ChatGPT is a Knowledgeable but Inexperienced Solver: An Investigation of Commonsense Problem in Large Language Models
2303.16421
0
0
💬
Abstract
Large language models (LLMs) have made significant progress in NLP. However, their ability to memorize, represent, and leverage commonsense knowledge has been a well-known pain point. In this paper, we specifically focus on ChatGPT, a widely used and easily accessible LLM, and ask the following questions: (1) Can ChatGPT effectively answer commonsense questions? (2) Is ChatGPT aware of the underlying commonsense knowledge for answering a specific question? (3) Is ChatGPT knowledgeable in commonsense? (4) Can ChatGPT effectively leverage commonsense for answering questions? We conduct a series of experiments on 11 datasets to evaluate ChatGPT's commonsense abilities, including answering commonsense questions, identifying necessary knowledge, generating knowledge descriptions, and using knowledge descriptions to answer questions again. Experimental results show that: (1) ChatGPT can achieve good QA accuracies in commonsense tasks, while still struggling with certain domains of datasets. (2) ChatGPT is knowledgeable, and can accurately generate most of the commonsense knowledge using knowledge prompts. (3) Despite its knowledge, ChatGPT is an inexperienced commonsense problem solver, which cannot precisely identify the needed commonsense for answering a specific question. These findings raise the need to explore improved mechanisms for effectively incorporating commonsense into LLMs like ChatGPT, such as better instruction following and commonsense guidance.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Large language models (LLMs) have made significant progress in natural language processing (NLP), but their ability to effectively represent and use commonsense knowledge has been a challenge.
- This paper focuses on evaluating the commonsense abilities of the widely-used LLM, ChatGPT, through a series of experiments.
- The key questions addressed are: Can ChatGPT answer commonsense questions effectively? Is it aware of the underlying commonsense knowledge required? How knowledgeable is it in commonsense? Can it leverage commonsense to answer questions?
Plain English Explanation
Large language models (LLMs) like ChatGPT have shown impressive capabilities in natural language processing (NLP) tasks. However, one of their well-known limitations is their ability to truly understand and utilize commonsense knowledge. Commonsense refers to the basic, intuitive understanding of the world that humans acquire through everyday experiences.
In this paper, the researchers closely examined the commonsense abilities of ChatGPT, a widely-used and accessible LLM. They wanted to answer several key questions: Can ChatGPT correctly answer commonsense questions? Is it aware of the underlying commonsense knowledge needed to answer those questions? How knowledgeable is ChatGPT in commonsense overall? And can it effectively leverage that knowledge to answer questions?
To find out, the researchers conducted a series of experiments using 11 different datasets that test various aspects of commonsense reasoning. They looked at ChatGPT's performance in answering commonsense questions, its ability to identify the necessary knowledge, and its capacity to generate and then use that knowledge to answer questions again.
Technical Explanation
The researchers conducted a comprehensive evaluation of ChatGPT's commonsense abilities through a series of experiments on 11 different commonsense reasoning datasets.
First, they assessed ChatGPT's performance in directly answering commonsense questions across various domains, such as physical reasoning, social understanding, and causal relations. The results showed that ChatGPT can achieve good question-answering (QA) accuracy on many commonsense tasks, but still struggles with certain dataset domains.
Next, the researchers investigated whether ChatGPT is aware of the underlying commonsense knowledge needed to answer specific questions. They did this by prompting ChatGPT to generate descriptions of the relevant knowledge for a given question. The findings indicate that ChatGPT is generally knowledgeable about commonsense and can accurately describe the necessary knowledge for most questions.
However, the third experiment revealed that despite its commonsense knowledge, ChatGPT is not an experienced commonsense problem solver. When asked to identify the specific knowledge required to answer a question, ChatGPT often struggled to precisely pinpoint the relevant information.
Finally, the researchers had ChatGPT use the generated knowledge descriptions to answer the questions again. This showed that while ChatGPT has the necessary commonsense knowledge, it has difficulty effectively leveraging that knowledge to solve commonsense reasoning problems.
Critical Analysis
The paper provides valuable insights into the commonsense capabilities of the widely-used ChatGPT model. The researchers' systematic approach of evaluating different aspects of commonsense reasoning, such as question answering, knowledge identification, and knowledge application, offers a comprehensive view of ChatGPT's strengths and limitations in this area.
One limitation mentioned in the paper is that the experiments were conducted on a fixed set of commonsense datasets, which may not fully capture the breadth of commonsense knowledge required in real-world scenarios. Additionally, the paper does not delve into the potential reasons behind ChatGPT's struggles with certain commonsense domains or its difficulty in precisely identifying and leveraging relevant knowledge.
Further research could explore ways to enhance ChatGPT's commonsense reasoning abilities, such as through improved instruction following, commonsense-specific fine-tuning, or the integration of additional knowledge sources. Investigating how ChatGPT's commonsense performance compares to other LLMs or human benchmarks could also provide valuable insights.
Conclusion
This research paper offers a detailed examination of the commonsense capabilities of the widely-used ChatGPT model. The findings suggest that while ChatGPT can achieve good performance on many commonsense reasoning tasks, it still faces challenges in effectively representing, identifying, and leveraging commonsense knowledge to solve problems.
The study highlights the need for continued advancements in incorporating commonsense understanding into large language models like ChatGPT. Addressing these limitations could significantly improve the models' ability to reason about and interact with the world in a more natural and intuitive way, ultimately enhancing their real-world applicability across various domains.
Related Papers
💬
ChatGPT as an inventor: Eliciting the strengths and weaknesses of current large language models against humans in engineering design
Daniel Nyg{aa}rd Ege, Henrik H. {O}vreb{o}, Vegar Stubberud, Martin Francis Berg, Christer Elverum, Martin Steinert, H{aa}vard Vestad
0
0
This study compares the design practices and performance of ChatGPT 4.0, a large language model (LLM), against graduate engineering students in a 48-hour prototyping hackathon, based on a dataset comprising more than 100 prototypes. The LLM participated by instructing two participants who executed its instructions and provided objective feedback, generated ideas autonomously and made all design decisions without human intervention. The LLM exhibited similar prototyping practices to human participants and finished second among six teams, successfully designing and providing building instructions for functional prototypes. The LLM's concept generation capabilities were particularly strong. However, the LLM prematurely abandoned promising concepts when facing minor difficulties, added unnecessary complexity to designs, and experienced design fixation. Communication between the LLM and participants was challenging due to vague or unclear descriptions, and the LLM had difficulty maintaining continuity and relevance in answers. Based on these findings, six recommendations for implementing an LLM like ChatGPT in the design process are proposed, including leveraging it for ideation, ensuring human oversight for key decisions, implementing iterative feedback loops, prompting it to consider alternatives, and assigning specific and manageable tasks at a subsystem level.
4/30/2024
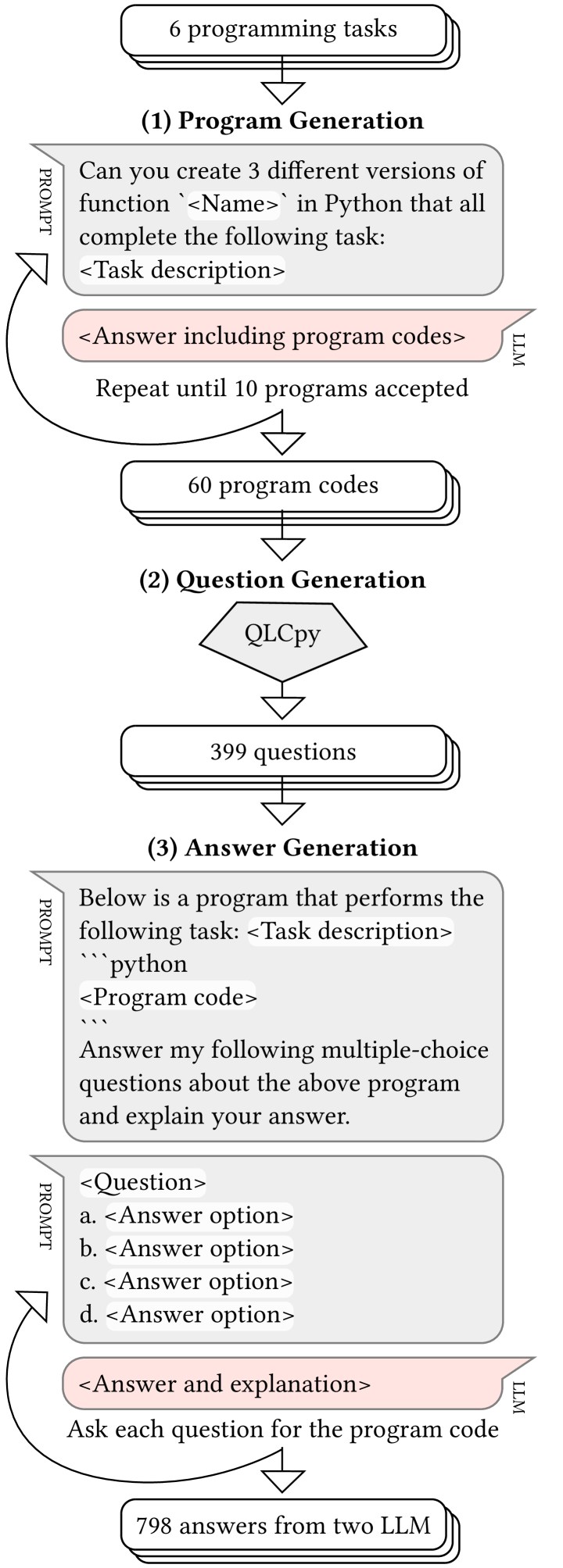
Let's Ask AI About Their Programs: Exploring ChatGPT's Answers To Program Comprehension Questions
Teemu Lehtinen, Charles Koutcheme, Arto Hellas
0
0
Recent research has explored the creation of questions from code submitted by students. These Questions about Learners' Code (QLCs) are created through program analysis, exploring execution paths, and then creating code comprehension questions from these paths and the broader code structure. Responding to the questions requires reading and tracing the code, which is known to support students' learning. At the same time, computing education researchers have witnessed the emergence of Large Language Models (LLMs) that have taken the community by storm. Researchers have demonstrated the applicability of these models especially in the introductory programming context, outlining their performance in solving introductory programming problems and their utility in creating new learning resources. In this work, we explore the capability of the state-of-the-art LLMs (GPT-3.5 and GPT-4) in answering QLCs that are generated from code that the LLMs have created. Our results show that although the state-of-the-art LLMs can create programs and trace program execution when prompted, they easily succumb to similar errors that have previously been recorded for novice programmers. These results demonstrate the fallibility of these models and perhaps dampen the expectations fueled by the recent LLM hype. At the same time, we also highlight future research possibilities such as using LLMs to mimic students as their behavior can indeed be similar for some specific tasks.
4/19/2024
📉
How Good is ChatGPT in Giving Advice on Your Visualization Design?
Nam Wook Kim, Grace Myers, Benjamin Bach
0
0
Data visualization practitioners often lack formal training, resulting in a knowledge gap in visualization design best practices. Large-language models like ChatGPT, with their vast internet-scale training data, offer transformative potential in addressing this gap. To explore this potential, we adopted a mixed-method approach. Initially, we analyzed the VisGuide forum, a repository of data visualization questions, by comparing ChatGPT-generated responses to human replies. Subsequently, our user study delved into practitioners' reactions and attitudes toward ChatGPT as a visualization assistant. Participants, who brought their visualizations and questions, received feedback from both human experts and ChatGPT in a randomized order. They filled out experience surveys and shared deeper insights through post-interviews. The results highlight the unique advantages and disadvantages of ChatGPT, such as its ability to quickly provide a wide range of design options based on a broad knowledge base, while also revealing its limitations in terms of depth and critical thinking capabilities.
5/2/2024
✨
Beyond Code Generation: An Observational Study of ChatGPT Usage in Software Engineering Practice
Ranim Khojah, Mazen Mohamad, Philipp Leitner, Francisco Gomes de Oliveira Neto
0
0
Large Language Models (LLMs) are frequently discussed in academia and the general public as support tools for virtually any use case that relies on the production of text, including software engineering. Currently there is much debate, but little empirical evidence, regarding the practical usefulness of LLM-based tools such as ChatGPT for engineers in industry. We conduct an observational study of 24 professional software engineers who have been using ChatGPT over a period of one week in their jobs, and qualitatively analyse their dialogues with the chatbot as well as their overall experience (as captured by an exit survey). We find that, rather than expecting ChatGPT to generate ready-to-use software artifacts (e.g., code), practitioners more often use ChatGPT to receive guidance on how to solve their tasks or learn about a topic in more abstract terms. We also propose a theoretical framework for how (i) purpose of the interaction, (ii) internal factors (e.g., the user's personality), and (iii) external factors (e.g., company policy) together shape the experience (in terms of perceived usefulness and trust). We envision that our framework can be used by future research to further the academic discussion on LLM usage by software engineering practitioners, and to serve as a reference point for the design of future empirical LLM research in this domain.
4/24/2024