How Well Can LLMs Echo Us? Evaluating AI Chatbots' Role-Play Ability with ECHO
2404.13957
0
0

Abstract
The role-play ability of Large Language Models (LLMs) has emerged as a popular research direction. However, existing studies focus on imitating well-known public figures or fictional characters, overlooking the potential for simulating ordinary individuals. Such an oversight limits the potential for advancements in digital human clones and non-player characters in video games. To bridge this gap, we introduce ECHO, an evaluative framework inspired by the Turing test. This framework engages the acquaintances of the target individuals to distinguish between human and machine-generated responses. Notably, our framework focuses on emulating average individuals rather than historical or fictional figures, presenting a unique advantage to apply the Turing Test. We evaluated three role-playing LLMs using ECHO, with GPT-3.5 and GPT-4 serving as foundational models, alongside the online application GPTs from OpenAI. Our results demonstrate that GPT-4 more effectively deceives human evaluators, and GPTs achieves a leading success rate of 48.3%. Furthermore, we investigated whether LLMs could discern between human-generated and machine-generated texts. While GPT-4 can identify differences, it could not determine which texts were human-produced. Our code and results of reproducing the role-playing LLMs are made publicly available via https://github.com/CUHK-ARISE/ECHO.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper evaluates the ability of large language models (LLMs) to engage in role-playing and echo human conversations, using a new evaluation framework called ECHO.
- The researchers explore whether LLMs can convincingly assume different personas and maintain coherent, context-appropriate dialogues, which has implications for the development of more natural and engaging AI chatbots.
- The paper presents the ECHO framework, which assesses an AI's ability to roleplay across a range of conversational scenarios, and reports the results of experiments applying ECHO to several prominent LLMs.
Plain English Explanation
The paper examines how well large AI language models, like those used in chatbots, can step into different roles and have natural-sounding conversations that mimic human interactions. The researchers developed a new testing framework called ECHO to evaluate an AI's ability to roleplay across various scenarios.
The key idea is that for AI chatbots to be more engaging and lifelike, they need to be able to convincingly adopt different personas and maintain coherent, context-appropriate dialogues, rather than just providing generic responses. The ECHO framework allows the researchers to assess how well prominent language models can assume different identities and converse accordingly.
By applying ECHO to several leading AI systems, the paper provides insights into the current state of role-playing capabilities in language models. This has important implications for the development of more natural and human-like AI assistants and chatbots in the future.
Technical Explanation
The paper introduces the ECHO ([object Object],valuation of ,[object Object],onversational ,[object Object],uman-likeness of ,[object Object],utputs) framework for assessing an AI system's ability to engage in role-play and echo human conversational patterns. ECHO involves presenting language models with a variety of conversational scenarios, each with a defined persona, and evaluating the coherence and context-appropriateness of the model's responses.
The researchers applied ECHO to several prominent large language models, including GPT-3, InstructGPT, and ChatGPT, to gauge their role-playing capabilities. The experiments involved defining personas with distinct backgrounds, personalities, and communication styles, and then evaluating the models' ability to maintain coherent, context-appropriate dialogues when assuming those personas.
The paper presents the results of these ECHO evaluations, providing insights into the current strengths and limitations of LLMs in terms of role-playing and echoing human-like conversations. The findings highlight areas where language models excel at adopting personas and maintaining coherence, as well as situations where their responses fall short of human-level performance.
Critical Analysis
The paper offers a comprehensive and well-designed framework for evaluating the role-playing abilities of large language models, which is a crucial aspect of developing more natural and engaging AI chatbots. However, the researchers acknowledge several limitations and areas for further exploration.
One potential limitation is the scope of the conversational scenarios and personas used in the ECHO evaluation. While the researchers aimed to cover a diverse range of situations, it's possible that the models may perform differently in even more complex or nuanced conversational contexts. Additionally, the paper does not address potential biases or inconsistencies in the models' responses when assuming different personas, which could be an important consideration for real-world applications.
Further research could explore the role-playing capabilities of language models in more open-ended, interactive dialogues, where the models would need to dynamically adapt their personas and responses based on the flow of the conversation. Investigating the models' ability to maintain coherent, long-term persona-based dialogues could also yield valuable insights.
Overall, the ECHO framework and the findings presented in this paper represent an important step forward in understanding the current state of role-playing capabilities in large language models, and provide a solid foundation for further advancements in the development of more natural and human-like AI chatbots.
Conclusion
This paper introduces the ECHO framework, a novel approach for evaluating the role-playing abilities of large language models. The researchers applied ECHO to several prominent LLMs, including GPT-3, InstructGPT, and ChatGPT, to assess their capacity to assume different personas and engage in coherent, context-appropriate dialogues.
The results provide valuable insights into the current strengths and limitations of language models in terms of role-playing and echoing human-like conversations. While the models demonstrated some proficiency in adopting personas and maintaining coherence, the paper also highlights areas where their performance falls short of human-level conversational abilities.
These findings have important implications for the ongoing development of more natural and engaging AI chatbots. By understanding the role-playing capabilities of language models, researchers and developers can work towards creating AI assistants that can more convincingly step into different roles and have more lifelike, interactive dialogues with users. The ECHO framework offers a promising tool for further exploring and advancing this crucial aspect of AI conversational abilities.
Related Papers
📉
DialogBench: Evaluating LLMs as Human-like Dialogue Systems
Jiao Ou, Junda Lu, Che Liu, Yihong Tang, Fuzheng Zhang, Di Zhang, Kun Gai
0
0
Large language models (LLMs) have achieved remarkable breakthroughs in new dialogue capabilities by leveraging instruction tuning, which refreshes human impressions of dialogue systems. The long-standing goal of dialogue systems is to be human-like enough to establish long-term connections with users. Therefore, there has been an urgent need to evaluate LLMs as human-like dialogue systems. In this paper, we propose DialogBench, a dialogue evaluation benchmark that contains 12 dialogue tasks to probe the capabilities of LLMs as human-like dialogue systems should have. Specifically, we prompt GPT-4 to generate evaluation instances for each task. We first design the basic prompt based on widely used design principles and further mitigate the existing biases to generate higher-quality evaluation instances. Our extensive tests on English and Chinese DialogBench of 26 LLMs show that instruction tuning improves the human likeness of LLMs to a certain extent, but most LLMs still have much room for improvement as human-like dialogue systems. Interestingly, results also show that the positioning of assistant AI can make instruction tuning weaken the human emotional perception of LLMs and their mastery of information about human daily life.
4/1/2024
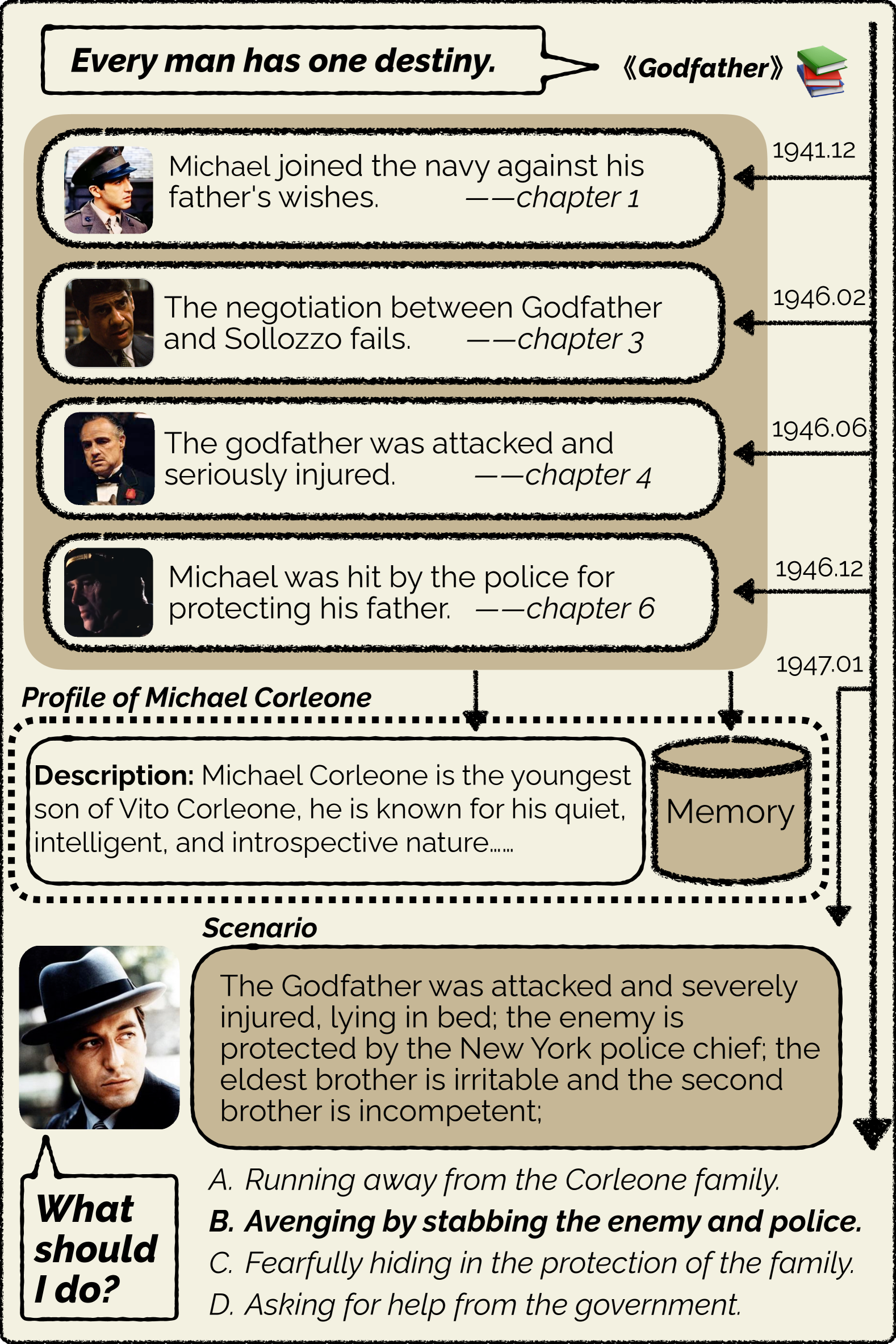
Character is Destiny: Can Large Language Models Simulate Persona-Driven Decisions in Role-Playing?
Rui Xu, Xintao Wang, Jiangjie Chen, Siyu Yuan, Xinfeng Yuan, Jiaqing Liang, Zulong Chen, Xiaoqing Dong, Yanghua Xiao
0
0
Can Large Language Models substitute humans in making important decisions? Recent research has unveiled the potential of LLMs to role-play assigned personas, mimicking their knowledge and linguistic habits. However, imitative decision-making requires a more nuanced understanding of personas. In this paper, we benchmark the ability of LLMs in persona-driven decision-making. Specifically, we investigate whether LLMs can predict characters' decisions provided with the preceding stories in high-quality novels. Leveraging character analyses written by literary experts, we construct a dataset LIFECHOICE comprising 1,401 character decision points from 395 books. Then, we conduct comprehensive experiments on LIFECHOICE, with various LLMs and methods for LLM role-playing. The results demonstrate that state-of-the-art LLMs exhibit promising capabilities in this task, yet there is substantial room for improvement. Hence, we further propose the CHARMAP method, which achieves a 6.01% increase in accuracy via persona-based memory retrieval. We will make our datasets and code publicly available.
4/19/2024

Is this the real life? Is this just fantasy? The Misleading Success of Simulating Social Interactions With LLMs
Xuhui Zhou, Zhe Su, Tiwalayo Eisape, Hyunwoo Kim, Maarten Sap
0
0
Recent advances in large language models (LLM) have enabled richer social simulations, allowing for the study of various social phenomena. However, most recent work has used a more omniscient perspective on these simulations (e.g., single LLM to generate all interlocutors), which is fundamentally at odds with the non-omniscient, information asymmetric interactions that involve humans and AI agents in the real world. To examine these differences, we develop an evaluation framework to simulate social interactions with LLMs in various settings (omniscient, non-omniscient). Our experiments show that LLMs perform better in unrealistic, omniscient simulation settings but struggle in ones that more accurately reflect real-world conditions with information asymmetry. Our findings indicate that addressing information asymmetry remains a fundamental challenge for LLM-based agents.
4/22/2024

Evaluation of LLM Chatbots for OSINT-based Cyber Threat Awareness
Samaneh Shafee, Alysson Bessani, Pedro M. Ferreira
0
0
Knowledge sharing about emerging threats is crucial in the rapidly advancing field of cybersecurity and forms the foundation of Cyber Threat Intelligence (CTI). In this context, Large Language Models are becoming increasingly significant in the field of cybersecurity, presenting a wide range of opportunities. This study surveys the performance of ChatGPT, GPT4all, Dolly, Stanford Alpaca, Alpaca-LoRA, Falcon, and Vicuna chatbots in binary classification and Named Entity Recognition (NER) tasks performed using Open Source INTelligence (OSINT). We utilize well-established data collected in previous research from Twitter to assess the competitiveness of these chatbots when compared to specialized models trained for those tasks. In binary classification experiments, Chatbot GPT-4 as a commercial model achieved an acceptable F1 score of 0.94, and the open-source GPT4all model achieved an F1 score of 0.90. However, concerning cybersecurity entity recognition, all evaluated chatbots have limitations and are less effective. This study demonstrates the capability of chatbots for OSINT binary classification and shows that they require further improvement in NER to effectively replace specially trained models. Our results shed light on the limitations of the LLM chatbots when compared to specialized models, and can help researchers improve chatbots technology with the objective to reduce the required effort to integrate machine learning in OSINT-based CTI tools.
4/22/2024