ChatGLM-Math: Improving Math Problem-Solving in Large Language Models with a Self-Critique Pipeline
2404.02893
0
0

Abstract
Large language models (LLMs) have shown excellent mastering of human language, but still struggle in real-world applications that require mathematical problem-solving. While many strategies and datasets to enhance LLMs' mathematics are developed, it remains a challenge to simultaneously maintain and improve both language and mathematical capabilities in deployed LLM systems.In this work, we tailor the Self-Critique pipeline, which addresses the challenge in the feedback learning stage of LLM alignment. We first train a general Math-Critique model from the LLM itself to provide feedback signals. Then, we sequentially employ rejective fine-tuning and direct preference optimization over the LLM's own generations for data collection. Based on ChatGLM3-32B, we conduct a series of experiments on both academic and our newly created challenging dataset, MathUserEval. Results show that our pipeline significantly enhances the LLM's mathematical problem-solving while still improving its language ability, outperforming LLMs that could be two times larger. Related techniques have been deployed to ChatGLMfootnote{url{https://chatglm.cn}}, an online serving LLM. Related evaluation dataset and scripts are released at url{https://github.com/THUDM/ChatGLM-Math}.
Create account to get full access
Overview
- This paper introduces ChatGLM-Math, a system that aims to improve the math problem-solving abilities of large language models.
- The key innovation is a self-critique pipeline that helps the model better understand and reason about mathematical concepts and solutions.
- Experiments show ChatGLM-Math outperforms standard language models on a variety of math-focused benchmarks.
Plain English Explanation
Large language models like GPT-3 have become incredibly capable at understanding and generating human language. However, they can struggle with tasks that require rigorous mathematical reasoning, such as solving complex word problems or proofs.
The researchers behind ChatGLM-Math sought to address this limitation. They developed a system that teaches the language model to critically evaluate its own math problem-solving process. Instead of simply outputting an answer, the model first assesses whether its approach is sound and makes sense. It can then refine its reasoning or try alternative strategies.
This self-critique ability is key - it allows the model to go beyond just pattern matching and develop a deeper, more robust understanding of mathematical concepts. When faced with a challenging problem, the model can step back, think through the logic, and arrive at a more reliable solution.
The researchers tested ChatGLM-Math on a range of math-focused benchmarks and found it outperformed standard language models. This suggests the self-critique pipeline is an effective way to imbue large language models with stronger mathematical reasoning skills.
Technical Explanation
The core innovation in ChatGLM-Math is a self-critique pipeline that augments a base large language model. This pipeline consists of three main components:
-
Problem Representation: The model first encodes the input math problem into a compact, structured representation that captures the key entities, relationships, and constraints.
-
Solution Generation: Using this representation, the model then generates a step-by-step solution to the problem. This involves iteratively applying mathematical operations and reasoning about intermediate results.
-
Self-Critique: After generating a solution, the model evaluates the soundness and plausibility of its own work. It assesses whether the individual steps make logical sense and whether the final answer is consistent with the original problem statement.
If the self-critique identifies issues, the model can loop back and refine its solution approach. This iterative refinement allows the model to develop a deeper, more reliable understanding of the problem-solving process.
The researchers trained and evaluated ChatGLM-Math on a variety of math-focused benchmarks, including math word problems, symbolic math manipulation, and geometric reasoning. Compared to standard language models, ChatGLM-Math demonstrated significantly improved performance across these tasks.
Critical Analysis
The paper provides a compelling demonstration of how equipping large language models with self-critique capabilities can enhance their mathematical reasoning abilities. The results suggest this approach holds promise for improving the robustness and reliability of language models on tasks requiring rigorous logical thinking.
That said, the paper does not address certain limitations and potential issues. For example, the self-critique mechanism is rule-based and may not generalize well to increasingly complex mathematical domains. There are also open questions around the model's ability to handle ambiguity, inconsistencies, or incomplete information in real-world math problems.
Additionally, the evaluation was conducted on curated benchmark datasets, which may not fully capture the breadth of mathematical reasoning required in practical applications. Further testing on more diverse, real-world math problems would help validate the system's broader applicability.
Overall, while ChatGLM-Math represents an exciting advancement, continued research is needed to address these limitations and expand the capabilities of language models in mathematical domains.
Conclusion
This paper introduces ChatGLM-Math, a system that enhances the math problem-solving abilities of large language models through a self-critique pipeline. By teaching the model to critically evaluate its own reasoning process, the researchers have shown it can outperform standard language models on a variety of math-focused benchmarks.
The self-critique mechanism is a promising approach for imbuing language models with more robust mathematical understanding. As these models continue to advance, techniques like those demonstrated in ChatGLM-Math could play a key role in developing AI systems that can reliably tackle complex logical and quantitative reasoning tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
MathChat: Converse to Tackle Challenging Math Problems with LLM Agents
Yiran Wu, Feiran Jia, Shaokun Zhang, Hangyu Li, Erkang Zhu, Yue Wang, Yin Tat Lee, Richard Peng, Qingyun Wu, Chi Wang
0
0
Employing Large Language Models (LLMs) to address mathematical problems is an intriguing research endeavor, considering the abundance of math problems expressed in natural language across numerous science and engineering fields. LLMs, with their generalized ability, are used as a foundation model to build AI agents for different tasks. In this paper, we study the effectiveness of utilizing LLM agents to solve math problems through conversations. We propose MathChat, a conversational problem-solving framework designed for math problems. MathChat consists of an LLM agent and a user proxy agent which is responsible for tool execution and additional guidance. This synergy facilitates a collaborative problem-solving process, where the agents engage in a dialogue to solve the problems. We perform evaluation on difficult high school competition problems from the MATH dataset. Utilizing Python, we show that MathChat can further improve previous tool-using prompting methods by 6%.
7/1/2024
Mathify: Evaluating Large Language Models on Mathematical Problem Solving Tasks
Avinash Anand, Mohit Gupta, Kritarth Prasad, Navya Singla, Sanjana Sanjeev, Jatin Kumar, Adarsh Raj Shivam, Rajiv Ratn Shah
0
0
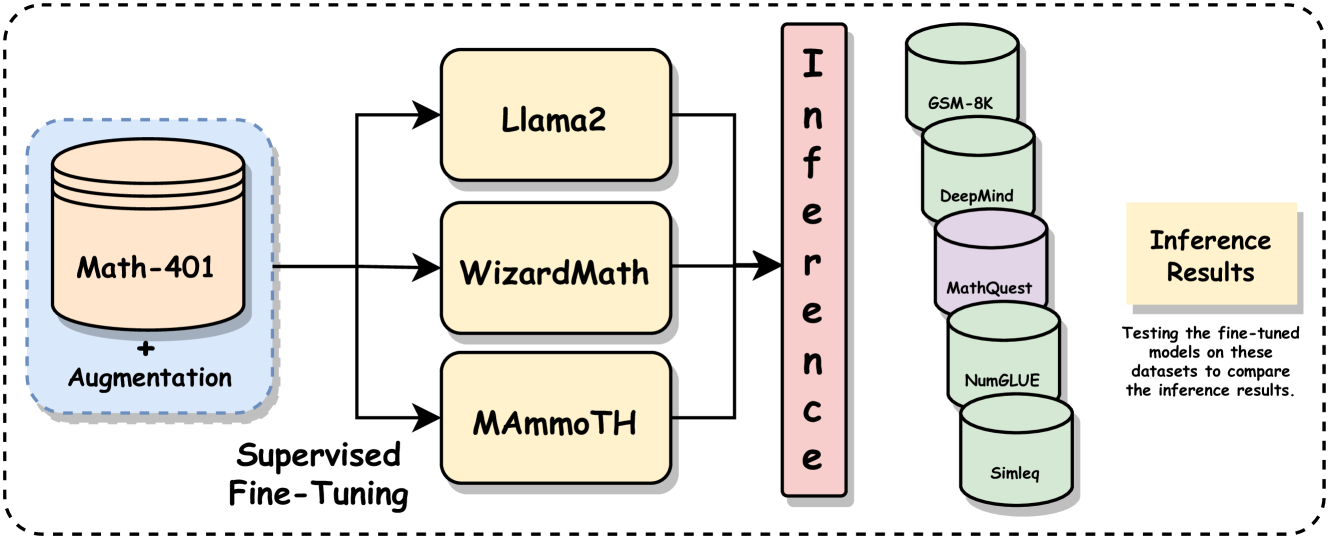
The rapid progress in the field of natural language processing (NLP) systems and the expansion of large language models (LLMs) have opened up numerous opportunities in the field of education and instructional methods. These advancements offer the potential for tailored learning experiences and immediate feedback, all delivered through accessible and cost-effective services. One notable application area for this technological advancement is in the realm of solving mathematical problems. Mathematical problem-solving not only requires the ability to decipher complex problem statements but also the skill to perform precise arithmetic calculations at each step of the problem-solving process. However, the evaluation of the arithmetic capabilities of large language models remains an area that has received relatively little attention. In response, we introduce an extensive mathematics dataset called MathQuest sourced from the 11th and 12th standard Mathematics NCERT textbooks. This dataset encompasses mathematical challenges of varying complexity and covers a wide range of mathematical concepts. Utilizing this dataset, we conduct fine-tuning experiments with three prominent LLMs: LLaMA-2, WizardMath, and MAmmoTH. These fine-tuned models serve as benchmarks for evaluating their performance on our dataset. Our experiments reveal that among the three models, MAmmoTH-13B emerges as the most proficient, achieving the highest level of competence in solving the presented mathematical problems. Consequently, MAmmoTH-13B establishes itself as a robust and dependable benchmark for addressing NCERT mathematics problems.
4/23/2024
MathChat: Benchmarking Mathematical Reasoning and Instruction Following in Multi-Turn Interactions
Zhenwen Liang, Dian Yu, Wenhao Yu, Wenlin Yao, Zhihan Zhang, Xiangliang Zhang, Dong Yu
0
0
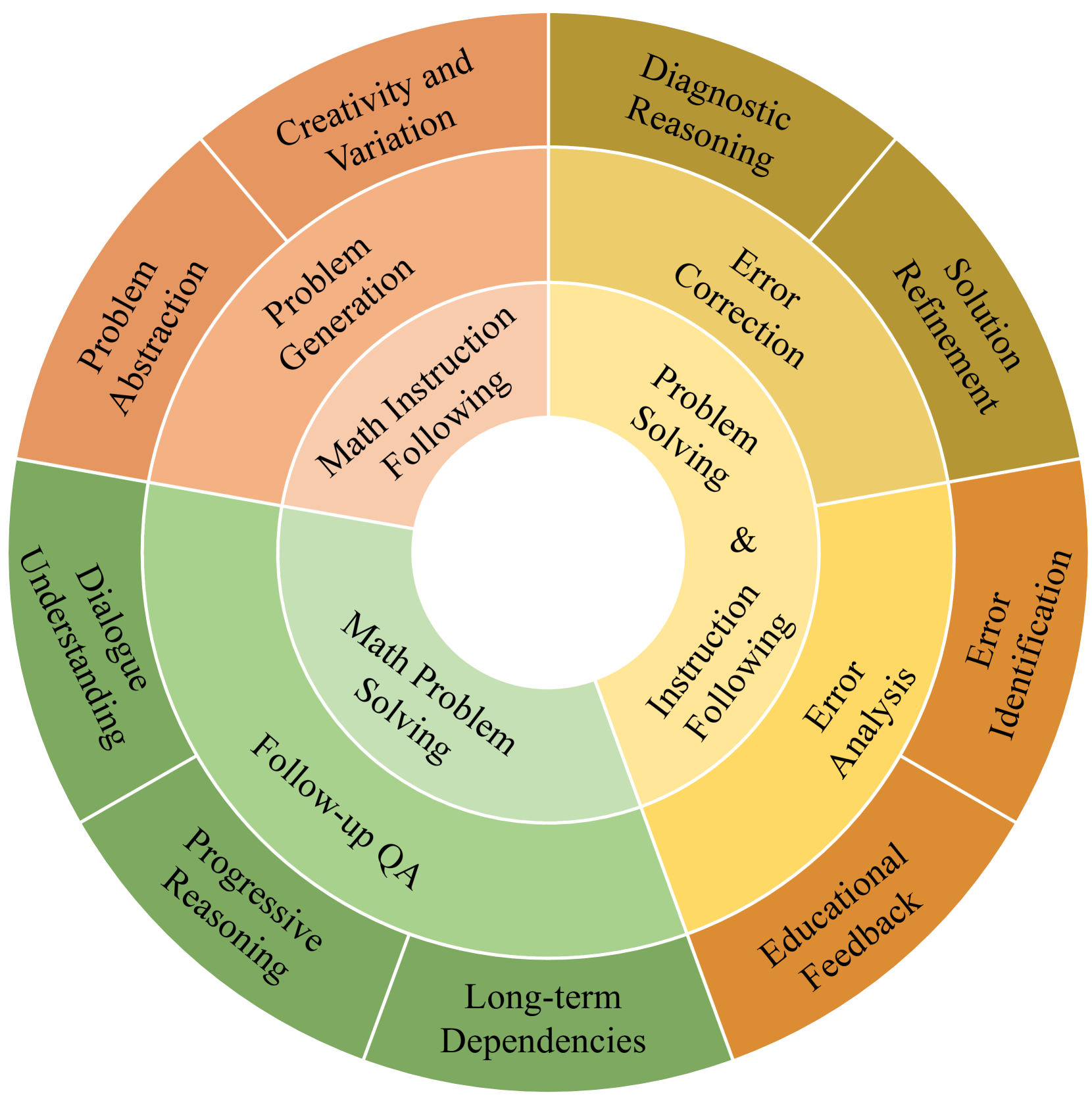
Large language models (LLMs) have demonstrated impressive capabilities in mathematical problem solving, particularly in single turn question answering formats. However, real world scenarios often involve mathematical question answering that requires multi turn or interactive information exchanges, and the performance of LLMs on these tasks is still underexplored. This paper introduces MathChat, a comprehensive benchmark specifically designed to evaluate LLMs across a broader spectrum of mathematical tasks. These tasks are structured to assess the models' abilities in multiturn interactions and open ended generation. We evaluate the performance of various SOTA LLMs on the MathChat benchmark, and we observe that while these models excel in single turn question answering, they significantly underperform in more complex scenarios that require sustained reasoning and dialogue understanding. To address the above limitations of existing LLMs when faced with multiturn and open ended tasks, we develop MathChat sync, a synthetic dialogue based math dataset for LLM finetuning, focusing on improving models' interaction and instruction following capabilities in conversations. Experimental results emphasize the need for training LLMs with diverse, conversational instruction tuning datasets like MathChatsync. We believe this work outlines one promising direction for improving the multiturn mathematical reasoning abilities of LLMs, thus pushing forward the development of LLMs that are more adept at interactive mathematical problem solving and real world applications.
5/31/2024

MARIO Eval: Evaluate Your Math LLM with your Math LLM--A mathematical dataset evaluation toolkit
Boning Zhang, Chengxi Li, Kai Fan
0
0
Large language models (LLMs) have been explored in a variety of reasoning tasks including solving of mathematical problems. Each math dataset typically includes its own specially designed evaluation script, which, while suitable for its intended use, lacks generalizability across different datasets. Consequently, updates and adaptations to these evaluation tools tend to occur without being systematically reported, leading to inconsistencies and obstacles to fair comparison across studies. To bridge this gap, we introduce a comprehensive mathematical evaluation toolkit that not only utilizes a python computer algebra system (CAS) for its numerical accuracy, but also integrates an optional LLM, known for its considerable natural language processing capabilities. To validate the effectiveness of our toolkit, we manually annotated two distinct datasets. Our experiments demonstrate that the toolkit yields more robust evaluation results compared to prior works, even without an LLM. Furthermore, when an LLM is incorporated, there is a notable enhancement. The code for our method will be made available at url{https://github.com/MARIO-Math-Reasoning/math_evaluation}.
4/23/2024