved can demand a longer context window than the size supported by LLM. Even when the context retrieved fits into the context window size, the number of tokens might be expressive and, consequently, impact costs and processing time, becoming impractical for most applications. To address these, we propose CRAG, a novel approach able to effectively reduce the number of prompting tokens without degrading the quality of the response generated compared to a solution using RAG. Through our experiments, we show that CRAG can reduce the number of tokens by at least 46%, achieving more than 90% in some cases, compared to RAG. Moreover, the number of tokens with CRAG does not increase considerably when the number of reviews analyzed is higher, unlike RAG, where the number of tokens is almost 9x higher when there are 75 reviews compared to 4 reviews.
6/4/2024
DR-RAG: Applying Dynamic Document Relevance to Retrieval-Augmented Generation for Question-Answering
Zijian Hei, Weiling Liu, Wenjie Ou, Juyi Qiao, Junming Jiao, Guowen Song, Ting Tian, Yi Lin
0
0
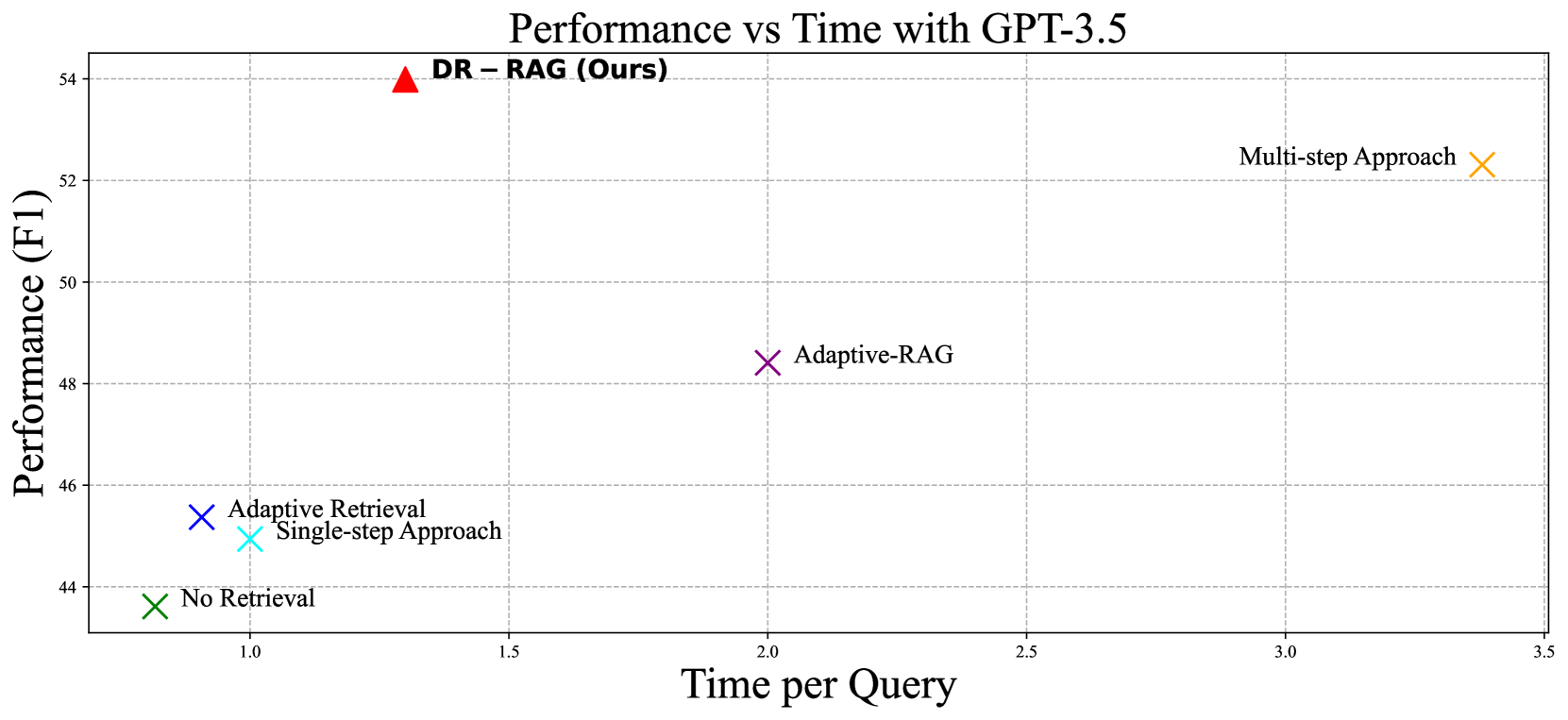
Retrieval-Augmented Generation (RAG) has recently demonstrated the performance of Large Language Models (LLMs) in the knowledge-intensive tasks such as Question-Answering (QA). RAG expands the query context by incorporating external knowledge bases to enhance the response accuracy. However, it would be inefficient to access LLMs multiple times for each query and unreliable to retrieve all the relevant documents by a single query. We have found that even though there is low relevance between some critical documents and query, it is possible to retrieve the remaining documents by combining parts of the documents with the query. To mine the relevance, a two-stage retrieval framework called Dynamic-Relevant Retrieval-Augmented Generation (DR-RAG) is proposed to improve document retrieval recall and the accuracy of answers while maintaining efficiency. Additionally, a compact classifier is applied to two different selection strategies to determine the contribution of the retrieved documents to answering the query and retrieve the relatively relevant documents. Meanwhile, DR-RAG call the LLMs only once, which significantly improves the efficiency of the experiment. The experimental results on multi-hop QA datasets show that DR-RAG can significantly improve the accuracy of the answers and achieve new progress in QA systems.
6/18/2024
Blended RAG: Improving RAG (Retriever-Augmented Generation) Accuracy with Semantic Search and Hybrid Query-Based Retrievers
Kunal Sawarkar, Abhilasha Mangal, Shivam Raj Solanki
0
0
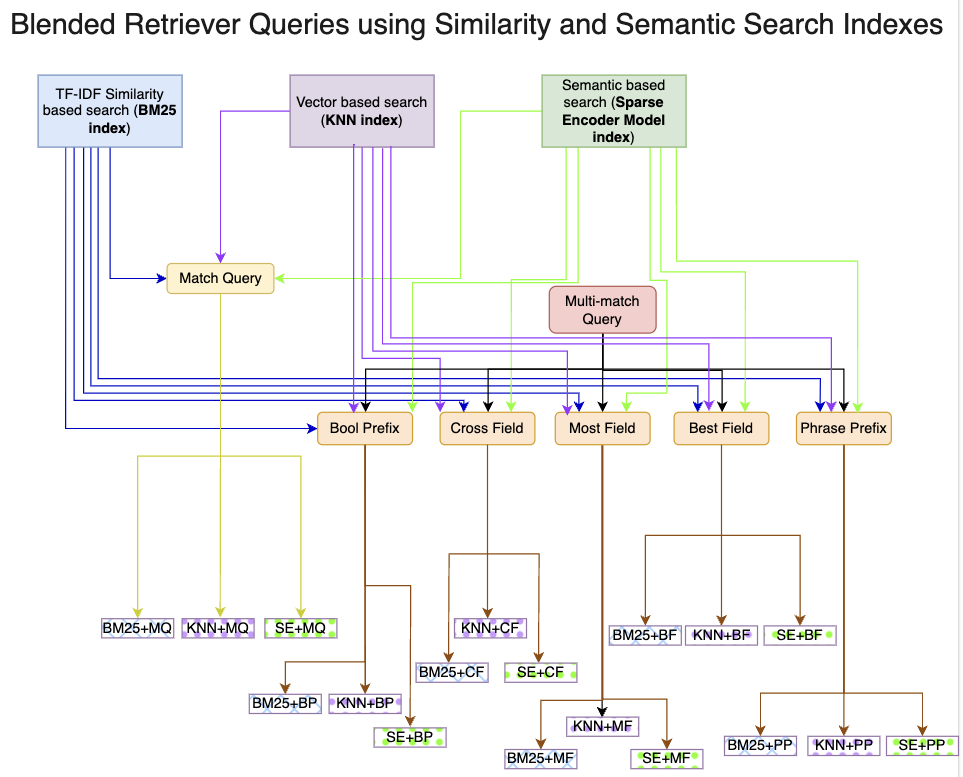
Retrieval-Augmented Generation (RAG) is a prevalent approach to infuse a private knowledge base of documents with Large Language Models (LLM) to build Generative Q&A (Question-Answering) systems. However, RAG accuracy becomes increasingly challenging as the corpus of documents scales up, with Retrievers playing an outsized role in the overall RAG accuracy by extracting the most relevant document from the corpus to provide context to the LLM. In this paper, we propose the 'Blended RAG' method of leveraging semantic search techniques, such as Dense Vector indexes and Sparse Encoder indexes, blended with hybrid query strategies. Our study achieves better retrieval results and sets new benchmarks for IR (Information Retrieval) datasets like NQ and TREC-COVID datasets. We further extend such a 'Blended Retriever' to the RAG system to demonstrate far superior results on Generative Q&A datasets like SQUAD, even surpassing fine-tuning performance.
4/12/2024
💬
A Survey on RAG Meets LLMs: Towards Retrieval-Augmented Large Language Models
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, Qing Li
0
0
As one of the most advanced techniques in AI, Retrieval-Augmented Generation (RAG) can offer reliable and up-to-date external knowledge, providing huge convenience for numerous tasks. Particularly in the era of AI-Generated Content (AIGC), the powerful capacity of retrieval in providing additional knowledge enables RAG to assist existing generative AI in producing high-quality outputs. Recently, Large Language Models (LLMs) have demonstrated revolutionary abilities in language understanding and generation, while still facing inherent limitations, such as hallucinations and out-of-date internal knowledge. Given the powerful abilities of RAG in providing the latest and helpful auxiliary information, Retrieval-Augmented Large Language Models (RA-LLMs) have emerged to harness external and authoritative knowledge bases, rather than solely relying on the model's internal knowledge, to augment the generation quality of LLMs. In this survey, we comprehensively review existing research studies in RA-LLMs, covering three primary technical perspectives: architectures, training strategies, and applications. As the preliminary knowledge, we briefly introduce the foundations and recent advances of LLMs. Then, to illustrate the practical significance of RAG for LLMs, we systematically review mainstream relevant work by their architectures, training strategies, and application areas, detailing specifically the challenges of each and the corresponding capabilities of RA-LLMs. Finally, to deliver deeper insights, we discuss current limitations and several promising directions for future research. Updated information about this survey can be found at https://advanced-recommender-systems.github.io/RAG-Meets-LLMs/
6/18/2024