Clustered Retrieved Augmented Generation (CRAG)
2406.00029
0
0
Abstract
Providing external knowledge to Large Language Models (LLMs) is a key point for using these models in real-world applications for several reasons, such as incorporating up-to-date content in a real-time manner, providing access to domain-specific knowledge, and contributing to hallucination prevention. The vector database-based Retrieval Augmented Generation (RAG) approach has been widely adopted to this end. Thus, any part of external knowledge can be retrieved and provided to some LLM as the input context. Despite RAG approach's success, it still might be unfeasible for some applications, because the context retrieved can demand a longer context window than the size supported by LLM. Even when the context retrieved fits into the context window size, the number of tokens might be expressive and, consequently, impact costs and processing time, becoming impractical for most applications. To address these, we propose CRAG, a novel approach able to effectively reduce the number of prompting tokens without degrading the quality of the response generated compared to a solution using RAG. Through our experiments, we show that CRAG can reduce the number of tokens by at least 46%, achieving more than 90% in some cases, compared to RAG. Moreover, the number of tokens with CRAG does not increase considerably when the number of reviews analyzed is higher, unlike RAG, where the number of tokens is almost 9x higher when there are 75 reviews compared to 4 reviews.
Create account to get full access
Overview
- This paper introduces Clustered Retrieved Augmented Generation (CRAG), a new approach for large language models to generate content by leveraging retrieved information from a knowledge base.
- CRAG aims to improve upon previous retrieval-augmented generation methods by clustering related information and selectively incorporating it into the generation process.
- The authors evaluate CRAG on several tasks, including question answering, summarization, and open-ended generation, and compare its performance to other state-of-the-art models.
Plain English Explanation
The paper presents a new technique called Clustered Retrieved Augmented Generation (CRAG) that helps large language models [like GPT-3] generate better text by using information pulled from a database or knowledge base.
Previous methods for retrieval-augmented generation had some limitations, so the authors of this paper developed CRAG to address those issues. The key idea behind CRAG is to cluster related pieces of information from the knowledge base, and then selectively incorporate that information into the language model's generation process.
For example, if the model is asked to write about the history of a city, CRAG would first retrieve relevant facts and details about that city from a database. It would then group together the related information (like founding date, key historical events, famous landmarks, etc.) into clusters. The model could then strategically pull from those clustered information sources to generate a more coherent and comprehensive response.
The researchers tested CRAG on tasks like answering questions, summarizing text, and open-ended writing. They found that it outperformed other state-of-the-art retrieval-augmented generation approaches. This suggests CRAG could be a helpful technique for improving the quality and reliability of text generated by large language models.
Technical Explanation
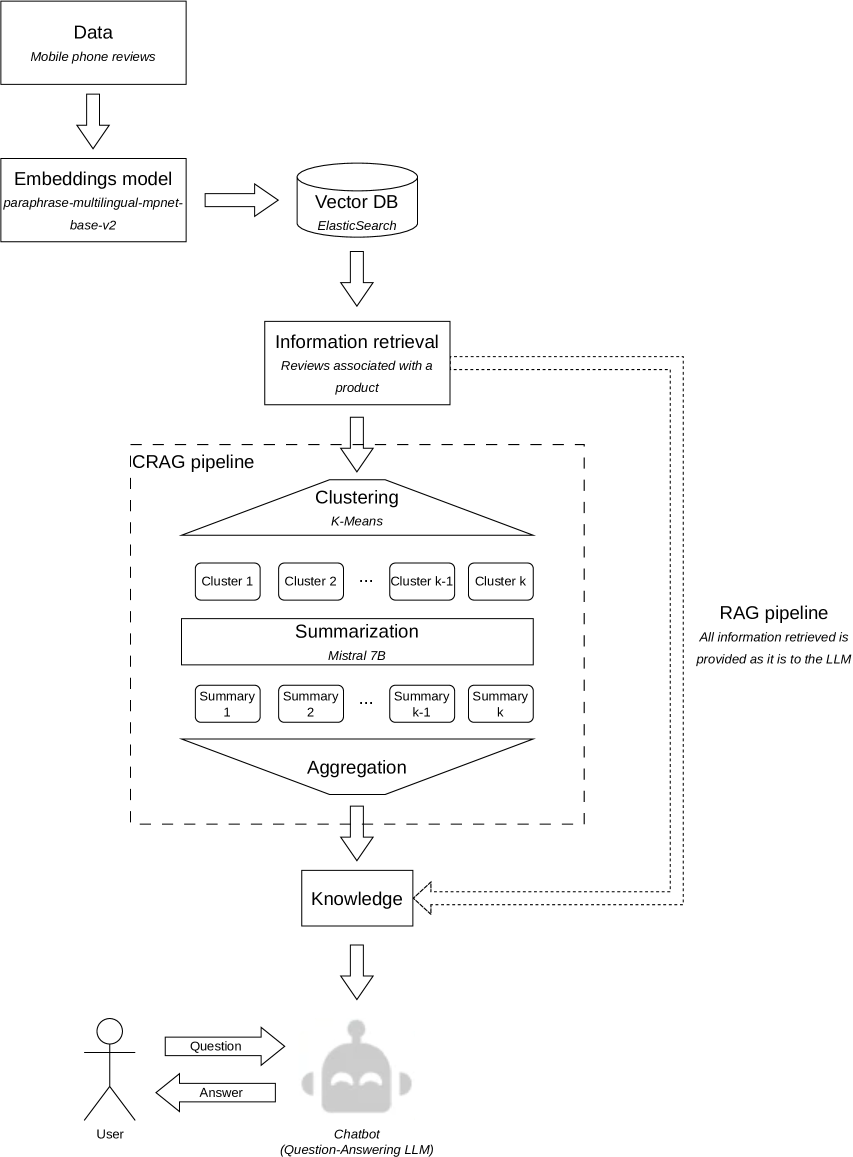
The core innovation of CRAG is its clustering and selective incorporation of retrieved information into the generation process. Previous retrieval-augmented generation methods, like RAG and GRAG, would simply concatenate all retrieved passages to the input before generation.
In contrast, CRAG first clusters the retrieved passages into semantically related groups using a neural clustering algorithm. It then selects the most relevant clusters to incorporate into the generation, based on the task and generation context. This allows the model to focus on the most salient information and avoid irrelevant or redundant details.
The CRAG architecture consists of four main components:
- Retriever: Finds relevant passages from a knowledge base given the input
- Clustering Module: Groups the retrieved passages into semantically coherent clusters
- Selector: Determines which clusters to include in the generation based on the task and context
- Generator: The language model that generates the final output, conditioned on the selected clusters
The authors evaluated CRAG on tasks like question answering, summarization, and open-ended generation, and found it outperformed other retrieval-augmented approaches. They attribute this to CRAG's ability to more effectively leverage the retrieved information.
Critical Analysis
The CRAG paper presents a promising new direction for improving the performance of large language models through retrieval-augmented generation. The authors' key insight - that selectively incorporating clustered information can lead to better-quality outputs - is well-supported by their experimental results.
However, the paper does not address some potential limitations of the CRAG approach. For instance, the performance of the system is heavily dependent on the quality and coverage of the underlying knowledge base. If the knowledge base is incomplete or biased, CRAG may struggle to generate accurate or unbiased outputs.
Additionally, the paper does not explore how CRAG's performance scales with the size of the knowledge base or the complexity of the generation task. It's possible that the benefits of CRAG diminish as the system has to handle larger or more open-ended inputs.
Further research is needed to better understand the tradeoffs and limitations of the CRAG approach, as well as explore ways to make it more robust and generalizable. Incorporating CRAG into a broader suite of retrieval-augmented generation techniques could also lead to even stronger performance on a wide range of language tasks.
Conclusion
The CRAG paper presents a novel approach for enhancing the text generation capabilities of large language models by selectively incorporating relevant information from a knowledge base. By clustering related passages and strategically selecting which clusters to include in the generation process, CRAG is able to outperform other state-of-the-art retrieval-augmented generation methods.
This work represents an important step forward in developing more reliable and coherent language models, with potential applications in areas like question answering, summarization, and open-ended dialogue. As large language models become increasingly ubiquitous, techniques like CRAG will be crucial for ensuring they can generate high-quality, truthful, and contextually appropriate text.
While the CRAG approach shows promise, further research is needed to address its limitations and explore ways to make it even more robust and adaptable. Nonetheless, this paper makes a valuable contribution to the field of retrieval-augmented generation, and its insights could help pave the way for more advanced and capable language AI systems in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
DuetRAG: Collaborative Retrieval-Augmented Generation
Dian Jiao, Li Cai, Jingsheng Huang, Wenqiao Zhang, Siliang Tang, Yueting Zhuang
0
0
Retrieval-Augmented Generation (RAG) methods augment the input of Large Language Models (LLMs) with relevant retrieved passages, reducing factual errors in knowledge-intensive tasks. However, contemporary RAG approaches suffer from irrelevant knowledge retrieval issues in complex domain questions (e.g., HotPot QA) due to the lack of corresponding domain knowledge, leading to low-quality generations. To address this issue, we propose a novel Collaborative Retrieval-Augmented Generation framework, DuetRAG. Our bootstrapping philosophy is to simultaneously integrate the domain fintuning and RAG models to improve the knowledge retrieval quality, thereby enhancing generation quality. Finally, we demonstrate DuetRAG' s matches with expert human researchers on HotPot QA.
5/24/2024

Empowering Large Language Models to Set up a Knowledge Retrieval Indexer via Self-Learning
Xun Liang, Simin Niu, Zhiyu li, Sensen Zhang, Shichao Song, Hanyu Wang, Jiawei Yang, Feiyu Xiong, Bo Tang, Chenyang Xi
0
0
Retrieval-Augmented Generation (RAG) offers a cost-effective approach to injecting real-time knowledge into large language models (LLMs). Nevertheless, constructing and validating high-quality knowledge repositories require considerable effort. We propose a pre-retrieval framework named Pseudo-Graph Retrieval-Augmented Generation (PG-RAG), which conceptualizes LLMs as students by providing them with abundant raw reading materials and encouraging them to engage in autonomous reading to record factual information in their own words. The resulting concise, well-organized mental indices are interconnected through common topics or complementary facts to form a pseudo-graph database. During the retrieval phase, PG-RAG mimics the human behavior in flipping through notes, identifying fact paths and subsequently exploring the related contexts. Adhering to the principle of the path taken by many is the best, it integrates highly corroborated fact paths to provide a structured and refined sub-graph assisting LLMs. We validated PG-RAG on three specialized question-answering datasets. In single-document tasks, PG-RAG significantly outperformed the current best baseline, KGP-LLaMA, across all key evaluation metrics, with an average overall performance improvement of 11.6%. Specifically, its BLEU score increased by approximately 14.3%, and the QE-F1 metric improved by 23.7%. In multi-document scenarios, the average metrics of PG-RAG were at least 2.35% higher than the best baseline. Notably, the BLEU score and QE-F1 metric showed stable improvements of around 7.55% and 12.75%, respectively. Our code: https://github.com/IAAR-Shanghai/PGRAG.
5/28/2024
Context-augmented Retrieval: A Novel Framework for Fast Information Retrieval based Response Generation using Large Language Model
Sai Ganesh, Anupam Purwar, Gautam B
0
0
Generating high-quality answers consistently by providing contextual information embedded in the prompt passed to the Large Language Model (LLM) is dependent on the quality of information retrieval. As the corpus of contextual information grows, the answer/inference quality of Retrieval Augmented Generation (RAG) based Question Answering (QA) systems declines. This work solves this problem by combining classical text classification with the Large Language Model (LLM) to enable quick information retrieval from the vector store and ensure the relevancy of retrieved information. For the same, this work proposes a new approach Context Augmented retrieval (CAR), where partitioning of vector database by real-time classification of information flowing into the corpus is done. CAR demonstrates good quality answer generation along with significant reduction in information retrieval and answer generation time.
6/26/2024
GRAG: Graph Retrieval-Augmented Generation
Yuntong Hu, Zhihan Lei, Zheng Zhang, Bo Pan, Chen Ling, Liang Zhao
0
0
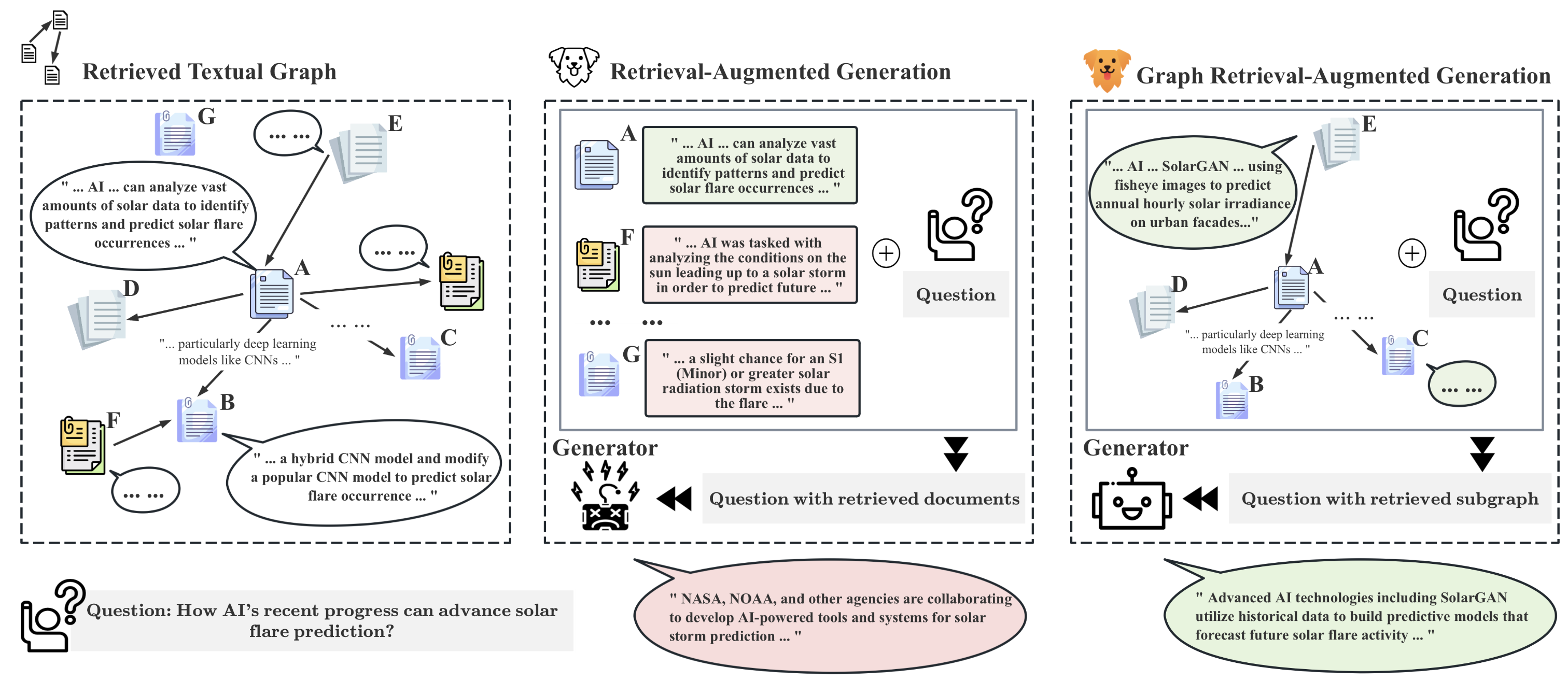
While Retrieval-Augmented Generation (RAG) enhances the accuracy and relevance of responses by generative language models, it falls short in graph-based contexts where both textual and topological information are important. Naive RAG approaches inherently neglect the structural intricacies of textual graphs, resulting in a critical gap in the generation process. To address this challenge, we introduce $textbf{Graph Retrieval-Augmented Generation (GRAG)}$, which significantly enhances both the retrieval and generation processes by emphasizing the importance of subgraph structures. Unlike RAG approaches that focus solely on text-based entity retrieval, GRAG maintains an acute awareness of graph topology, which is crucial for generating contextually and factually coherent responses. Our GRAG approach consists of four main stages: indexing of $k$-hop ego-graphs, graph retrieval, soft pruning to mitigate the impact of irrelevant entities, and generation with pruned textual subgraphs. GRAG's core workflow-retrieving textual subgraphs followed by soft pruning-efficiently identifies relevant subgraph structures while avoiding the computational infeasibility typical of exhaustive subgraph searches, which are NP-hard. Moreover, we propose a novel prompting strategy that achieves lossless conversion from textual subgraphs to hierarchical text descriptions. Extensive experiments on graph multi-hop reasoning benchmarks demonstrate that in scenarios requiring multi-hop reasoning on textual graphs, our GRAG approach significantly outperforms current state-of-the-art RAG methods while effectively mitigating hallucinations.
5/28/2024