CEAR: Automatic construction of a knowledge graph of chemical entities and roles from scientific literature

0

Sign in to get full access
Overview
- Automatic construction of a knowledge graph of chemical entities and their roles from scientific literature
- Combines natural language processing, information extraction, and knowledge graph techniques
- Aims to enhance retrieval and reasoning capabilities for chemistry-related tasks
Plain English Explanation
The paper presents CEAR, a system that automatically builds a knowledge graph of chemical entities and their roles from scientific literature. The knowledge graph connects different chemical concepts, such as compounds, reactions, and properties, to enable better retrieval and reasoning for chemistry-related tasks.
The key idea is to extract relevant information from research papers using natural language processing and information extraction techniques, and then organize this data into a structured knowledge graph. This allows users to more easily find and understand connections between different chemical entities and their roles, which can be useful for tasks like drug discovery, material design, and chemistry education.
For example, the knowledge graph might connect a specific chemical compound to the reactions it participates in, the properties it has, and the applications it is used for. This type of structured information is more powerful than simply searching through a large corpus of text, as it allows users to traverse and reason over the relationships between different chemical concepts.
Technical Explanation
CEAR works by first identifying and extracting chemical entities, such as compounds, reactions, and properties, from the text of scientific papers using natural language processing techniques. It then determines the roles and relationships between these entities, such as a compound participating in a reaction or having a particular property.
The extracted information is then used to construct a knowledge graph, which is a type of structured database that represents entities as nodes and the relationships between them as edges. This knowledge graph can be queried and traversed to answer questions about the connections between different chemical concepts.
The key technical components of CEAR include:
- Entity extraction: Using named entity recognition and relation extraction models to identify and extract chemical entities and their roles from text.
- Relation extraction: Determining the relationships between the extracted entities, such as a compound participating in a reaction.
- Knowledge graph construction: Organizing the extracted entities and relationships into a structured knowledge graph data model.
- Knowledge graph reasoning: Enabling advanced querying and reasoning over the knowledge graph to answer complex chemistry-related questions.
The paper evaluates the performance of CEAR on several benchmark datasets and demonstrates its effectiveness in improving the retrieval and reasoning capabilities for chemistry-related tasks compared to traditional text-based approaches.
Critical Analysis
The paper provides a comprehensive overview of the CEAR system and its key technical components. The authors have clearly put a lot of thought into the design and implementation of the system, and the results show that it can provide significant benefits for chemistry-related tasks.
One potential limitation of the approach is that it relies heavily on the quality and coverage of the scientific literature used to construct the knowledge graph. If there are gaps or biases in the underlying data, this could lead to incomplete or skewed knowledge graphs. The authors acknowledge this and suggest that incorporating additional data sources, such as chemical databases, could help address this issue.
Additionally, the paper does not provide much detail on the specific natural language processing and information extraction models used, or the details of the knowledge graph construction and reasoning components. While the high-level architecture is described, a more in-depth technical explanation of these key components would be helpful for researchers looking to replicate or build upon the work.
Overall, the CEAR system represents an interesting and promising approach to enhancing the retrieval and reasoning capabilities for chemistry-related tasks. Further research and refinement of the technical components, as well as exploration of additional use cases and applications, could help to unlock the full potential of this technology.
Conclusion
The CEAR system presents a novel approach to automatically constructing a knowledge graph of chemical entities and their roles from scientific literature. By combining natural language processing, information extraction, and knowledge graph techniques, CEAR aims to enable more powerful retrieval and reasoning capabilities for a wide range of chemistry-related tasks, from drug discovery to material design and education.
The technical details and evaluation results presented in the paper suggest that CEAR is a promising step towards bridging the gap between the wealth of unstructured information in scientific literature and the need for structured, machine-readable knowledge to support advanced chemistry-related applications. As the field of knowledge graph construction and reasoning continues to evolve, systems like CEAR will likely play an increasingly important role in enhancing our ability to extract insights and make new discoveries from the ever-growing corpus of scientific literature.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CEAR: Automatic construction of a knowledge graph of chemical entities and roles from scientific literature
Stefan Langer, Fabian Neuhaus, Andreas Nurnberger
Ontologies are formal representations of knowledge in specific domains that provide a structured framework for organizing and understanding complex information. Creating ontologies, however, is a complex and time-consuming endeavor. ChEBI is a well-known ontology in the field of chemistry, which provides a comprehensive resource for defining chemical entities and their properties. However, it covers only a small fraction of the rapidly growing knowledge in chemistry and does not provide references to the scientific literature. To address this, we propose a methodology that involves augmenting existing annotated text corpora with knowledge from Chebi and fine-tuning a large language model (LLM) to recognize chemical entities and their roles in scientific text. Our experiments demonstrate the effectiveness of our approach. By combining ontological knowledge and the language understanding capabilities of LLMs, we achieve high precision and recall rates in identifying both the chemical entities and roles in scientific literature. Furthermore, we extract them from a set of 8,000 ChemRxiv articles, and apply a second LLM to create a knowledge graph (KG) of chemical entities and roles (CEAR), which provides complementary information to ChEBI, and can help to extend it.
Read more8/1/2024

0
Integrating knowledge bases to improve coreference and bridging resolution for the chemical domain
Pengcheng Lu, Massimo Poesio
Resolving coreference and bridging relations in chemical patents is important for better understanding the precise chemical process, where chemical domain knowledge is very critical. We proposed an approach incorporating external knowledge into a multi-task learning model for both coreference and bridging resolution in the chemical domain. The results show that integrating external knowledge can benefit both chemical coreference and bridging resolution.
Read more4/17/2024
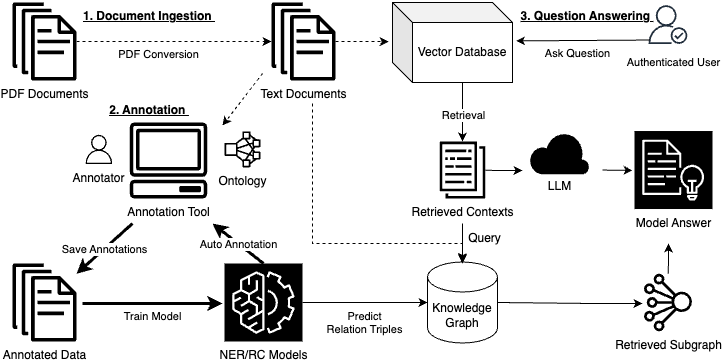
0
KnowledgeHub: An end-to-end Tool for Assisted Scientific Discovery
Shinnosuke Tanaka, James Barry, Vishnudev Kuruvanthodi, Movina Moses, Maxwell J. Giammona, Nathan Herr, Mohab Elkaref, Geeth De Mel
This paper describes the KnowledgeHub tool, a scientific literature Information Extraction (IE) and Question Answering (QA) pipeline. This is achieved by supporting the ingestion of PDF documents that are converted to text and structured representations. An ontology can then be constructed where a user defines the types of entities and relationships they want to capture. A browser-based annotation tool enables annotating the contents of the PDF documents according to the ontology. Named Entity Recognition (NER) and Relation Classification (RC) models can be trained on the resulting annotations and can be used to annotate the unannotated portion of the documents. A knowledge graph is constructed from these entity and relation triples which can be queried to obtain insights from the data. Furthermore, we integrate a suite of Large Language Models (LLMs) that can be used for QA and summarisation that is grounded in the included documents via a retrieval component. KnowledgeHub is a unique tool that supports annotation, IE and QA, which gives the user full insight into the knowledge discovery pipeline.
Read more6/18/2024

0
Generalized knowledge-enhanced framework for biomedical entity and relation extraction
Minh Nguyen, Phuong Le
In recent years, there has been an increasing number of frameworks developed for biomedical entity and relation extraction. This research effort aims to address the accelerating growth in biomedical publications and the intricate nature of biomedical texts, which are written for mainly domain experts. To handle these challenges, we develop a novel framework that utilizes external knowledge to construct a task-independent and reusable background knowledge graph for biomedical entity and relation extraction. The design of our model is inspired by how humans learn domain-specific topics. In particular, humans often first acquire the most basic and common knowledge regarding a field to build the foundational knowledge and then use that as a basis for extending to various specialized topics. Our framework employs such common-knowledge-sharing mechanism to build a general neural-network knowledge graph that is learning transferable to different domain-specific biomedical texts effectively. Experimental evaluations demonstrate that our model, equipped with this generalized and cross-transferable knowledge base, achieves competitive performance benchmarks, including BioRelEx for binding interaction detection and ADE for Adverse Drug Effect identification.
Read more8/14/2024