Let's Ask AI About Their Programs: Exploring ChatGPT's Answers To Program Comprehension Questions
2404.11734
0
0
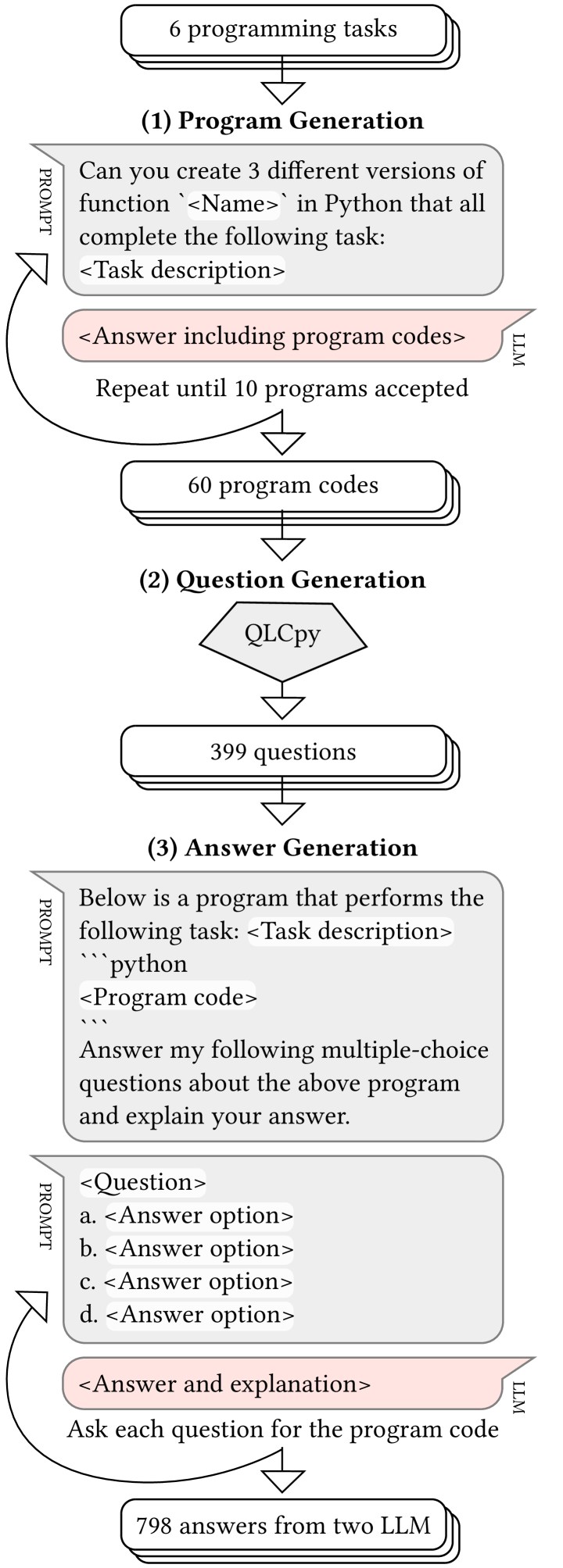
Abstract
Recent research has explored the creation of questions from code submitted by students. These Questions about Learners' Code (QLCs) are created through program analysis, exploring execution paths, and then creating code comprehension questions from these paths and the broader code structure. Responding to the questions requires reading and tracing the code, which is known to support students' learning. At the same time, computing education researchers have witnessed the emergence of Large Language Models (LLMs) that have taken the community by storm. Researchers have demonstrated the applicability of these models especially in the introductory programming context, outlining their performance in solving introductory programming problems and their utility in creating new learning resources. In this work, we explore the capability of the state-of-the-art LLMs (GPT-3.5 and GPT-4) in answering QLCs that are generated from code that the LLMs have created. Our results show that although the state-of-the-art LLMs can create programs and trace program execution when prompted, they easily succumb to similar errors that have previously been recorded for novice programmers. These results demonstrate the fallibility of these models and perhaps dampen the expectations fueled by the recent LLM hype. At the same time, we also highlight future research possibilities such as using LLMs to mimic students as their behavior can indeed be similar for some specific tasks.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Explores how the large language model ChatGPT performs on program comprehension tasks
- Evaluates ChatGPT's ability to answer questions about the functionality and behavior of code snippets
- Provides insights into the capabilities and limitations of ChatGPT for introductory programming tasks
Plain English Explanation
This paper investigates how well the artificial intelligence (AI) system ChatGPT can understand and explain computer programs. ChatGPT is a large language model that is trained to generate human-like text, and the researchers were curious to see how it would perform on tasks related to programming.
The researchers presented ChatGPT with a series of questions about short code snippets, such as "What does this code do?" or "What is the output of this program?" They wanted to see if ChatGPT could accurately comprehend the purpose and behavior of the code. This is an important skill for introductory programming students to develop, as understanding how code works is a crucial part of learning to program.
By evaluating ChatGPT's responses, the researchers gained insights into the AI's strengths and weaknesses when it comes to understanding code. They found that ChatGPT was generally able to provide accurate explanations of simple programs, but struggled with more complex code. This suggests that while large language models like ChatGPT can be useful tools for generating and understanding natural language, they may have limitations when it comes to reasoning about the intricacies of computer programs.
Technical Explanation
The researchers conducted a series of experiments to assess ChatGPT's performance on program comprehension tasks. They selected a set of code snippets representing a range of programming concepts, from simple conditional statements to more complex data structures and algorithms.
For each code snippet, the researchers asked ChatGPT questions that tested its understanding of the program's functionality, such as "What is the output of this code?" or "Describe what this code does." ChatGPT's responses were then evaluated by human raters for accuracy and completeness.
The results showed that ChatGPT was generally able to provide accurate explanations for simple programs, but struggled with more complex code. The researchers found that ChatGPT's performance was influenced by factors such as the length and complexity of the code, the programming concepts involved, and the specific wording of the questions.
The researchers also noted that ChatGPT sometimes generated plausible-sounding but incorrect responses, highlighting the need for caution when relying on large language models for tasks that require precise reasoning about code behavior. This aligns with findings from other studies that have explored the limitations of large language models in mathematical and technical domains.
Critical Analysis
The researchers acknowledge several limitations of their study. First, the code snippets used were relatively short and focused on introductory programming concepts, so the findings may not generalize to more complex, real-world code. Additionally, the researchers only tested ChatGPT's comprehension of code, and did not evaluate its ability to generate or modify code, which are also important programming skills.
Another potential limitation is the reliance on human raters to evaluate ChatGPT's responses. While the researchers took steps to ensure consistency, there could still be some subjectivity in the assessment process. It would be interesting to see if the results hold up under more rigorous, automated evaluation methods.
Overall, the researchers provide valuable insights into the capabilities and limitations of large language models like ChatGPT when it comes to program comprehension. While these models may be useful tools for certain tasks, such as generating natural language descriptions of code, the findings suggest they may not be sufficient for tasks that require deep understanding and reasoning about the intricacies of computer programs.
Conclusion
This study offers a nuanced perspective on the use of large language models like ChatGPT for programming-related tasks. While the results suggest that ChatGPT can provide accurate explanations for simple code, the model's performance degrades as the complexity of the code increases. This highlights the need for continued research and development to enhance the general capabilities of large language models in technical domains.
The findings also have implications for the potential use of large language models in educational settings, where they could be leveraged to support introductory programming instruction. However, the limitations identified in this study suggest that such models should be used with caution and as part of a broader, multifaceted approach to teaching programming concepts.
Overall, this research contributes to our understanding of the strengths and weaknesses of large language models like ChatGPT, and underscores the importance of continued exploration and evaluation of these powerful AI systems.
Related Papers
✨
Beyond Code Generation: An Observational Study of ChatGPT Usage in Software Engineering Practice
Ranim Khojah, Mazen Mohamad, Philipp Leitner, Francisco Gomes de Oliveira Neto
0
0
Large Language Models (LLMs) are frequently discussed in academia and the general public as support tools for virtually any use case that relies on the production of text, including software engineering. Currently there is much debate, but little empirical evidence, regarding the practical usefulness of LLM-based tools such as ChatGPT for engineers in industry. We conduct an observational study of 24 professional software engineers who have been using ChatGPT over a period of one week in their jobs, and qualitatively analyse their dialogues with the chatbot as well as their overall experience (as captured by an exit survey). We find that, rather than expecting ChatGPT to generate ready-to-use software artifacts (e.g., code), practitioners more often use ChatGPT to receive guidance on how to solve their tasks or learn about a topic in more abstract terms. We also propose a theoretical framework for how (i) purpose of the interaction, (ii) internal factors (e.g., the user's personality), and (iii) external factors (e.g., company policy) together shape the experience (in terms of perceived usefulness and trust). We envision that our framework can be used by future research to further the academic discussion on LLM usage by software engineering practitioners, and to serve as a reference point for the design of future empirical LLM research in this domain.
4/24/2024
🌐
ChatGPT Is Here to Help, Not to Replace Anybody -- An Evaluation of Students' Opinions On Integrating ChatGPT In CS Courses
Bruno Pereira Cipriano, Pedro Alves
0
0
Large Language Models (LLMs) like GPT and Bard are capable of producing code based on textual descriptions, with remarkable efficacy. Such technology will have profound implications for computing education, raising concerns about cheating, excessive dependence, and a decline in computational thinking skills, among others. There has been extensive research on how teachers should handle this challenge but it is also important to understand how students feel about this paradigm shift. In this research, 52 first-year CS students were surveyed in order to assess their views on technologies with code-generation capabilities, both from academic and professional perspectives. Our findings indicate that while students generally favor the academic use of GPT, they don't over rely on it, only mildly asking for its help. Although most students benefit from GPT, some struggle to use it effectively, urging the need for specific GPT training. Opinions on GPT's impact on their professional lives vary, but there is a consensus on its importance in academic practice.
4/29/2024
💬
Can Large Language Models Make the Grade? An Empirical Study Evaluating LLMs Ability to Mark Short Answer Questions in K-12 Education
Owen Henkel, Adam Boxer, Libby Hills, Bill Roberts
0
0
This paper presents reports on a series of experiments with a novel dataset evaluating how well Large Language Models (LLMs) can mark (i.e. grade) open text responses to short answer questions, Specifically, we explore how well different combinations of GPT version and prompt engineering strategies performed at marking real student answers to short answer across different domain areas (Science and History) and grade-levels (spanning ages 5-16) using a new, never-used-before dataset from Carousel, a quizzing platform. We found that GPT-4, with basic few-shot prompting performed well (Kappa, 0.70) and, importantly, very close to human-level performance (0.75). This research builds on prior findings that GPT-4 could reliably score short answer reading comprehension questions at a performance-level very close to that of expert human raters. The proximity to human-level performance, across a variety of subjects and grade levels suggests that LLMs could be a valuable tool for supporting low-stakes formative assessment tasks in K-12 education and has important implications for real-world education delivery.
5/7/2024
🛸
Evaluation of ChatGPT Usability as A Code Generation Tool
Tanha Miah, Hong Zhu
0
0
With the rapid advance of machine learning (ML) technology, large language models (LLMs) are increasingly explored as an intelligent tool to generate program code from natural language specifications. However, existing evaluations of LLMs have focused on their capabilities in comparison with humans. It is desirable to evaluate their usability when deciding on whether to use a LLM in software production. This paper proposes a user centric method. It includes metadata in the test cases of a benchmark to describe their usages, conducts testing in a multi-attempt process that mimic the uses of LLMs, measures LLM generated solutions on a set of quality attributes that reflect usability, and evaluates the performance based on user experiences in the uses of LLMs as a tool. The paper reports an application of the method in the evaluation of ChatGPT usability as a code generation tool for the R programming language. Our experiments demonstrated that ChatGPT is highly useful for generating R program code although it may fail on hard programming tasks. The user experiences are good with overall average number of attempts being 1.61 and the average time of completion being 47.02 seconds. Our experiments also found that the weakest aspect of usability is conciseness, which has a score of 3.80 out of 5. Our experiment also shows that it is hard for human developers to learn from experiences to improve the skill of using ChatGPT to generate code.
4/10/2024