PersonaLLM: Investigating the Ability of Large Language Models to Express Personality Traits
2305.02547
1
0
💬
Abstract
Despite the many use cases for large language models (LLMs) in creating personalized chatbots, there has been limited research on evaluating the extent to which the behaviors of personalized LLMs accurately and consistently reflect specific personality traits. We consider studying the behavior of LLM-based agents which we refer to as LLM personas and present a case study with GPT-3.5 and GPT-4 to investigate whether LLMs can generate content that aligns with their assigned personality profiles. To this end, we simulate distinct LLM personas based on the Big Five personality model, have them complete the 44-item Big Five Inventory (BFI) personality test and a story writing task, and then assess their essays with automatic and human evaluations. Results show that LLM personas' self-reported BFI scores are consistent with their designated personality types, with large effect sizes observed across five traits. Additionally, LLM personas' writings have emerging representative linguistic patterns for personality traits when compared with a human writing corpus. Furthermore, human evaluation shows that humans can perceive some personality traits with an accuracy of up to 80%. Interestingly, the accuracy drops significantly when the annotators were informed of AI authorship.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Researchers investigated whether large language models (LLMs) can generate content that accurately reflects specific personality traits.
- They simulated distinct LLM personas based on the Big Five personality model, had them take a personality test and complete a story writing task, then evaluated the results.
- The study found that LLM personas' self-reported personality scores matched their designated types, and their writings showed representative linguistic patterns.
- Human evaluators could accurately perceive some personality traits in the LLM-generated writings, but this accuracy decreased when they were told the content was AI-authored.
Plain English Explanation
Chatbots and AI assistants are becoming increasingly common, and they are often designed to have their own unique personalities. However, there hasn't been much research on whether the behaviors of these personalized AI systems truly reflect the personality traits they are meant to embody.
In this study, the researchers wanted to see if large language models (LLMs) - powerful AI systems that can generate human-like text - could be used to create AI personas with distinct personality profiles. They imagined a scenario where an LLM could be imbued with a specific personality, like an extroverted, creative writer or an introverted, analytical thinker.
To test this, the researchers simulated different LLM personas based on the "Big Five" personality traits (openness, conscientiousness, extraversion, agreeableness, and neuroticism). They had these LLM personas take a standard personality test and then write a short story. The researchers then analyzed the test results and story content to see if the LLM personas' behaviors matched their assigned personalities.
The results showed that the LLM personas' self-reported personality scores aligned with their designated traits, and the language they used in their stories also reflected their assigned personalities. In other words, the LLM-based personas were able to convincingly embody the personality profiles they were given.
Interestingly, when human evaluators were shown the LLM-generated stories, they were able to accurately identify some of the personality traits. However, this accuracy dropped significantly when the evaluators were told the stories were written by AI rather than humans.
This study suggests that LLMs have the potential to be used to create AI assistants and chatbots with believable, consistent personalities. But it also highlights the need for further research on how users perceive and interact with these AI personas, especially when they know the content is generated by a machine.
Technical Explanation
The researchers in this study investigated the extent to which the behaviors of personalized large language models (LLMs) accurately and consistently reflect specific personality traits. They refer to these LLM-based agents as "LLM personas."
To simulate distinct LLM personas, the researchers based them on the Big Five personality model, which describes personality in terms of five broad traits: openness, conscientiousness, extraversion, agreeableness, and neuroticism. The researchers then had these LLM personas complete the 44-item Big Five Inventory (BFI) personality test and a story writing task.
The researchers evaluated the LLM personas' performance using both automatic and human evaluations. The automatic analysis showed that the LLM personas' self-reported BFI scores were consistent with their designated personality types, with large effect sizes observed across all five traits.
Additionally, the researchers found that the LLM personas' writings exhibited emerging representative linguistic patterns for the different personality traits when compared to a corpus of human-written texts.
Furthermore, the human evaluation component revealed that people could perceive some personality traits in the LLM-generated writings with an accuracy of up to 80%. However, this accuracy dropped significantly when the annotators were informed that the content was AI-authored.
The findings of this study suggest that LLMs have the potential to be used to create AI agents with convincing and consistent personalities, as demonstrated by the alignment between the LLM personas' self-reported traits and their generated content. However, the researchers also highlight the need for further research on how users perceive and interact with these AI personas, especially when they are aware of the AI authorship.
Critical Analysis
The research presented in this paper is a valuable contribution to the field of personalized AI, as it explores the ability of large language models to generate content that reflects specific personality traits. The study's experimental design, with the simulation of distinct LLM personas and the use of both automatic and human evaluations, provides a robust and comprehensive approach to assessing the consistency and accuracy of the generated content.
One potential limitation of the study is the scope of the personality assessment, which was limited to the Big Five personality model. While this is a widely recognized framework, there may be other personality models or traits that could be more relevant or nuanced for certain applications of personalized AI. Additionally, the study focused on story writing as the primary task, which may not fully capture the range of behaviors and interactions that would be expected of a conversational AI system.
Another area for further research is the impact of AI authorship awareness on human perception of personality traits. The finding that accuracy drops significantly when annotators are informed of the AI origin of the content raises important questions about the transparency and trustworthiness of personalized AI systems. Researchers may need to explore ways to mitigate this effect or to design AI personas in a manner that fosters a more positive and engaging user experience.
Overall, this study provides a solid foundation for understanding the potential and challenges of using LLMs to create personalized AI agents with consistent and relatable personality traits. As the field of conversational AI continues to evolve, this research highlights the need for a deeper understanding of how users perceive and interact with these systems, and how their design can be optimized to create more meaningful and engaging experiences.
Conclusion
This study investigates the ability of large language models (LLMs) to generate content that accurately and consistently reflects specific personality traits, as embodied by simulated "LLM personas." The researchers found that the LLM personas' self-reported personality scores aligned with their designated traits, and their written content exhibited representative linguistic patterns for those traits.
The study's findings suggest that LLMs have the potential to be used to create AI agents with believable and consistent personalities, which could have significant implications for the development of personalized chatbots, virtual assistants, and other conversational AI applications.
However, the research also highlights the need for further investigation into how users perceive and interact with these AI personas, particularly when they are aware of the AI authorship. Addressing this challenge will be crucial in ensuring that personalized AI systems are designed to foster meaningful and trustworthy interactions with users.
As the field of conversational AI continues to advance, studies like this one will play an important role in guiding the development of AI systems that can effectively and ethically embody human-like personality traits and behaviors.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
New!Limited Ability of LLMs to Simulate Human Psychological Behaviours: a Psychometric Analysis
Nikolay B Petrov, Gregory Serapio-Garc'ia, Jason Rentfrow
0
0
The humanlike responses of large language models (LLMs) have prompted social scientists to investigate whether LLMs can be used to simulate human participants in experiments, opinion polls and surveys. Of central interest in this line of research has been mapping out the psychological profiles of LLMs by prompting them to respond to standardized questionnaires. The conflicting findings of this research are unsurprising given that mapping out underlying, or latent, traits from LLMs' text responses to questionnaires is no easy task. To address this, we use psychometrics, the science of psychological measurement. In this study, we prompt OpenAI's flagship models, GPT-3.5 and GPT-4, to assume different personas and respond to a range of standardized measures of personality constructs. We used two kinds of persona descriptions: either generic (four or five random person descriptions) or specific (mostly demographics of actual humans from a large-scale human dataset). We found that the responses from GPT-4, but not GPT-3.5, using generic persona descriptions show promising, albeit not perfect, psychometric properties, similar to human norms, but the data from both LLMs when using specific demographic profiles, show poor psychometrics properties. We conclude that, currently, when LLMs are asked to simulate silicon personas, their responses are poor signals of potentially underlying latent traits. Thus, our work casts doubt on LLMs' ability to simulate individual-level human behaviour across multiple-choice question answering tasks.
5/14/2024
🛸
Dynamic Generation of Personalities with Large Language Models
Jianzhi Liu, Hexiang Gu, Tianyu Zheng, Liuyu Xiang, Huijia Wu, Jie Fu, Zhaofeng He
0
0
In the realm of mimicking human deliberation, large language models (LLMs) show promising performance, thereby amplifying the importance of this research area. Deliberation is influenced by both logic and personality. However, previous studies predominantly focused on the logic of LLMs, neglecting the exploration of personality aspects. In this work, we introduce Dynamic Personality Generation (DPG), a dynamic personality generation method based on Hypernetworks. Initially, we embed the Big Five personality theory into GPT-4 to form a personality assessment machine, enabling it to evaluate characters' personality traits from dialogues automatically. We propose a new metric to assess personality generation capability based on this evaluation method. Then, we use this personality assessment machine to evaluate dialogues in script data, resulting in a personality-dialogue dataset. Finally, we fine-tune DPG on the personality-dialogue dataset. Experiments prove that DPG's personality generation capability is stronger after fine-tuning on this dataset than traditional fine-tuning methods, surpassing prompt-based GPT-4.
4/11/2024
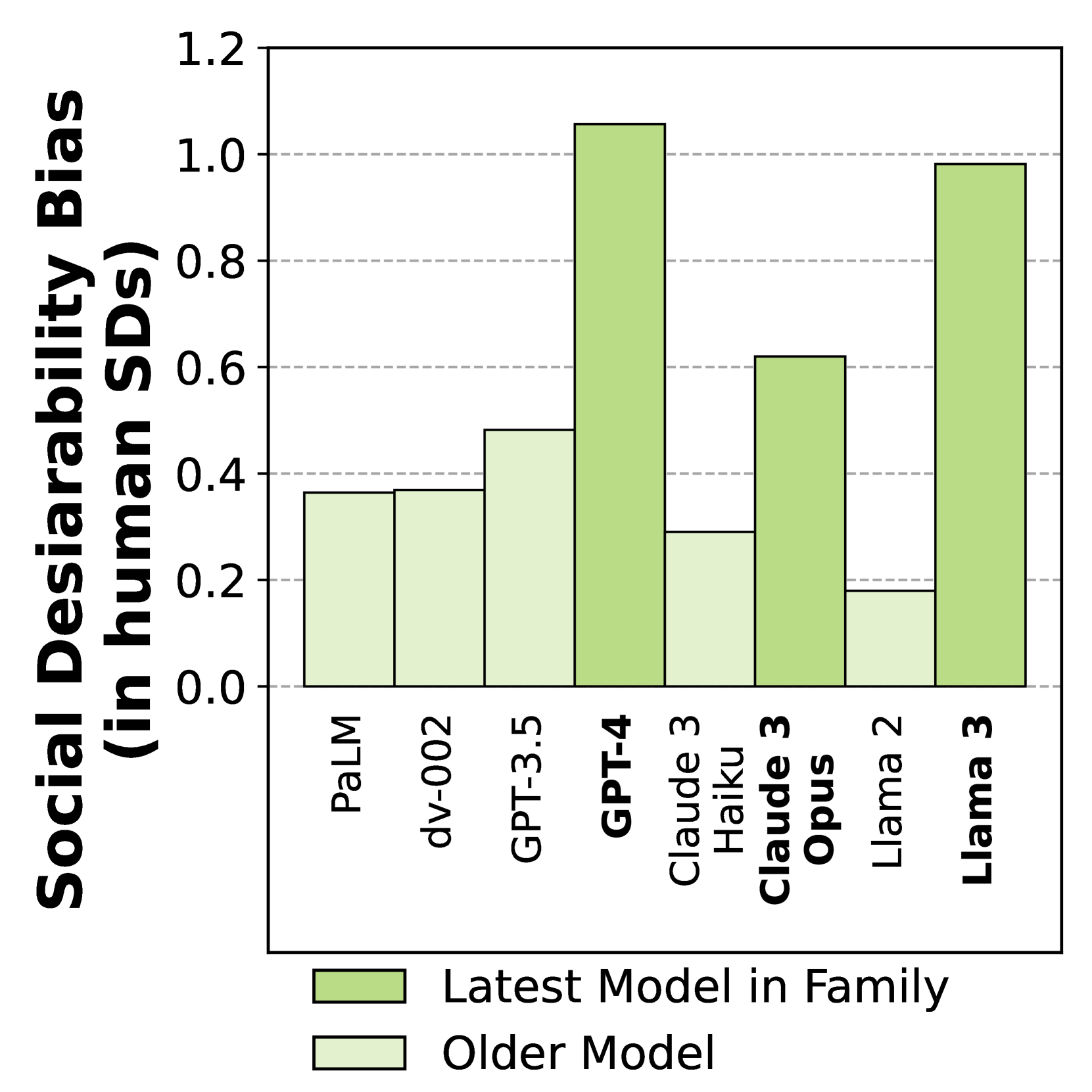
New!Large Language Models Show Human-like Social Desirability Biases in Survey Responses
Aadesh Salecha, Molly E. Ireland, Shashanka Subrahmanya, Jo~ao Sedoc, Lyle H. Ungar, Johannes C. Eichstaedt
0
0
As Large Language Models (LLMs) become widely used to model and simulate human behavior, understanding their biases becomes critical. We developed an experimental framework using Big Five personality surveys and uncovered a previously undetected social desirability bias in a wide range of LLMs. By systematically varying the number of questions LLMs were exposed to, we demonstrate their ability to infer when they are being evaluated. When personality evaluation is inferred, LLMs skew their scores towards the desirable ends of trait dimensions (i.e., increased extraversion, decreased neuroticism, etc). This bias exists in all tested models, including GPT-4/3.5, Claude 3, Llama 3, and PaLM-2. Bias levels appear to increase in more recent models, with GPT-4's survey responses changing by 1.20 (human) standard deviations and Llama 3's by 0.98 standard deviations-very large effects. This bias is robust to randomization of question order and paraphrasing. Reverse-coding all the questions decreases bias levels but does not eliminate them, suggesting that this effect cannot be attributed to acquiescence bias. Our findings reveal an emergent social desirability bias and suggest constraints on profiling LLMs with psychometric tests and on using LLMs as proxies for human participants.
5/13/2024
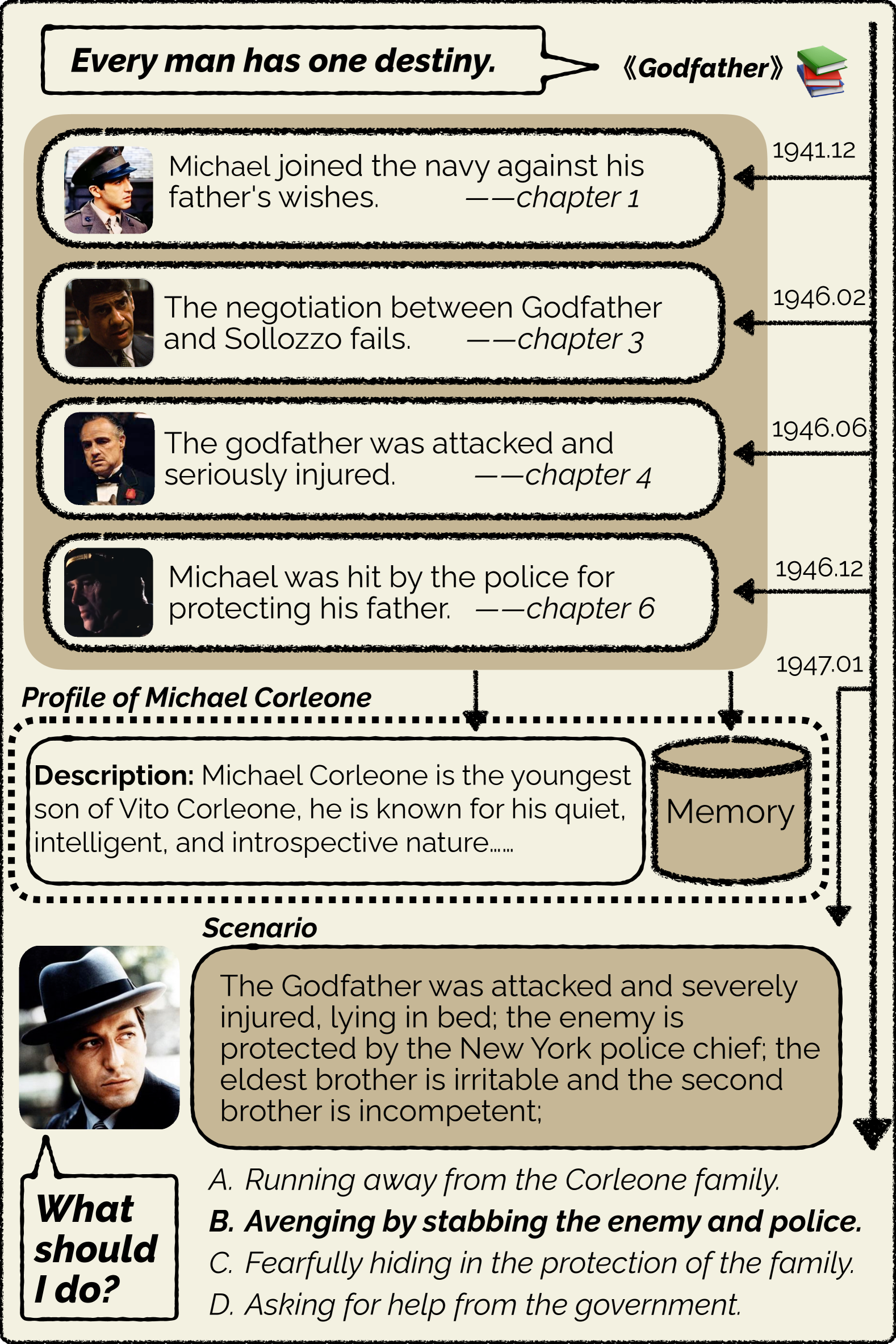
Character is Destiny: Can Large Language Models Simulate Persona-Driven Decisions in Role-Playing?
Rui Xu, Xintao Wang, Jiangjie Chen, Siyu Yuan, Xinfeng Yuan, Jiaqing Liang, Zulong Chen, Xiaoqing Dong, Yanghua Xiao
0
0
Can Large Language Models substitute humans in making important decisions? Recent research has unveiled the potential of LLMs to role-play assigned personas, mimicking their knowledge and linguistic habits. However, imitative decision-making requires a more nuanced understanding of personas. In this paper, we benchmark the ability of LLMs in persona-driven decision-making. Specifically, we investigate whether LLMs can predict characters' decisions provided with the preceding stories in high-quality novels. Leveraging character analyses written by literary experts, we construct a dataset LIFECHOICE comprising 1,401 character decision points from 395 books. Then, we conduct comprehensive experiments on LIFECHOICE, with various LLMs and methods for LLM role-playing. The results demonstrate that state-of-the-art LLMs exhibit promising capabilities in this task, yet there is substantial room for improvement. Hence, we further propose the CHARMAP method, which achieves a 6.01% increase in accuracy via persona-based memory retrieval. We will make our datasets and code publicly available.
4/19/2024