KnowledgeHub: An end-to-end Tool for Assisted Scientific Discovery

0
Sign in to get full access
Overview
- KnowledgeHub is an end-to-end tool designed to assist scientific discovery
- It integrates various AI-powered capabilities, including natural language processing, knowledge retrieval, and reasoning
- The tool aims to support researchers throughout the discovery process, from formulating research questions to synthesizing insights
Plain English Explanation
KnowledgeHub is a comprehensive tool that uses advanced AI technologies to help researchers in their scientific discovery process. It is designed to make their work more efficient and effective by providing a range of capabilities, such as understanding natural language, accessing relevant knowledge, and drawing insights from data.
For example, if a researcher is trying to explore a new area of study, they can use KnowledgeHub to Enhancing Question Answering with Enterprise Knowledge Bases to quickly find and understand the most relevant information from various sources. The tool can also assist in Efficient Question Answering with Strategic Multi-Model approaches, helping researchers ask more targeted and productive questions.
As the research progresses, KnowledgeHub can support the synthesis of findings by Elevating Multi-Document QA Reasoning with Infused Curiosity, allowing researchers to connect the dots and uncover new insights. The tool can also help researchers interact with Knowledge Bases using a Generate-Then-Retrieve Framework, making it easier to access and leverage relevant information.
Overall, KnowledgeHub aims to be a valuable companion for researchers, empowering them to explore scientific questions more effectively and efficiently.
Technical Explanation
KnowledgeHub is an end-to-end system that integrates various AI-powered capabilities to support the scientific discovery process. The system leverages natural language processing (NLP) techniques to understand user queries and research questions, and then retrieves relevant information from a comprehensive knowledge base.
The knowledge base is constructed by Combining Knowledge Graphs and Natural Language to create a unified repository of scientific knowledge. This allows KnowledgeHub to provide researchers with access to a wide range of information, from academic papers and datasets to domain-specific knowledge.
The system also incorporates reasoning and analytical capabilities to help researchers synthesize insights from the retrieved information. By Elevating Multi-Document QA Reasoning with Infused Curiosity, KnowledgeHub can identify connections, patterns, and hypotheses that may not be immediately apparent.
Throughout the research process, KnowledgeHub provides a seamless user experience, allowing researchers to Generate-Then-Retrieve information, ask follow-up questions, and collaborate with others. The system is designed to be intuitive and user-friendly, empowering researchers to focus on their core scientific work.
Critical Analysis
The paper provides a comprehensive overview of the KnowledgeHub system, highlighting its potential to significantly enhance the scientific discovery process. The integration of various AI-powered capabilities, such as NLP, knowledge retrieval, and reasoning, is a promising approach to addressing the challenges researchers often face in accessing and synthesizing relevant information.
However, the paper does not delve deeply into the specific technical details of the system's architecture or the underlying algorithms. While the high-level descriptions are helpful, a more detailed exploration of the system's inner workings and the evaluation of its performance would provide a more thorough understanding of the tool's capabilities and limitations.
Additionally, the paper does not address potential ethical concerns or privacy implications that may arise from the extensive use of AI and knowledge aggregation in the scientific domain. As with any powerful technology, it is crucial to consider the societal impact and ensure that KnowledgeHub is designed and deployed in a responsible and transparent manner.
Further research and user studies would also be beneficial to understand the real-world effectiveness of KnowledgeHub and its acceptance among the research community. Gathering feedback from researchers and incorporating their needs and preferences into the tool's development could enhance its usability and ensure it meets the specific requirements of the scientific community.
Conclusion
KnowledgeHub is an innovative and promising tool that aims to revolutionize the way researchers conduct scientific discovery. By integrating advanced AI capabilities, the system provides researchers with a comprehensive suite of tools to access relevant knowledge, synthesize insights, and streamline their research processes.
The potential impact of KnowledgeHub on scientific research is significant, as it could lead to more efficient and productive discovery, accelerating the pace of scientific progress. As the field of AI continues to evolve, tools like KnowledgeHub will play an increasingly important role in empowering researchers and driving scientific breakthroughs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
KnowledgeHub: An end-to-end Tool for Assisted Scientific Discovery
Shinnosuke Tanaka, James Barry, Vishnudev Kuruvanthodi, Movina Moses, Maxwell J. Giammona, Nathan Herr, Mohab Elkaref, Geeth De Mel
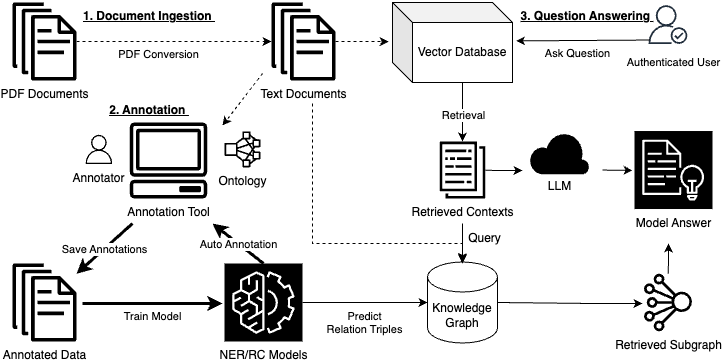
This paper describes the KnowledgeHub tool, a scientific literature Information Extraction (IE) and Question Answering (QA) pipeline. This is achieved by supporting the ingestion of PDF documents that are converted to text and structured representations. An ontology can then be constructed where a user defines the types of entities and relationships they want to capture. A browser-based annotation tool enables annotating the contents of the PDF documents according to the ontology. Named Entity Recognition (NER) and Relation Classification (RC) models can be trained on the resulting annotations and can be used to annotate the unannotated portion of the documents. A knowledge graph is constructed from these entity and relation triples which can be queried to obtain insights from the data. Furthermore, we integrate a suite of Large Language Models (LLMs) that can be used for QA and summarisation that is grounded in the included documents via a retrieval component. KnowledgeHub is a unique tool that supports annotation, IE and QA, which gives the user full insight into the knowledge discovery pipeline.
Read more6/18/2024
🤷
0
Knowledge Navigator: LLM-guided Browsing Framework for Exploratory Search in Scientific Literature
Uri Katz, Mosh Levy, Yoav Goldberg
The exponential growth of scientific literature necessitates advanced tools for effective knowledge exploration. We present Knowledge Navigator, a system designed to enhance exploratory search abilities by organizing and structuring the retrieved documents from broad topical queries into a navigable, two-level hierarchy of named and descriptive scientific topics and subtopics. This structured organization provides an overall view of the research themes in a domain, while also enabling iterative search and deeper knowledge discovery within specific subtopics by allowing users to refine their focus and retrieve additional relevant documents. Knowledge Navigator combines LLM capabilities with cluster-based methods to enable an effective browsing method. We demonstrate our approach's effectiveness through automatic and manual evaluations on two novel benchmarks, CLUSTREC-COVID and SCITOC. Our code, prompts, and benchmarks are made publicly available.
Read more8/29/2024

0
Docs2KG: Unified Knowledge Graph Construction from Heterogeneous Documents Assisted by Large Language Models
Qiang Sun, Yuanyi Luo, Wenxiao Zhang, Sirui Li, Jichunyang Li, Kai Niu, Xiangrui Kong, Wei Liu
Even for a conservative estimate, 80% of enterprise data reside in unstructured files, stored in data lakes that accommodate heterogeneous formats. Classical search engines can no longer meet information seeking needs, especially when the task is to browse and explore for insight formulation. In other words, there are no obvious search keywords to use. Knowledge graphs, due to their natural visual appeals that reduce the human cognitive load, become the winning candidate for heterogeneous data integration and knowledge representation. In this paper, we introduce Docs2KG, a novel framework designed to extract multimodal information from diverse and heterogeneous unstructured documents, including emails, web pages, PDF files, and Excel files. Dynamically generates a unified knowledge graph that represents the extracted key information, Docs2KG enables efficient querying and exploration of document data lakes. Unlike existing approaches that focus on domain-specific data sources or pre-designed schemas, Docs2KG offers a flexible and extensible solution that can adapt to various document structures and content types. The proposed framework unifies data processing supporting a multitude of downstream tasks with improved domain interpretability. Docs2KG is publicly accessible at https://docs2kg.ai4wa.com, and a demonstration video is available at https://docs2kg.ai4wa.com/Video.
Read more6/6/2024
0
Enhancing Question Answering for Enterprise Knowledge Bases using Large Language Models
Feihu Jiang, Chuan Qin, Kaichun Yao, Chuyu Fang, Fuzhen Zhuang, Hengshu Zhu, Hui Xiong
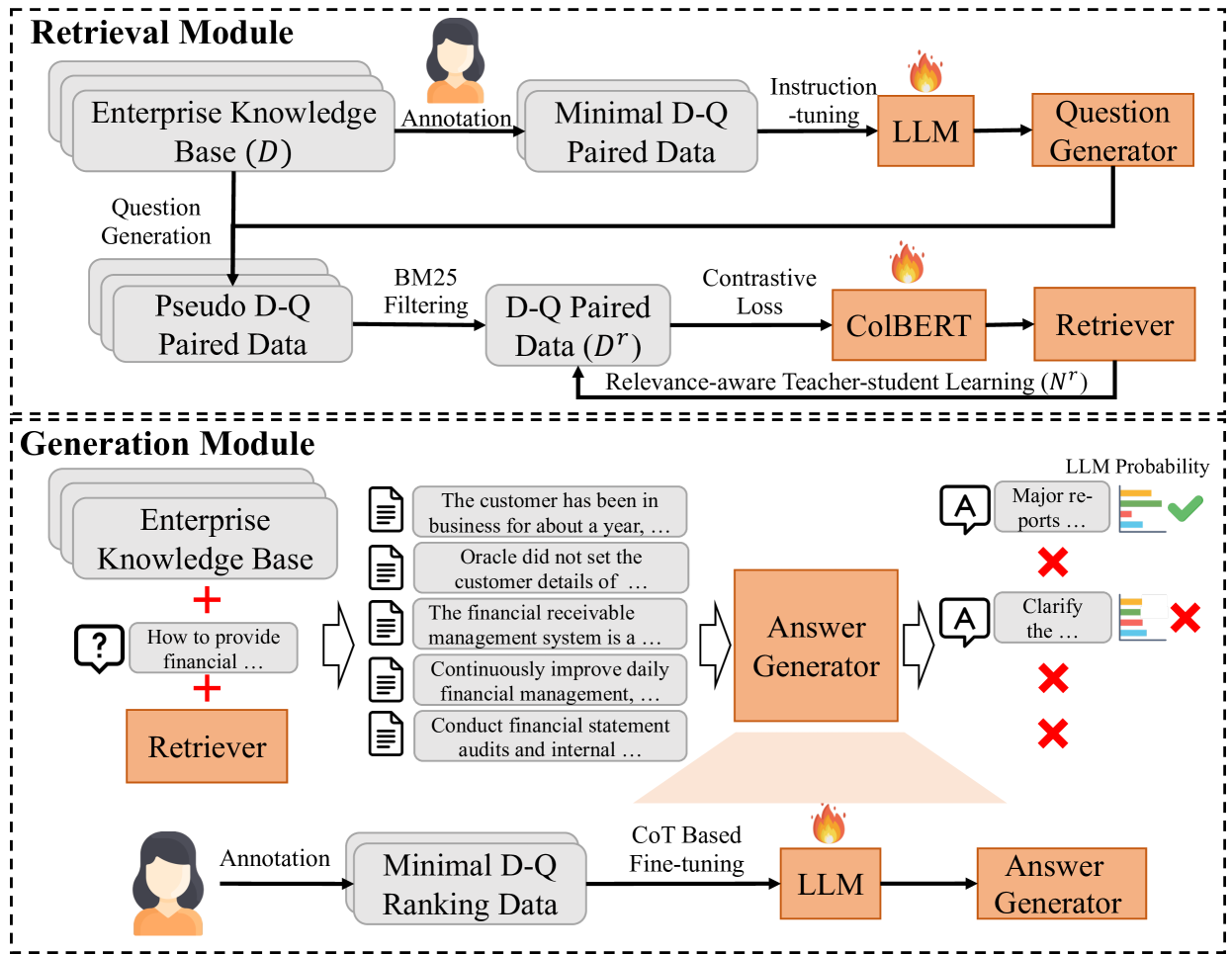
Efficient knowledge management plays a pivotal role in augmenting both the operational efficiency and the innovative capacity of businesses and organizations. By indexing knowledge through vectorization, a variety of knowledge retrieval methods have emerged, significantly enhancing the efficacy of knowledge management systems. Recently, the rapid advancements in generative natural language processing technologies paved the way for generating precise and coherent answers after retrieving relevant documents tailored to user queries. However, for enterprise knowledge bases, assembling extensive training data from scratch for knowledge retrieval and generation is a formidable challenge due to the privacy and security policies of private data, frequently entailing substantial costs. To address the challenge above, in this paper, we propose EKRG, a novel Retrieval-Generation framework based on large language models (LLMs), expertly designed to enable question-answering for Enterprise Knowledge bases with limited annotation costs. Specifically, for the retrieval process, we first introduce an instruction-tuning method using an LLM to generate sufficient document-question pairs for training a knowledge retriever. This method, through carefully designed instructions, efficiently generates diverse questions for enterprise knowledge bases, encompassing both fact-oriented and solution-oriented knowledge. Additionally, we develop a relevance-aware teacher-student learning strategy to further enhance the efficiency of the training process. For the generation process, we propose a novel chain of thought (CoT) based fine-tuning method to empower the LLM-based generator to adeptly respond to user questions using retrieved documents. Finally, extensive experiments on real-world datasets have demonstrated the effectiveness of our proposed framework.
Read more4/23/2024