MARIO Eval: Evaluate Your Math LLM with your Math LLM--A mathematical dataset evaluation toolkit
2404.13925
0
0

Abstract
Large language models (LLMs) have been explored in a variety of reasoning tasks including solving of mathematical problems. Each math dataset typically includes its own specially designed evaluation script, which, while suitable for its intended use, lacks generalizability across different datasets. Consequently, updates and adaptations to these evaluation tools tend to occur without being systematically reported, leading to inconsistencies and obstacles to fair comparison across studies. To bridge this gap, we introduce a comprehensive mathematical evaluation toolkit that not only utilizes a python computer algebra system (CAS) for its numerical accuracy, but also integrates an optional LLM, known for its considerable natural language processing capabilities. To validate the effectiveness of our toolkit, we manually annotated two distinct datasets. Our experiments demonstrate that the toolkit yields more robust evaluation results compared to prior works, even without an LLM. Furthermore, when an LLM is incorporated, there is a notable enhancement. The code for our method will be made available at url{https://github.com/MARIO-Math-Reasoning/math_evaluation}.
Create account to get full access
Introduction
MARIO Eval is a mathematical dataset evaluation toolkit that allows you to evaluate your math-focused large language model (LLM) using your own math LLM. This toolkit provides a framework for assessing the performance of math-focused LLMs on a variety of mathematical tasks and datasets.
Main Framework
Type Definitions
The framework defines several key types, including MathTask, MathDataset, and MathEvaluator. These types are used to represent the different components of the evaluation process, such as the specific mathematical tasks, the datasets used for evaluation, and the evaluator that assesses the model's performance.
Evaluating Math LLMs
The main idea behind MARIO Eval is to use a math-focused LLM as the evaluator for other math LLMs. This approach allows for a more holistic and nuanced assessment of the model's capabilities, as the evaluator can understand the underlying mathematical concepts and reasoning required to solve the tasks.
The framework provides a set of predefined mathematical tasks and datasets that can be used for evaluation, as well as the ability to define custom tasks and datasets. The evaluator LLM is then used to assess the performance of the target math LLM on these tasks, generating detailed reports and insights about the model's strengths, weaknesses, and areas for improvement.
Technical Explanation
The paper outlines the key components of the MARIO Eval framework, including the type definitions, the evaluation process, and the implementation details. The authors discuss how the framework allows for the creation of customized mathematical tasks and datasets, as well as the ability to leverage a math-focused LLM as the evaluator.
The paper also presents the results of several experiments conducted using the MARIO Eval framework, demonstrating its effectiveness in assessing the performance of different math-focused LLMs on a variety of tasks and datasets. These experiments highlight the potential of using a math-focused LLM as the evaluator, as it can provide more nuanced and insightful assessments compared to traditional evaluation metrics.
Critical Analysis
The MARIO Eval framework represents a significant advancement in the evaluation of math-focused LLMs, as it addresses some of the limitations of traditional evaluation approaches. By using a math-focused LLM as the evaluator, the framework can better capture the nuances of mathematical reasoning and problem-solving, which are often overlooked by standard evaluation metrics.
However, the authors acknowledge that the framework is not without its limitations. The performance of the evaluator LLM itself can impact the accuracy and reliability of the assessment, and the authors suggest that further research is needed to address this issue. Additionally, the authors note that the framework may not be suitable for all types of mathematical tasks and datasets, and that careful selection and curation of the evaluation components are essential for obtaining meaningful results.
Conclusion
The MARIO Eval framework represents a significant step forward in the evaluation of math-focused LLMs. By leveraging a math-focused LLM as the evaluator, the framework can provide more nuanced and insightful assessments of model performance, paving the way for the development of even more powerful and capable math-focused LLMs. The framework's flexibility and customizability make it a valuable tool for researchers and practitioners working in the field of mathematical AI and LLMs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Mathify: Evaluating Large Language Models on Mathematical Problem Solving Tasks
Avinash Anand, Mohit Gupta, Kritarth Prasad, Navya Singla, Sanjana Sanjeev, Jatin Kumar, Adarsh Raj Shivam, Rajiv Ratn Shah
0
0
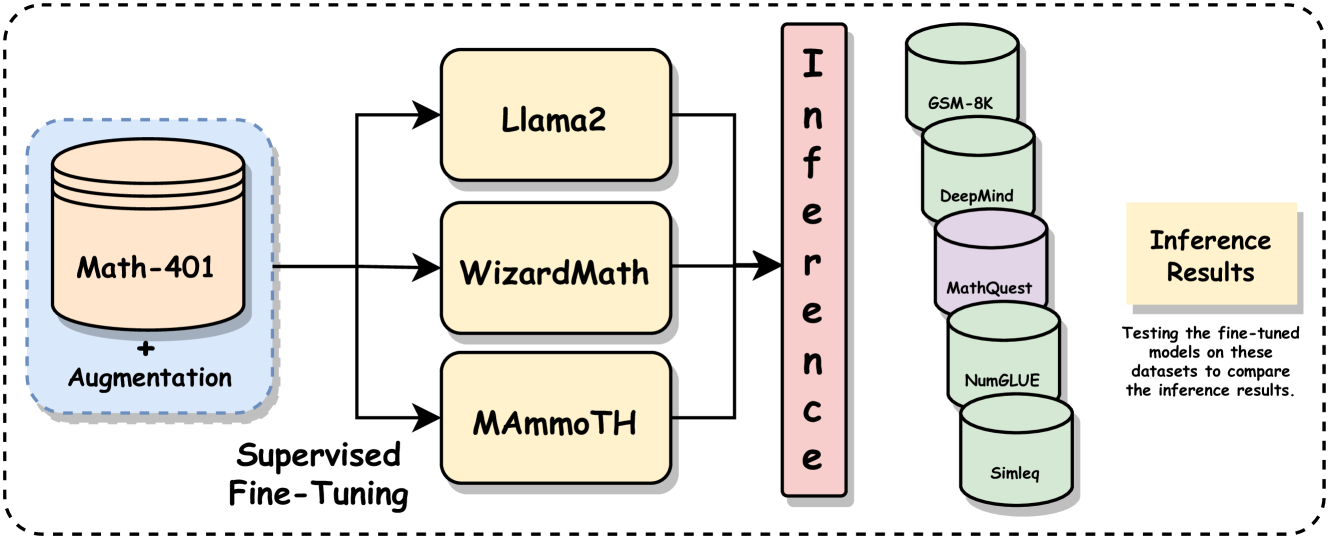
The rapid progress in the field of natural language processing (NLP) systems and the expansion of large language models (LLMs) have opened up numerous opportunities in the field of education and instructional methods. These advancements offer the potential for tailored learning experiences and immediate feedback, all delivered through accessible and cost-effective services. One notable application area for this technological advancement is in the realm of solving mathematical problems. Mathematical problem-solving not only requires the ability to decipher complex problem statements but also the skill to perform precise arithmetic calculations at each step of the problem-solving process. However, the evaluation of the arithmetic capabilities of large language models remains an area that has received relatively little attention. In response, we introduce an extensive mathematics dataset called MathQuest sourced from the 11th and 12th standard Mathematics NCERT textbooks. This dataset encompasses mathematical challenges of varying complexity and covers a wide range of mathematical concepts. Utilizing this dataset, we conduct fine-tuning experiments with three prominent LLMs: LLaMA-2, WizardMath, and MAmmoTH. These fine-tuned models serve as benchmarks for evaluating their performance on our dataset. Our experiments reveal that among the three models, MAmmoTH-13B emerges as the most proficient, achieving the highest level of competence in solving the presented mathematical problems. Consequently, MAmmoTH-13B establishes itself as a robust and dependable benchmark for addressing NCERT mathematics problems.
4/23/2024
⚙️
GeoEval: Benchmark for Evaluating LLMs and Multi-Modal Models on Geometry Problem-Solving
Jiaxin Zhang, Zhongzhi Li, Mingliang Zhang, Fei Yin, Chenglin Liu, Yashar Moshfeghi
0
0
Recent advancements in large language models (LLMs) and multi-modal models (MMs) have demonstrated their remarkable capabilities in problem-solving. Yet, their proficiency in tackling geometry math problems, which necessitates an integrated understanding of both textual and visual information, has not been thoroughly evaluated. To address this gap, we introduce the GeoEval benchmark, a comprehensive collection that includes a main subset of 2,000 problems, a 750 problems subset focusing on backward reasoning, an augmented subset of 2,000 problems, and a hard subset of 300 problems. This benchmark facilitates a deeper investigation into the performance of LLMs and MMs in solving geometry math problems. Our evaluation of ten LLMs and MMs across these varied subsets reveals that the WizardMath model excels, achieving a 55.67% accuracy rate on the main subset but only a 6.00% accuracy on the hard subset. This highlights the critical need for testing models against datasets on which they have not been pre-trained. Additionally, our findings indicate that GPT-series models perform more effectively on problems they have rephrased, suggesting a promising method for enhancing model capabilities.
5/20/2024

MathBench: Evaluating the Theory and Application Proficiency of LLMs with a Hierarchical Mathematics Benchmark
Hongwei Liu, Zilong Zheng, Yuxuan Qiao, Haodong Duan, Zhiwei Fei, Fengzhe Zhou, Wenwei Zhang, Songyang Zhang, Dahua Lin, Kai Chen
0
0
Recent advancements in large language models (LLMs) have showcased significant improvements in mathematics. However, traditional math benchmarks like GSM8k offer a unidimensional perspective, falling short in providing a holistic assessment of the LLMs' math capabilities. To address this gap, we introduce MathBench, a new benchmark that rigorously assesses the mathematical capabilities of large language models. MathBench spans a wide range of mathematical disciplines, offering a detailed evaluation of both theoretical understanding and practical problem-solving skills. The benchmark progresses through five distinct stages, from basic arithmetic to college mathematics, and is structured to evaluate models at various depths of knowledge. Each stage includes theoretical questions and application problems, allowing us to measure a model's mathematical proficiency and its ability to apply concepts in practical scenarios. MathBench aims to enhance the evaluation of LLMs' mathematical abilities, providing a nuanced view of their knowledge understanding levels and problem solving skills in a bilingual context. The project is released at https://github.com/open-compass/MathBench .
5/21/2024
MedCalc-Bench: Evaluating Large Language Models for Medical Calculations
Nikhil Khandekar, Qiao Jin, Guangzhi Xiong, Soren Dunn, Serina S Applebaum, Zain Anwar, Maame Sarfo-Gyamfi, Conrad W Safranek, Abid A Anwar, Andrew Zhang, Aidan Gilson, Maxwell B Singer, Amisha Dave, Andrew Taylor, Aidong Zhang, Qingyu Chen, Zhiyong Lu
0
0
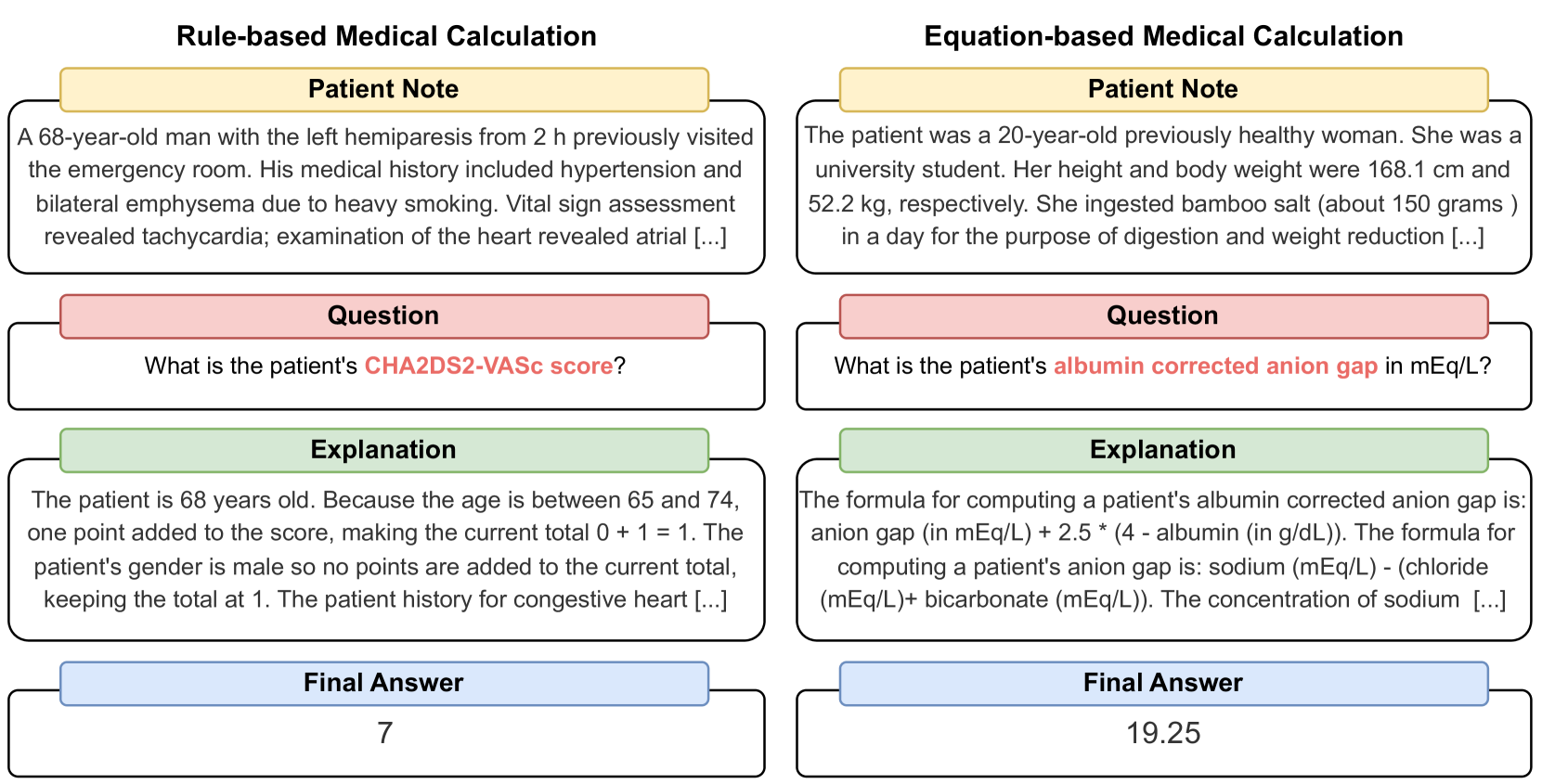
As opposed to evaluating computation and logic-based reasoning, current benchmarks for evaluating large language models (LLMs) in medicine are primarily focused on question-answering involving domain knowledge and descriptive reasoning. While such qualitative capabilities are vital to medical diagnosis, in real-world scenarios, doctors frequently use clinical calculators that follow quantitative equations and rule-based reasoning paradigms for evidence-based decision support. To this end, we propose MedCalc-Bench, a first-of-its-kind dataset focused on evaluating the medical calculation capability of LLMs. MedCalc-Bench contains an evaluation set of over 1000 manually reviewed instances from 55 different medical calculation tasks. Each instance in MedCalc-Bench consists of a patient note, a question requesting to compute a specific medical value, a ground truth answer, and a step-by-step explanation showing how the answer is obtained. While our evaluation results show the potential of LLMs in this area, none of them are effective enough for clinical settings. Common issues include extracting the incorrect entities, not using the correct equation or rules for a calculation task, or incorrectly performing the arithmetic for the computation. We hope our study highlights the quantitative knowledge and reasoning gaps in LLMs within medical settings, encouraging future improvements of LLMs for various clinical calculation tasks.
7/2/2024