ChatKBQA: A Generate-then-Retrieve Framework for Knowledge Base Question Answering with Fine-tuned Large Language Models
2310.08975
0
0
💬
Abstract
Knowledge Base Question Answering (KBQA) aims to answer natural language questions over large-scale knowledge bases (KBs), which can be summarized into two crucial steps: knowledge retrieval and semantic parsing. However, three core challenges remain: inefficient knowledge retrieval, mistakes of retrieval adversely impacting semantic parsing, and the complexity of previous KBQA methods. To tackle these challenges, we introduce ChatKBQA, a novel and simple generate-then-retrieve KBQA framework, which proposes first generating the logical form with fine-tuned LLMs, then retrieving and replacing entities and relations with an unsupervised retrieval method, to improve both generation and retrieval more directly. Experimental results show that ChatKBQA achieves new state-of-the-art performance on standard KBQA datasets, WebQSP, and CWQ. This work can also be regarded as a new paradigm for combining LLMs with knowledge graphs (KGs) for interpretable and knowledge-required question answering. Our code is publicly available.
Create account to get full access
Overview
- Knowledge Base Question Answering (KBQA) aims to answer natural language questions over large-scale knowledge bases (KBs)
- This task can be broken down into two crucial steps: knowledge retrieval and semantic parsing
- However, three core challenges remain: inefficient knowledge retrieval, mistakes in retrieval adversely impacting semantic parsing, and the complexity of previous KBQA methods
Plain English Explanation
KBQA is a way for computers to answer questions by using the information stored in large databases of knowledge. To do this, the computer first needs to find the relevant information in the database (knowledge retrieval), and then it needs to understand the meaning of the question and determine the correct answer (semantic parsing).
However, existing methods for KBQA still struggle with a few key problems. First, the process of finding the right information in the database is often inefficient and time-consuming. Second, if the computer makes mistakes in finding the information, that can then lead to mistakes in understanding the question and providing the answer. And third, the methods used for KBQA are often quite complex and difficult to implement.
To address these challenges, the researchers introduce a new approach called ChatKBQA. This method first uses powerful language models to generate the logical form of the answer, and then it retrieves the relevant information from the database in a more direct and unsupervised way. The goal is to improve both the generation of the answer and the retrieval of information, leading to better overall performance on KBQA tasks.
Technical Explanation
The paper introduces a novel KBQA framework called ChatKBQA, which aims to address the key challenges in this task. The framework first generates the logical form of the answer using a fine-tuned large language model (LLM), and then retrieves and replaces the relevant entities and relations using an unsupervised retrieval method.
This "generate-then-retrieve" approach is designed to improve both the generation and retrieval components more directly, compared to previous complex KBQA methods that relied on multiple stages of processing.
The researchers evaluate ChatKBQA on standard KBQA datasets, WebQSP and CWQ, and show that it achieves new state-of-the-art performance. This work can be seen as a new paradigm for combining LLMs with knowledge graphs (KGs) for interpretable and knowledge-required question answering.
Critical Analysis
The paper presents a promising approach to KBQA, but it does acknowledge some limitations. For example, the unsupervised retrieval method used in ChatKBQA may not be as effective as supervised techniques in certain scenarios. Additionally, the performance of the framework is still dependent on the quality and coverage of the underlying knowledge base.
Further research could explore ways to better integrate the LLM and retrieval components, or investigate methods to stimulate the LLM with heuristic information to improve the overall KBQA performance.
Conclusion
The ChatKBQA framework represents a novel and promising approach to KBQA, which aims to address key challenges in this task. By combining the generation capabilities of LLMs with an unsupervised retrieval method, the framework achieves new state-of-the-art performance on standard KBQA benchmarks.
This work can be seen as a step towards more interpretable and knowledge-driven question answering systems, which can leverage the strengths of both language models and structured knowledge bases. As the field of KBQA continues to evolve, further research in this direction may lead to even more robust and effective solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Learn-Then-Reason Model Towards Generalization in Knowledge Base Question Answering
Lingxi Zhang, Jing Zhang, Yanling Wang, Cuiping Li, Hong Chen
0
0
Large-scale knowledge bases (KBs) like Freebase and Wikidata house millions of structured knowledge. Knowledge Base Question Answering (KBQA) provides a user-friendly way to access these valuable KBs via asking natural language questions. In order to improve the generalization capabilities of KBQA models, extensive research has embraced a retrieve-then-reason framework to retrieve relevant evidence for logical expression generation. These multi-stage efforts prioritize acquiring external sources but overlook the incorporation of new knowledge into their model parameters. In effect, even advanced language models and retrievers have knowledge boundaries, thereby limiting the generalization capabilities of previous KBQA models. Therefore, this paper develops KBLLaMA, which follows a learn-then-reason framework to inject new KB knowledge into a large language model for flexible end-to-end KBQA. At the core of KBLLaMA, we study (1) how to organize new knowledge about KBQA and (2) how to facilitate the learning of the organized knowledge. Extensive experiments on various KBQA generalization tasks showcase the state-of-the-art performance of KBLLaMA. Especially on the general benchmark GrailQA and domain-specific benchmark Bio-chemical, KBLLaMA respectively derives a performance gain of up to 3.8% and 9.8% compared to the baselines.
6/24/2024
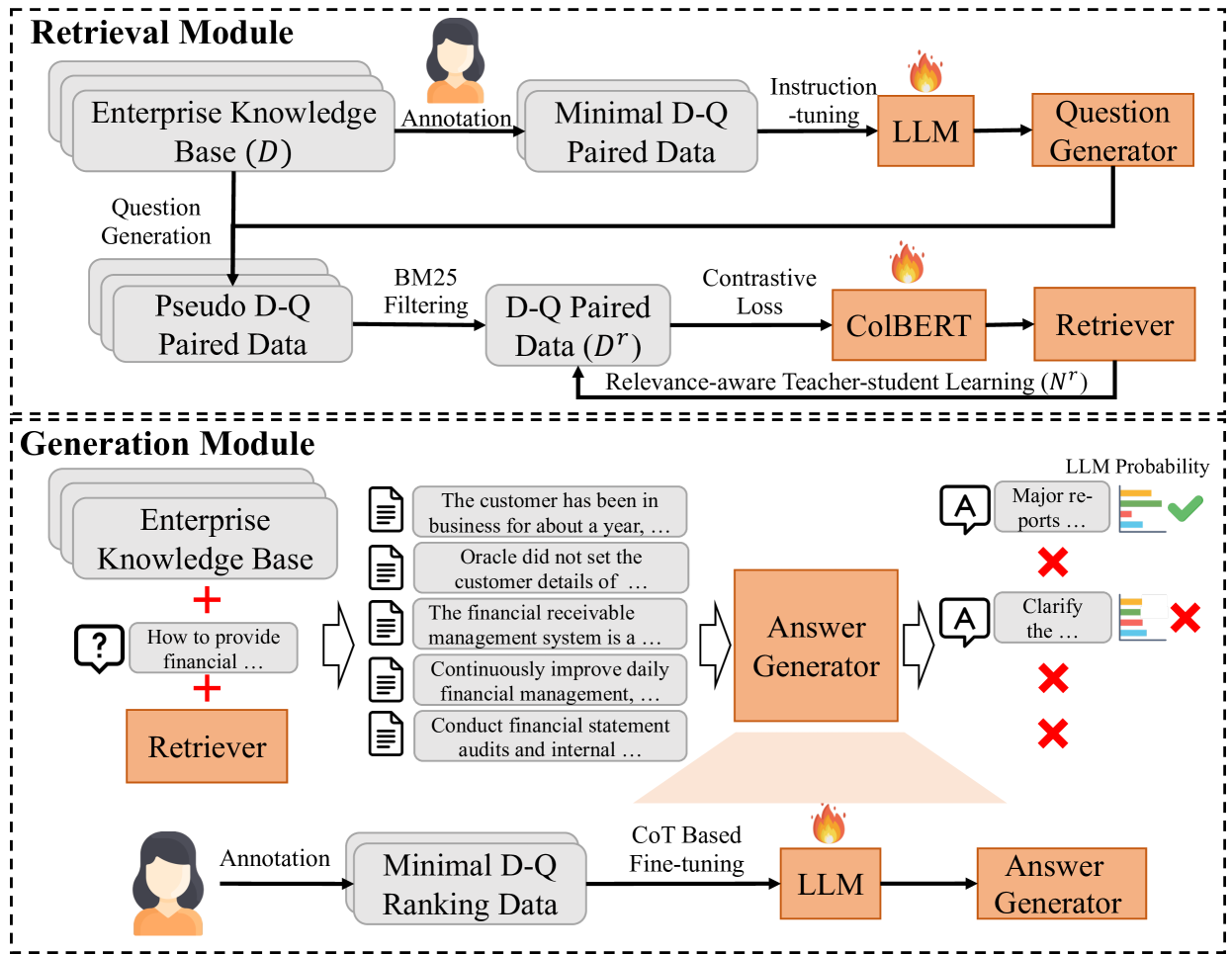
Enhancing Question Answering for Enterprise Knowledge Bases using Large Language Models
Feihu Jiang, Chuan Qin, Kaichun Yao, Chuyu Fang, Fuzhen Zhuang, Hengshu Zhu, Hui Xiong
0
0
Efficient knowledge management plays a pivotal role in augmenting both the operational efficiency and the innovative capacity of businesses and organizations. By indexing knowledge through vectorization, a variety of knowledge retrieval methods have emerged, significantly enhancing the efficacy of knowledge management systems. Recently, the rapid advancements in generative natural language processing technologies paved the way for generating precise and coherent answers after retrieving relevant documents tailored to user queries. However, for enterprise knowledge bases, assembling extensive training data from scratch for knowledge retrieval and generation is a formidable challenge due to the privacy and security policies of private data, frequently entailing substantial costs. To address the challenge above, in this paper, we propose EKRG, a novel Retrieval-Generation framework based on large language models (LLMs), expertly designed to enable question-answering for Enterprise Knowledge bases with limited annotation costs. Specifically, for the retrieval process, we first introduce an instruction-tuning method using an LLM to generate sufficient document-question pairs for training a knowledge retriever. This method, through carefully designed instructions, efficiently generates diverse questions for enterprise knowledge bases, encompassing both fact-oriented and solution-oriented knowledge. Additionally, we develop a relevance-aware teacher-student learning strategy to further enhance the efficiency of the training process. For the generation process, we propose a novel chain of thought (CoT) based fine-tuning method to empower the LLM-based generator to adeptly respond to user questions using retrieved documents. Finally, extensive experiments on real-world datasets have demonstrated the effectiveness of our proposed framework.
4/23/2024
🛸
Retrieval Augmented Generation for Domain-specific Question Answering
Sanat Sharma, David Seunghyun Yoon, Franck Dernoncourt, Dewang Sultania, Karishma Bagga, Mengjiao Zhang, Trung Bui, Varun Kotte
0
0
Question answering (QA) has become an important application in the advanced development of large language models. General pre-trained large language models for question-answering are not trained to properly understand the knowledge or terminology for a specific domain, such as finance, healthcare, education, and customer service for a product. To better cater to domain-specific understanding, we build an in-house question-answering system for Adobe products. We propose a novel framework to compile a large question-answer database and develop the approach for retrieval-aware finetuning of a Large Language model. We showcase that fine-tuning the retriever leads to major improvements in the final generation. Our overall approach reduces hallucinations during generation while keeping in context the latest retrieval information for contextual grounding.
5/30/2024

Cost-efficient Knowledge-based Question Answering with Large Language Models
Junnan Dong, Qinggang Zhang, Chuang Zhou, Hao Chen, Daochen Zha, Xiao Huang
0
0
Knowledge-based question answering (KBQA) is widely used in many scenarios that necessitate domain knowledge. Large language models (LLMs) bring opportunities to KBQA, while their costs are significantly higher and absence of domain-specific knowledge during pre-training. We are motivated to combine LLMs and prior small models on knowledge graphs (KGMs) for both inferential accuracy and cost saving. However, it remains challenging since accuracy and cost are not readily combined in the optimization as two distinct metrics. It is also laborious for model selection since different models excel in diverse knowledge. To this end, we propose Coke, a novel cost-efficient strategy for KBQA with LLMs, modeled as a tailored multi-armed bandit problem to minimize calls to LLMs within limited budgets. We first formulate the accuracy expectation with a cluster-level Thompson Sampling for either KGMs or LLMs. A context-aware policy is optimized to further distinguish the expert model subject to the question semantics. The overall decision is bounded by the cost regret according to historical expenditure on failures. Extensive experiments showcase the superior performance of Coke, which moves the Pareto frontier with up to 20.89% saving of GPT-4 fees while achieving a 2.74% higher accuracy on the benchmark datasets.
5/28/2024