ChAda-ViT : Channel Adaptive Attention for Joint Representation Learning of Heterogeneous Microscopy Images
2311.15264
0
0

Abstract
Unlike color photography images, which are consistently encoded into RGB channels, biological images encompass various modalities, where the type of microscopy and the meaning of each channel varies with each experiment. Importantly, the number of channels can range from one to a dozen and their correlation is often comparatively much lower than RGB, as each of them brings specific information content. This aspect is largely overlooked by methods designed out of the bioimage field, and current solutions mostly focus on intra-channel spatial attention, often ignoring the relationship between channels, yet crucial in most biological applications. Importantly, the variable channel type and count prevent the projection of several experiments to a unified representation for large scale pre-training. In this study, we propose ChAda-ViT, a novel Channel Adaptive Vision Transformer architecture employing an Inter-Channel Attention mechanism on images with an arbitrary number, order and type of channels. We also introduce IDRCell100k, a bioimage dataset with a rich set of 79 experiments covering 7 microscope modalities, with a multitude of channel types, and counts varying from 1 to 10 per experiment. Our architecture, trained in a self-supervised manner, outperforms existing approaches in several biologically relevant downstream tasks. Additionally, it can be used to bridge the gap for the first time between assays with different microscopes, channel numbers or types by embedding various image and experimental modalities into a unified biological image representation. The latter should facilitate interdisciplinary studies and pave the way for better adoption of deep learning in biological image-based analyses. Code and Data available at https://github.com/nicoboou/chadavit.
Create account to get full access
Overview
- This paper proposes a new deep learning model called ChAda-ViT (Channel Adaptive Vision Transformer) for joint representation learning of heterogeneous microscopy images.
- The model leverages a channel-adaptive attention mechanism to capture the unique characteristics of different image modalities, enabling more effective representation learning compared to previous approaches.
- The authors evaluate ChAda-ViT on a multi-modal microscopy dataset, demonstrating its superior performance in cross-modal retrieval and classification tasks compared to state-of-the-art methods.
Plain English Explanation
The paper introduces a new deep learning model called ChAda-ViT, which stands for Channel Adaptive Vision Transformer. This model is designed to work with different types of microscopy images, such as those captured using various imaging techniques or from different samples.
Traditional deep learning models can struggle when faced with diverse image data, as they may not be able to effectively capture the unique characteristics of each image type. ChAda-ViT addresses this by incorporating a "channel-adaptive attention" mechanism, which allows the model to adapt its attention to the specific features of each image channel or modality.
By doing this, ChAda-ViT can learn more effective and versatile representations of the input data, which can then be used for tasks like cross-modal retrieval and classification. The authors demonstrate the effectiveness of their approach on a multi-modal microscopy dataset, showing that ChAda-ViT outperforms other state-of-the-art methods in these types of tasks.
Technical Explanation
The key innovation in ChAda-ViT is the incorporation of a channel-adaptive attention mechanism, which allows the model to dynamically adjust its attention to the unique characteristics of each image channel or modality. This is achieved by introducing a channel-wise attention module that learns channel-specific attention weights, which are then used to modulate the attention map computed by the standard Vision Transformer (ViT) [https://aimodels.fyi/papers/arxiv/fastervit-fast-vision-transformers-hierarchical-attention, https://aimodels.fyi/papers/arxiv/hsvit-horizontally-scalable-vision-transformer].
The authors hypothesize that this channel-adaptive attention approach can help the model better capture the diverse features present in heterogeneous microscopy images, leading to improved performance in cross-modal tasks [https://aimodels.fyi/papers/arxiv/vitgan-training-gans-vision-transformers]. They evaluate ChAda-ViT on a multi-modal microscopy dataset, comparing its performance to several state-of-the-art models in cross-modal retrieval and classification experiments.
The results show that ChAda-ViT outperforms the competing methods, demonstrating the effectiveness of the channel-adaptive attention mechanism in learning robust and transferable representations from diverse image data.
Critical Analysis
The authors provide a thorough evaluation of ChAda-ViT on the multi-modal microscopy dataset, including comparisons to various state-of-the-art models. However, the paper could have benefited from a more in-depth discussion of the limitations and potential drawbacks of the proposed approach.
For example, the authors do not explore how ChAda-ViT might scale to datasets with an even greater number of image modalities or channels. Additionally, the computational overhead of the channel-adaptive attention mechanism is not fully addressed, which could be an important consideration for real-world deployment.
Furthermore, the authors could have delved deeper into the interpretability of the channel-wise attention weights learned by ChAda-ViT, as this could provide valuable insights into the model's decision-making process and the relative importance of different image features for the target tasks.
Overall, the paper presents a compelling and well-executed approach to joint representation learning for heterogeneous microscopy images. However, the discussion of limitations and avenues for future research could be expanded to provide a more comprehensive understanding of the strengths and weaknesses of the ChAda-ViT model.
Conclusion
The ChAda-ViT model proposed in this paper represents a significant advancement in the field of multi-modal representation learning for microscopy imaging. By incorporating a channel-adaptive attention mechanism, the model is able to effectively capture the unique characteristics of diverse image data, leading to superior performance in cross-modal tasks compared to state-of-the-art methods.
The successful evaluation of ChAda-ViT on a multi-modal microscopy dataset suggests that the approach could have wide-ranging applications in various scientific and medical domains that rely on the analysis of heterogeneous imaging data. As the authors note, further research is needed to explore the scalability and interpretability of the model, but the current results are a promising step towards more robust and versatile deep learning solutions for complex visual data analysis tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
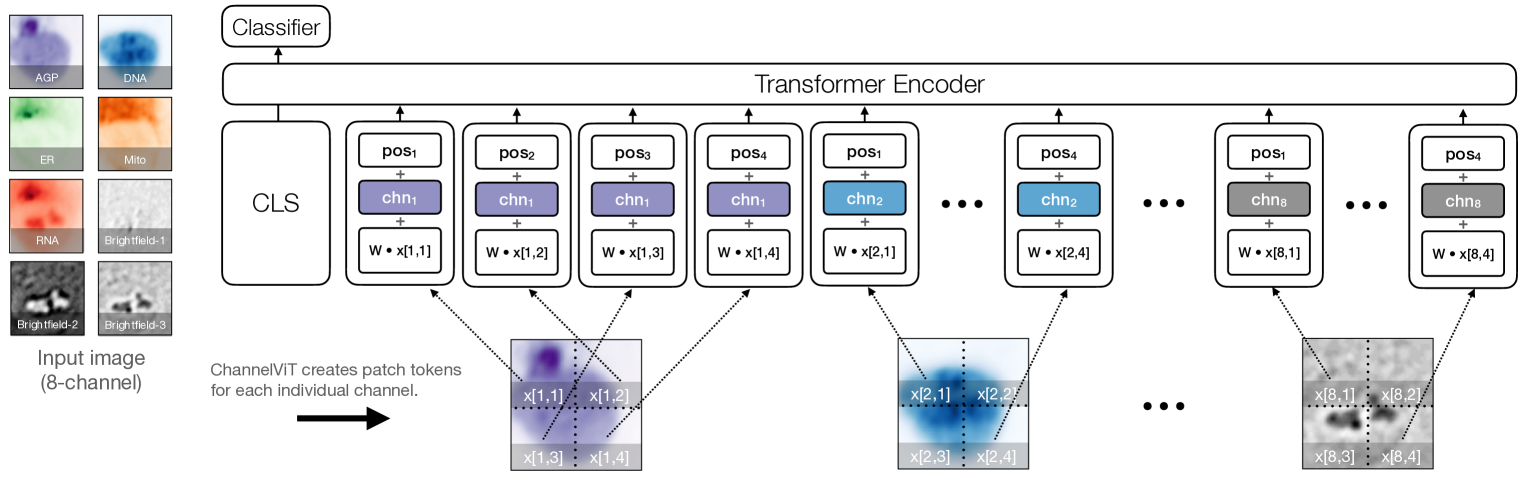
Channel Vision Transformers: An Image Is Worth 1 x 16 x 16 Words
Yujia Bao, Srinivasan Sivanandan, Theofanis Karaletsos
0
0
Vision Transformer (ViT) has emerged as a powerful architecture in the realm of modern computer vision. However, its application in certain imaging fields, such as microscopy and satellite imaging, presents unique challenges. In these domains, images often contain multiple channels, each carrying semantically distinct and independent information. Furthermore, the model must demonstrate robustness to sparsity in input channels, as they may not be densely available during training or testing. In this paper, we propose a modification to the ViT architecture that enhances reasoning across the input channels and introduce Hierarchical Channel Sampling (HCS) as an additional regularization technique to ensure robustness when only partial channels are presented during test time. Our proposed model, ChannelViT, constructs patch tokens independently from each input channel and utilizes a learnable channel embedding that is added to the patch tokens, similar to positional embeddings. We evaluate the performance of ChannelViT on ImageNet, JUMP-CP (microscopy cell imaging), and So2Sat (satellite imaging). Our results show that ChannelViT outperforms ViT on classification tasks and generalizes well, even when a subset of input channels is used during testing. Across our experiments, HCS proves to be a powerful regularizer, independent of the architecture employed, suggesting itself as a straightforward technique for robust ViT training. Lastly, we find that ChannelViT generalizes effectively even when there is limited access to all channels during training, highlighting its potential for multi-channel imaging under real-world conditions with sparse sensors. Our code is available at https://github.com/insitro/ChannelViT.
4/22/2024

Enhancing Feature Diversity Boosts Channel-Adaptive Vision Transformers
Chau Pham, Bryan A. Plummer
0
0
Multi-Channel Imaging (MCI) contains an array of challenges for encoding useful feature representations not present in traditional images. For example, images from two different satellites may both contain RGB channels, but the remaining channels can be different for each imaging source. Thus, MCI models must support a variety of channel configurations at test time. Recent work has extended traditional visual encoders for MCI, such as Vision Transformers (ViT), by supplementing pixel information with an encoding representing the channel configuration. However, these methods treat each channel equally, i.e., they do not consider the unique properties of each channel type, which can result in needless and potentially harmful redundancies in the learned features. For example, if RGB channels are always present, the other channels can focus on extracting information that cannot be captured by the RGB channels. To this end, we propose DiChaViT, which aims to enhance the diversity in the learned features of MCI-ViT models. This is achieved through a novel channel sampling strategy that encourages the selection of more distinct channel sets for training. Additionally, we employ regularization and initialization techniques to increase the likelihood that new information is learned from each channel. Many of our improvements are architecture agnostic and could be incorporated into new architectures as they are developed. Experiments on both satellite and cell microscopy datasets, CHAMMI, JUMP-CP, and So2Sat, report DiChaViT yields a 1.5-5.0% gain over the state-of-the-art.
5/28/2024
👀
FasterViT: Fast Vision Transformers with Hierarchical Attention
Ali Hatamizadeh, Greg Heinrich, Hongxu Yin, Andrew Tao, Jose M. Alvarez, Jan Kautz, Pavlo Molchanov
0
0
We design a new family of hybrid CNN-ViT neural networks, named FasterViT, with a focus on high image throughput for computer vision (CV) applications. FasterViT combines the benefits of fast local representation learning in CNNs and global modeling properties in ViT. Our newly introduced Hierarchical Attention (HAT) approach decomposes global self-attention with quadratic complexity into a multi-level attention with reduced computational costs. We benefit from efficient window-based self-attention. Each window has access to dedicated carrier tokens that participate in local and global representation learning. At a high level, global self-attentions enable the efficient cross-window communication at lower costs. FasterViT achieves a SOTA Pareto-front in terms of accuracy and image throughput. We have extensively validated its effectiveness on various CV tasks including classification, object detection and segmentation. We also show that HAT can be used as a plug-and-play module for existing networks and enhance them. We further demonstrate significantly faster and more accurate performance than competitive counterparts for images with high resolution. Code is available at https://github.com/NVlabs/FasterViT.
4/3/2024
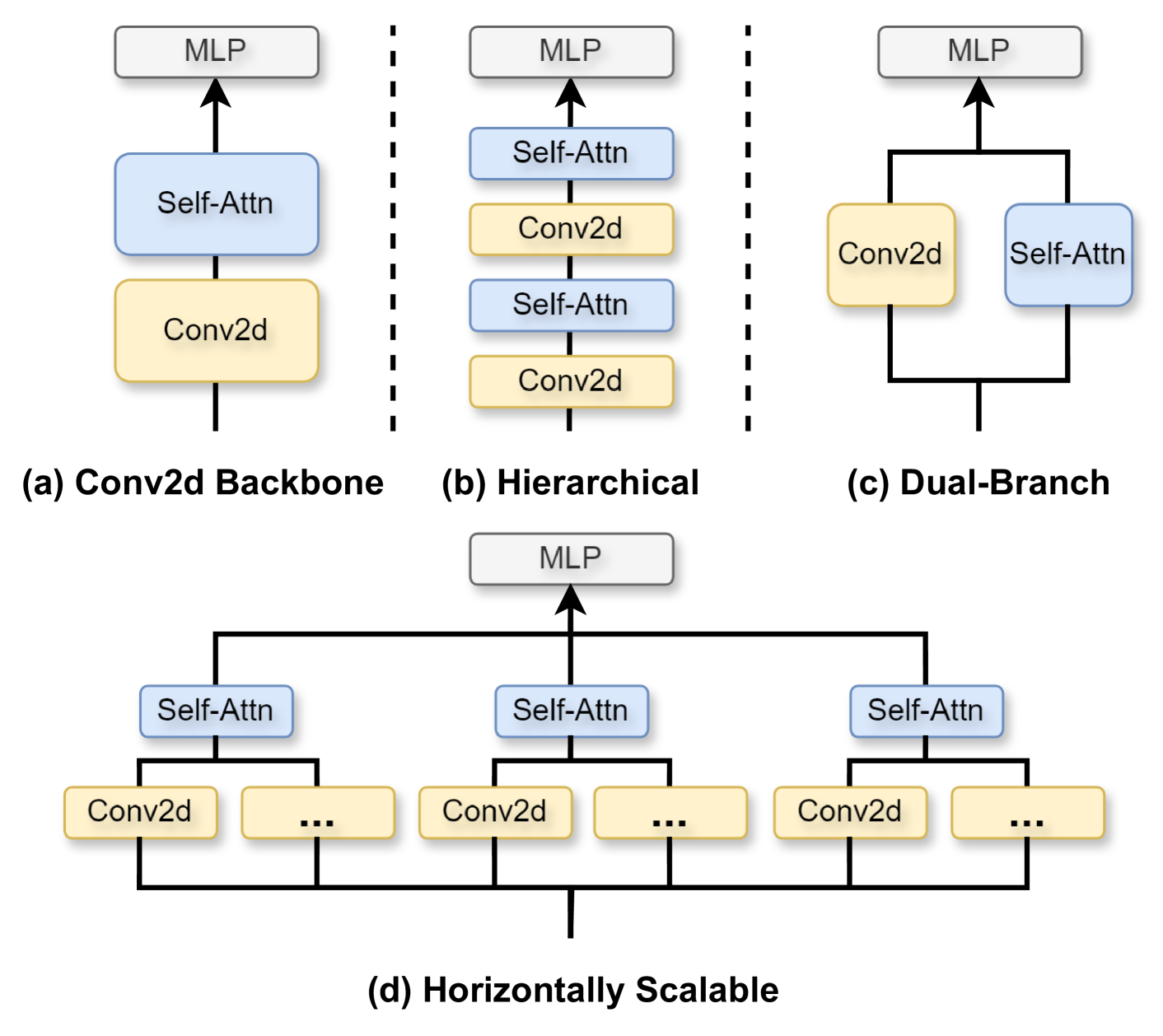
HSViT: Horizontally Scalable Vision Transformer
Chenhao Xu, Chang-Tsun Li, Chee Peng Lim, Douglas Creighton
0
0
While the Vision Transformer (ViT) architecture gains prominence in computer vision and attracts significant attention from multimedia communities, its deficiency in prior knowledge (inductive bias) regarding shift, scale, and rotational invariance necessitates pre-training on large-scale datasets. Furthermore, the growing layers and parameters in both ViT and convolutional neural networks (CNNs) impede their applicability to mobile multimedia services, primarily owing to the constrained computational resources on edge devices. To mitigate the aforementioned challenges, this paper introduces a novel horizontally scalable vision transformer (HSViT). Specifically, a novel image-level feature embedding allows ViT to better leverage the inductive bias inherent in the convolutional layers. Based on this, an innovative horizontally scalable architecture is designed, which reduces the number of layers and parameters of the models while facilitating collaborative training and inference of ViT models across multiple nodes. The experimental results depict that, without pre-training on large-scale datasets, HSViT achieves up to 10% higher top-1 accuracy than state-of-the-art schemes, ascertaining its superior preservation of inductive bias. The code is available at https://github.com/xuchenhao001/HSViT.
4/9/2024