Channel Vision Transformers: An Image Is Worth 1 x 16 x 16 Words
2309.16108
0
0
Abstract
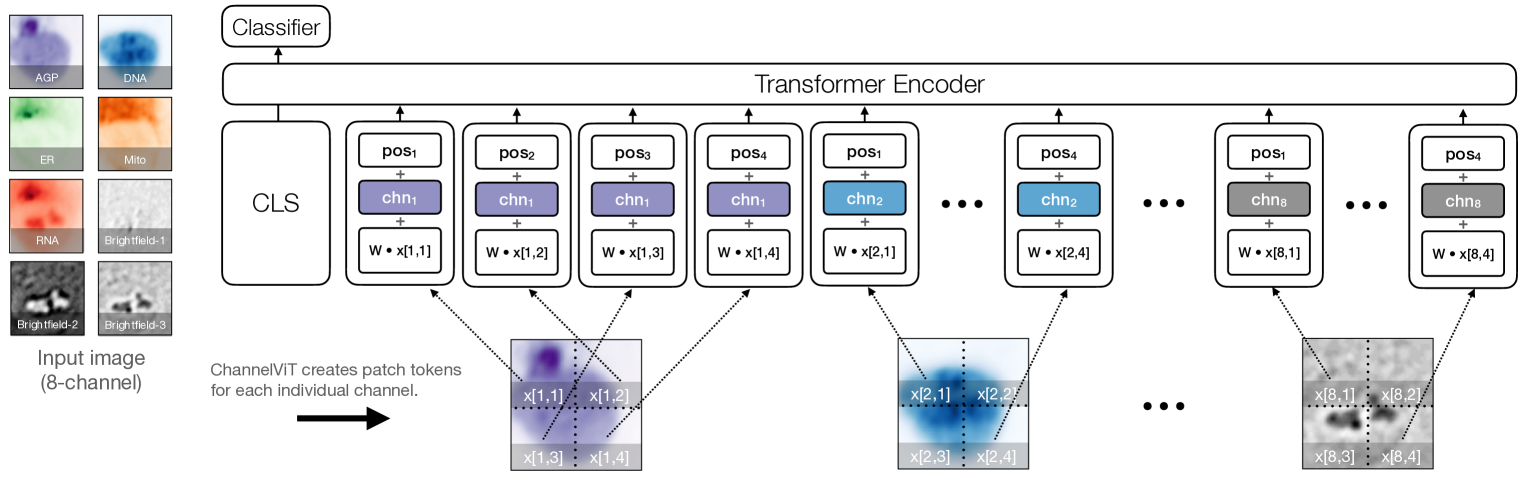
Vision Transformer (ViT) has emerged as a powerful architecture in the realm of modern computer vision. However, its application in certain imaging fields, such as microscopy and satellite imaging, presents unique challenges. In these domains, images often contain multiple channels, each carrying semantically distinct and independent information. Furthermore, the model must demonstrate robustness to sparsity in input channels, as they may not be densely available during training or testing. In this paper, we propose a modification to the ViT architecture that enhances reasoning across the input channels and introduce Hierarchical Channel Sampling (HCS) as an additional regularization technique to ensure robustness when only partial channels are presented during test time. Our proposed model, ChannelViT, constructs patch tokens independently from each input channel and utilizes a learnable channel embedding that is added to the patch tokens, similar to positional embeddings. We evaluate the performance of ChannelViT on ImageNet, JUMP-CP (microscopy cell imaging), and So2Sat (satellite imaging). Our results show that ChannelViT outperforms ViT on classification tasks and generalizes well, even when a subset of input channels is used during testing. Across our experiments, HCS proves to be a powerful regularizer, independent of the architecture employed, suggesting itself as a straightforward technique for robust ViT training. Lastly, we find that ChannelViT generalizes effectively even when there is limited access to all channels during training, highlighting its potential for multi-channel imaging under real-world conditions with sparse sensors. Our code is available at https://github.com/insitro/ChannelViT.
Create account to get full access
Overview
- Presents a novel "Channel Vision Transformer" architecture that uses channel information to improve the performance of vision transformers
- Demonstrates the effectiveness of the proposed model on various computer vision tasks, including image classification, object detection, and semantic segmentation
- Provides insights into the importance of incorporating channel information into vision transformer models
Plain English Explanation
The paper introduces a new type of vision transformer model called the Channel Vision Transformer (CVT). Traditional vision transformers process images as a sequence of pixel patches, treating each patch as a separate entity. In contrast, the CVT model takes into account the
By incorporating this channel information, the CVT model is able to better capture the relationships and dependencies between different parts of the image. This allows the model to learn more meaningful and powerful representations, leading to improved performance on a variety of computer vision tasks, such as image classification, object detection, and semantic segmentation.
The researchers demonstrate the effectiveness of the CVT model through extensive experiments, showing that it outperforms traditional vision transformer models on several benchmark datasets. The key insight is that the channel information provides an additional signal that can help the model better understand the structure and semantics of the input images.
Technical Explanation
The Channel Vision Transformer (CVT) proposed in this paper is an extension of the standard vision transformer architecture. Instead of treating each image patch as an independent entity, the CVT model explicitly incorporates the
This is achieved by introducing a new "channel-wise attention" mechanism, which allows the model to attend to the different channels of the image simultaneously. The channel-wise attention is combined with the standard spatial attention used in vision transformers, enabling the model to capture both spatial and channel-wise dependencies.
The researchers also introduce several other architectural innovations, such as a hierarchical structure inspired by ViTAMIN and a "fast" attention mechanism inspired by FasterViT. These modifications help to improve the efficiency and scalability of the CVT model, allowing it to be applied to a wide range of computer vision tasks.
The experimental results demonstrate the superiority of the CVT model compared to standard vision transformers across various benchmarks. The authors attribute this performance boost to the model's ability to effectively leverage the channel information, which provides a richer and more informative representation of the input images.
Critical Analysis
The paper presents a well-designed and thorough study, with extensive experiments and clear insights. However, there are a few potential limitations and areas for further research:
-
The paper does not provide a detailed analysis of the computational complexity and inference speed of the CVT model. While the proposed architectural innovations are claimed to improve efficiency, a more comprehensive evaluation of the trade-offs between performance and computational cost would be valuable.
-
The experiments are primarily focused on standard computer vision tasks, such as image classification and object detection. It would be interesting to see how the CVT model performs on more challenging or domain-specific tasks, where the channel information may play an even more crucial role.
-
The paper does not discuss the potential interpretability or explainability of the CVT model. Understanding how the channel-wise attention mechanism contributes to the model's decision-making process could provide valuable insights and make the model more transparent.
-
The proposed approach could potentially be extended to other types of visual data beyond natural images, such as medical imaging or remote sensing data, where the channel information may be even more crucial for accurate analysis.
Overall, the Channel Vision Transformer represents a promising step forward in the development of more powerful and efficient vision transformer models, and the ideas presented in this paper could inspire further research and innovation in the field of computer vision.
Conclusion
The Channel Vision Transformer (CVT) proposed in this paper demonstrates the importance of incorporating channel information into vision transformer models. By explicitly modeling the relationships between different channels of the input image, the CVT model is able to achieve superior performance on a range of computer vision tasks compared to standard vision transformers.
The key insight is that the channel information provides an additional signal that can help the model better understand the structure and semantics of the input data. The architectural innovations introduced in the CVT, such as the channel-wise attention mechanism and the hierarchical structure, allow the model to effectively leverage this channel information and achieve state-of-the-art results.
The findings of this paper suggest that future developments in vision transformer architectures should consider the importance of channel information, and explore ways to better integrate this signal into the model's representation and decision-making processes. This could lead to even more powerful and versatile computer vision systems that are better equipped to handle the rich and complex visual data encountered in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Enhancing Feature Diversity Boosts Channel-Adaptive Vision Transformers
Chau Pham, Bryan A. Plummer
0
0
Multi-Channel Imaging (MCI) contains an array of challenges for encoding useful feature representations not present in traditional images. For example, images from two different satellites may both contain RGB channels, but the remaining channels can be different for each imaging source. Thus, MCI models must support a variety of channel configurations at test time. Recent work has extended traditional visual encoders for MCI, such as Vision Transformers (ViT), by supplementing pixel information with an encoding representing the channel configuration. However, these methods treat each channel equally, i.e., they do not consider the unique properties of each channel type, which can result in needless and potentially harmful redundancies in the learned features. For example, if RGB channels are always present, the other channels can focus on extracting information that cannot be captured by the RGB channels. To this end, we propose DiChaViT, which aims to enhance the diversity in the learned features of MCI-ViT models. This is achieved through a novel channel sampling strategy that encourages the selection of more distinct channel sets for training. Additionally, we employ regularization and initialization techniques to increase the likelihood that new information is learned from each channel. Many of our improvements are architecture agnostic and could be incorporated into new architectures as they are developed. Experiments on both satellite and cell microscopy datasets, CHAMMI, JUMP-CP, and So2Sat, report DiChaViT yields a 1.5-5.0% gain over the state-of-the-art.
5/28/2024
HSViT: Horizontally Scalable Vision Transformer
Chenhao Xu, Chang-Tsun Li, Chee Peng Lim, Douglas Creighton
0
0
While the Vision Transformer (ViT) architecture gains prominence in computer vision and attracts significant attention from multimedia communities, its deficiency in prior knowledge (inductive bias) regarding shift, scale, and rotational invariance necessitates pre-training on large-scale datasets. Furthermore, the growing layers and parameters in both ViT and convolutional neural networks (CNNs) impede their applicability to mobile multimedia services, primarily owing to the constrained computational resources on edge devices. To mitigate the aforementioned challenges, this paper introduces a novel horizontally scalable vision transformer (HSViT). Specifically, a novel image-level feature embedding allows ViT to better leverage the inductive bias inherent in the convolutional layers. Based on this, an innovative horizontally scalable architecture is designed, which reduces the number of layers and parameters of the models while facilitating collaborative training and inference of ViT models across multiple nodes. The experimental results depict that, without pre-training on large-scale datasets, HSViT achieves up to 10% higher top-1 accuracy than state-of-the-art schemes, ascertaining its superior preservation of inductive bias. The code is available at https://github.com/xuchenhao001/HSViT.
4/9/2024

ChAda-ViT : Channel Adaptive Attention for Joint Representation Learning of Heterogeneous Microscopy Images
Nicolas Bourriez, Ihab Bendidi, Ethan Cohen, Gabriel Watkinson, Maxime Sanchez, Guillaume Bollot, Auguste Genovesio
0
0
Unlike color photography images, which are consistently encoded into RGB channels, biological images encompass various modalities, where the type of microscopy and the meaning of each channel varies with each experiment. Importantly, the number of channels can range from one to a dozen and their correlation is often comparatively much lower than RGB, as each of them brings specific information content. This aspect is largely overlooked by methods designed out of the bioimage field, and current solutions mostly focus on intra-channel spatial attention, often ignoring the relationship between channels, yet crucial in most biological applications. Importantly, the variable channel type and count prevent the projection of several experiments to a unified representation for large scale pre-training. In this study, we propose ChAda-ViT, a novel Channel Adaptive Vision Transformer architecture employing an Inter-Channel Attention mechanism on images with an arbitrary number, order and type of channels. We also introduce IDRCell100k, a bioimage dataset with a rich set of 79 experiments covering 7 microscope modalities, with a multitude of channel types, and counts varying from 1 to 10 per experiment. Our architecture, trained in a self-supervised manner, outperforms existing approaches in several biologically relevant downstream tasks. Additionally, it can be used to bridge the gap for the first time between assays with different microscopes, channel numbers or types by embedding various image and experimental modalities into a unified biological image representation. The latter should facilitate interdisciplinary studies and pave the way for better adoption of deep learning in biological image-based analyses. Code and Data available at https://github.com/nicoboou/chadavit.
6/4/2024

Sub-token ViT Embedding via Stochastic Resonance Transformers
Dong Lao, Yangchao Wu, Tian Yu Liu, Alex Wong, Stefano Soatto
0
0
Vision Transformer (ViT) architectures represent images as collections of high-dimensional vectorized tokens, each corresponding to a rectangular non-overlapping patch. This representation trades spatial granularity for embedding dimensionality, and results in semantically rich but spatially coarsely quantized feature maps. In order to retrieve spatial details beneficial to fine-grained inference tasks we propose a training-free method inspired by stochastic resonance. Specifically, we perform sub-token spatial transformations to the input data, and aggregate the resulting ViT features after applying the inverse transformation. The resulting Stochastic Resonance Transformer (SRT) retains the rich semantic information of the original representation, but grounds it on a finer-scale spatial domain, partly mitigating the coarse effect of spatial tokenization. SRT is applicable across any layer of any ViT architecture, consistently boosting performance on several tasks including segmentation, classification, depth estimation, and others by up to 14.9% without the need for any fine-tuning.
5/8/2024