Character is Destiny: Can Large Language Models Simulate Persona-Driven Decisions in Role-Playing?
2404.12138
0
0
Abstract
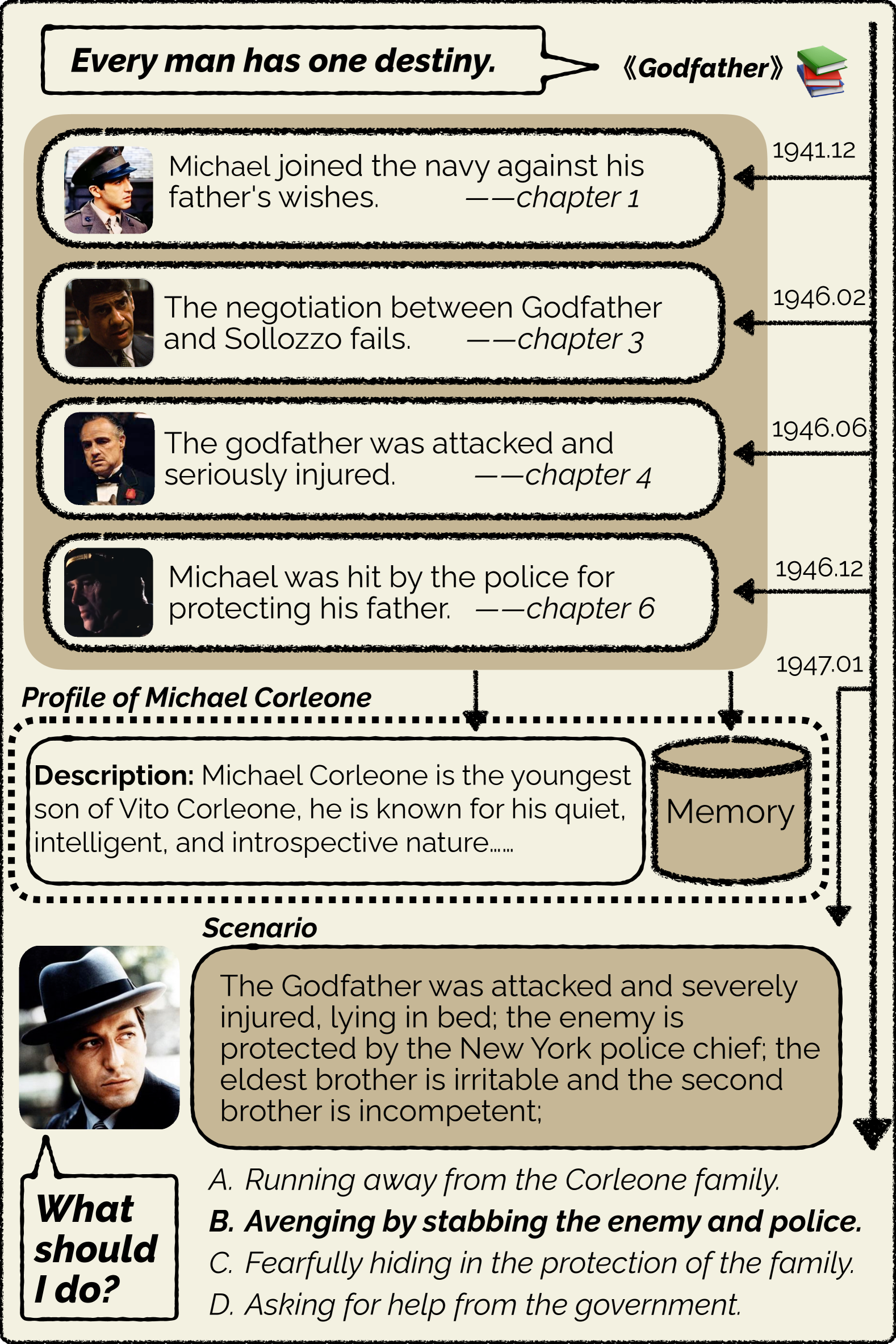
Can Large Language Models substitute humans in making important decisions? Recent research has unveiled the potential of LLMs to role-play assigned personas, mimicking their knowledge and linguistic habits. However, imitative decision-making requires a more nuanced understanding of personas. In this paper, we benchmark the ability of LLMs in persona-driven decision-making. Specifically, we investigate whether LLMs can predict characters' decisions provided with the preceding stories in high-quality novels. Leveraging character analyses written by literary experts, we construct a dataset LIFECHOICE comprising 1,401 character decision points from 395 books. Then, we conduct comprehensive experiments on LIFECHOICE, with various LLMs and methods for LLM role-playing. The results demonstrate that state-of-the-art LLMs exhibit promising capabilities in this task, yet there is substantial room for improvement. Hence, we further propose the CHARMAP method, which achieves a 6.01% increase in accuracy via persona-based memory retrieval. We will make our datasets and code publicly available.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Explores the ability of large language models (LLMs) to simulate persona-driven decision-making in role-playing scenarios
- Investigates whether LLMs can accurately portray specific character personalities and make consequential decisions based on those personas
- Provides insights into the broader potential of LLMs to assist in creative and interactive media, such as virtual agents and interactive narratives
Plain English Explanation
This research paper examines whether large language models (LLMs) - the powerful AI systems that can generate human-like text - can effectively simulate the decision-making of specific characters in role-playing scenarios. The key question is: can these AI models accurately capture the personality, motivations, and decision-making processes of distinct personas, and use that to guide their choices in a plausible way?
The researchers are interested in understanding the potential of LLMs to assist in the creation of interactive media, such as virtual agents or branching narratives, where the ability to convincingly embody different character archetypes is crucial. By testing the limits of LLMs in this area, the study aims to shed light on how these advanced AI systems could be leveraged to enhance creative endeavors and interactive experiences.
Technical Explanation
The research paper explores the capacity of large language models (LLMs) to simulate persona-driven decision-making in role-playing contexts. The authors investigate whether LLMs can accurately capture the unique personality traits, motivations, and decision-making processes of distinct character archetypes, and then use that understanding to guide their choices in a plausible and coherent manner.
To assess this, the researchers designed experiments where LLMs were tasked with making decisions on behalf of specific character personas in a role-playing scenario. The LLMs were first provided with detailed character profiles that outlined the personality, backstory, and values of the personas. They were then presented with a series of narrative situations and asked to make choices that aligned with the established character traits.
The study analyzed the LLMs' ability to maintain a consistent persona-driven decision-making process throughout the scenarios, as well as the overall plausibility and coherence of the choices made. The findings provide insights into the potential of LLMs to assist in the creation of interactive media, such as virtual agents or branching narratives, where the authentic embodiment of diverse character archetypes is crucial to the user experience.
Critical Analysis
The research presented in this paper offers valuable insights into the capabilities and limitations of large language models (LLMs) when it comes to simulating persona-driven decision-making in role-playing scenarios. The authors acknowledge that while LLMs have shown impressive language generation abilities, their capacity to truly capture the nuances of distinct character personas and make consequential decisions based on those personas remains an open question.
One potential limitation highlighted in the paper is the challenge of ensuring consistent persona-driven decision-making over the course of an extended narrative or series of interactions. The researchers note that LLMs may struggle to maintain a coherent and plausible portrayal of a character's personality, motivations, and decision-making processes, especially in more complex or ambiguous situations.
Additionally, the paper suggests that further research is needed to explore the ethical implications of using LLMs to simulate human-like decision-making, particularly in interactive media where users may form meaningful connections with the virtual characters. Considerations around transparency, accountability, and the potential for unintended consequences should be carefully examined.
Conclusion
This research paper provides an insightful exploration of the ability of large language models (LLMs) to simulate persona-driven decision-making in role-playing scenarios. The findings suggest that while LLMs have made significant advancements in language generation, their capacity to convincingly embody distinct character archetypes and make consequential decisions aligned with those personas remains an area that requires further investigation.
The potential implications of this research extend beyond just character simulation, as the insights gained could inform the development of more sophisticated virtual agents, interactive narratives, and other creative applications that rely on the authentic portrayal of diverse personas. By continuing to push the boundaries of LLM capabilities in this domain, researchers can contribute to the ongoing evolution of these powerful AI systems and their potential to enhance human-centric experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
PersonaLLM: Investigating the Ability of Large Language Models to Express Personality Traits
Hang Jiang, Xiajie Zhang, Xubo Cao, Cynthia Breazeal, Deb Roy, Jad Kabbara
0
0
Despite the many use cases for large language models (LLMs) in creating personalized chatbots, there has been limited research on evaluating the extent to which the behaviors of personalized LLMs accurately and consistently reflect specific personality traits. We consider studying the behavior of LLM-based agents which we refer to as LLM personas and present a case study with GPT-3.5 and GPT-4 to investigate whether LLMs can generate content that aligns with their assigned personality profiles. To this end, we simulate distinct LLM personas based on the Big Five personality model, have them complete the 44-item Big Five Inventory (BFI) personality test and a story writing task, and then assess their essays with automatic and human evaluations. Results show that LLM personas' self-reported BFI scores are consistent with their designated personality types, with large effect sizes observed across five traits. Additionally, LLM personas' writings have emerging representative linguistic patterns for personality traits when compared with a human writing corpus. Furthermore, human evaluation shows that humans can perceive some personality traits with an accuracy of up to 80%. Interestingly, the accuracy drops significantly when the annotators were informed of AI authorship.
4/3/2024

How Well Can LLMs Echo Us? Evaluating AI Chatbots' Role-Play Ability with ECHO
Man Tik Ng, Hui Tung Tse, Jen-tse Huang, Jingjing Li, Wenxuan Wang, Michael R. Lyu
0
0
The role-play ability of Large Language Models (LLMs) has emerged as a popular research direction. However, existing studies focus on imitating well-known public figures or fictional characters, overlooking the potential for simulating ordinary individuals. Such an oversight limits the potential for advancements in digital human clones and non-player characters in video games. To bridge this gap, we introduce ECHO, an evaluative framework inspired by the Turing test. This framework engages the acquaintances of the target individuals to distinguish between human and machine-generated responses. Notably, our framework focuses on emulating average individuals rather than historical or fictional figures, presenting a unique advantage to apply the Turing Test. We evaluated three role-playing LLMs using ECHO, with GPT-3.5 and GPT-4 serving as foundational models, alongside the online application GPTs from OpenAI. Our results demonstrate that GPT-4 more effectively deceives human evaluators, and GPTs achieves a leading success rate of 48.3%. Furthermore, we investigated whether LLMs could discern between human-generated and machine-generated texts. While GPT-4 can identify differences, it could not determine which texts were human-produced. Our code and results of reproducing the role-playing LLMs are made publicly available via https://github.com/CUHK-ARISE/ECHO.
4/23/2024
🏷️
Limited Ability of LLMs to Simulate Human Psychological Behaviours: a Psychometric Analysis
Nikolay B Petrov, Gregory Serapio-Garc'ia, Jason Rentfrow
0
0
The humanlike responses of large language models (LLMs) have prompted social scientists to investigate whether LLMs can be used to simulate human participants in experiments, opinion polls and surveys. Of central interest in this line of research has been mapping out the psychological profiles of LLMs by prompting them to respond to standardized questionnaires. The conflicting findings of this research are unsurprising given that mapping out underlying, or latent, traits from LLMs' text responses to questionnaires is no easy task. To address this, we use psychometrics, the science of psychological measurement. In this study, we prompt OpenAI's flagship models, GPT-3.5 and GPT-4, to assume different personas and respond to a range of standardized measures of personality constructs. We used two kinds of persona descriptions: either generic (four or five random person descriptions) or specific (mostly demographics of actual humans from a large-scale human dataset). We found that the responses from GPT-4, but not GPT-3.5, using generic persona descriptions show promising, albeit not perfect, psychometric properties, similar to human norms, but the data from both LLMs when using specific demographic profiles, show poor psychometrics properties. We conclude that, currently, when LLMs are asked to simulate silicon personas, their responses are poor signals of potentially underlying latent traits. Thus, our work casts doubt on LLMs' ability to simulate individual-level human behaviour across multiple-choice question answering tasks.
5/14/2024
🤔
Evaluating Character Understanding of Large Language Models via Character Profiling from Fictional Works
Xinfeng Yuan, Siyu Yuan, Yuhan Cui, Tianhe Lin, Xintao Wang, Rui Xu, Jiangjie Chen, Deqing Yang
0
0
Large language models (LLMs) have demonstrated impressive performance and spurred numerous AI applications, in which role-playing agents (RPAs) are particularly popular, especially for fictional characters. The prerequisite for these RPAs lies in the capability of LLMs to understand characters from fictional works. Previous efforts have evaluated this capability via basic classification tasks or characteristic imitation, failing to capture the nuanced character understanding with LLMs. In this paper, we propose evaluating LLMs' character understanding capability via the character profiling task, i.e., summarizing character profiles from corresponding materials, a widely adopted yet understudied practice for RPA development. Specifically, we construct the CroSS dataset from literature experts and assess the generated profiles by comparing ground truth references and their applicability in downstream tasks. Our experiments, which cover various summarization methods and LLMs, have yielded promising results. These results strongly validate the character understanding capability of LLMs. We believe our constructed resource will promote further research in this field. Resources are available at https://github.com/Joanna0123/character_profiling.
4/22/2024