SGSH: Stimulate Large Language Models with Skeleton Heuristics for Knowledge Base Question Generation
2404.01923
0
0
Abstract
Knowledge base question generation (KBQG) aims to generate natural language questions from a set of triplet facts extracted from KB. Existing methods have significantly boosted the performance of KBQG via pre-trained language models (PLMs) thanks to the richly endowed semantic knowledge. With the advance of pre-training techniques, large language models (LLMs) (e.g., GPT-3.5) undoubtedly possess much more semantic knowledge. Therefore, how to effectively organize and exploit the abundant knowledge for KBQG becomes the focus of our study. In this work, we propose SGSH--a simple and effective framework to Stimulate GPT-3.5 with Skeleton Heuristics to enhance KBQG. The framework incorporates skeleton heuristics, which provides more fine-grained guidance associated with each input to stimulate LLMs to generate optimal questions, encompassing essential elements like the question phrase and the auxiliary verb.More specifically, we devise an automatic data construction strategy leveraging ChatGPT to construct a skeleton training dataset, based on which we employ a soft prompting approach to train a BART model dedicated to generating the skeleton associated with each input. Subsequently, skeleton heuristics are encoded into the prompt to incentivize GPT-3.5 to generate desired questions. Extensive experiments demonstrate that SGSH derives the new state-of-the-art performance on the KBQG tasks.
Create account to get full access
Overview
- The paper presents a new technique called SGSH (Stimulate Large Language Models with Skeleton Heuristics) for generating knowledge base questions.
- The approach aims to improve the performance of large language models in question generation tasks by providing them with "skeleton heuristics" - structural templates that guide the model's generation process.
- The authors conduct a pilot study and then describe their full methodology, which involves using the skeleton heuristics to prompt the model and post-processing the generated questions.
- They evaluate SGSH on several knowledge base question generation benchmarks and find that it outperforms previous state-of-the-art methods.
Plain English Explanation
The paper explores a way to help large language models, like GPT-3, become better at generating questions about information stored in knowledge bases. Knowledge bases are structured databases of facts and information.
The key idea is to provide the language model with "skeleton heuristics" - templates or structural guidelines that shape the questions the model generates. For example, a skeleton heuristic could specify that a question should start with "What is..." and contain a placeholder for a entity name from the knowledge base.
By giving the model these scaffolding structures, the authors found they could improve the quality and relevance of the questions it generated, compared to letting the model generate questions freely. The paper describes a pilot study to test this approach, and then the full methodology they developed.
The authors evaluate SGSH on standard benchmarks for knowledge base question generation, and show it outperforms previous state-of-the-art methods. This suggests that carefully designing prompts and templates can help large language models perform better on specific tasks, like generating informative questions about structured data.
Technical Explanation
The core idea behind SGSH is to leverage "skeleton heuristics" to guide the question generation process of large language models. These skeleton heuristics are structural templates that specify the desired format and content of the generated questions.
The authors first conduct a pilot study to explore the potential of this approach. They design several skeleton heuristics targeting different types of knowledge base facts, such as entity-attribute relationships and entity-entity connections. They then use these heuristics to prompt a language model and analyze the generated questions.
The full SGSH methodology builds on the insights from the pilot. It involves three main steps:
-
Prompt Engineering: The authors engineer prompts that combine the skeleton heuristics with placeholders for knowledge base entities. This provides the language model with a clear structural framework to follow.
-
Language Model Stimulation: The engineered prompts are used to "stimulate" a large pre-trained language model, such as GPT-3, to generate questions.
-
Post-Processing: The generated questions are post-processed to ensure they conform to the desired structure and are relevant to the knowledge base facts.
The authors evaluate SGSH on several knowledge base question generation benchmarks, including WebQuestions and ComplexWebQuestions. They find that SGSH outperforms previous state-of-the-art methods, demonstrating the effectiveness of their skeleton heuristic approach.
Critical Analysis
The paper makes a compelling case for the use of skeleton heuristics to improve the performance of large language models on knowledge base question generation tasks. The authors provide a thorough pilot study and a well-designed methodology that yields strong empirical results.
However, a potential limitation of the approach is its reliance on carefully engineered prompts and post-processing steps. While this allows for greater control and structure in the question generation process, it may also limit the model's ability to generate more open-ended or creative questions. Additionally, the effectiveness of the approach may be sensitive to the specific design of the skeleton heuristics, which could require additional effort to generalize to new domains or knowledge bases.
Another area for further exploration is the scalability of SGSH. The paper focuses on evaluating the approach on standard benchmarks, but it would be valuable to assess its performance on larger-scale, real-world knowledge bases and question generation tasks.
Overall, the SGSH technique represents an interesting and promising approach to leveraging the capabilities of large language models for knowledge-driven applications. The paper's findings contribute to the growing body of research on prompt engineering and task-specific model adaptation, which could have important implications for the future development of more versatile and effective AI systems.
Conclusion
The SGSH paper presents a novel technique for improving the performance of large language models on knowledge base question generation tasks. By providing the models with carefully designed "skeleton heuristics" - structural templates that guide the question generation process - the authors demonstrate significant improvements over previous state-of-the-art methods.
This work highlights the potential of combining the powerful language modeling capabilities of large neural networks with domain-specific knowledge and prompting strategies. While the approach has some limitations, it represents an important step forward in the ongoing efforts to make AI systems more effective at interacting with and reasoning about structured information.
As large language models continue to advance, techniques like SGSH may become increasingly valuable for a wide range of applications, from educational technologies and virtual assistants to scientific and industrial knowledge management. The insights gained from this research could inspire further innovations in prompt engineering and task-driven model adaptation, ultimately leading to more capable and versatile AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Enhancing Question Answering for Enterprise Knowledge Bases using Large Language Models
Feihu Jiang, Chuan Qin, Kaichun Yao, Chuyu Fang, Fuzhen Zhuang, Hengshu Zhu, Hui Xiong
0
0
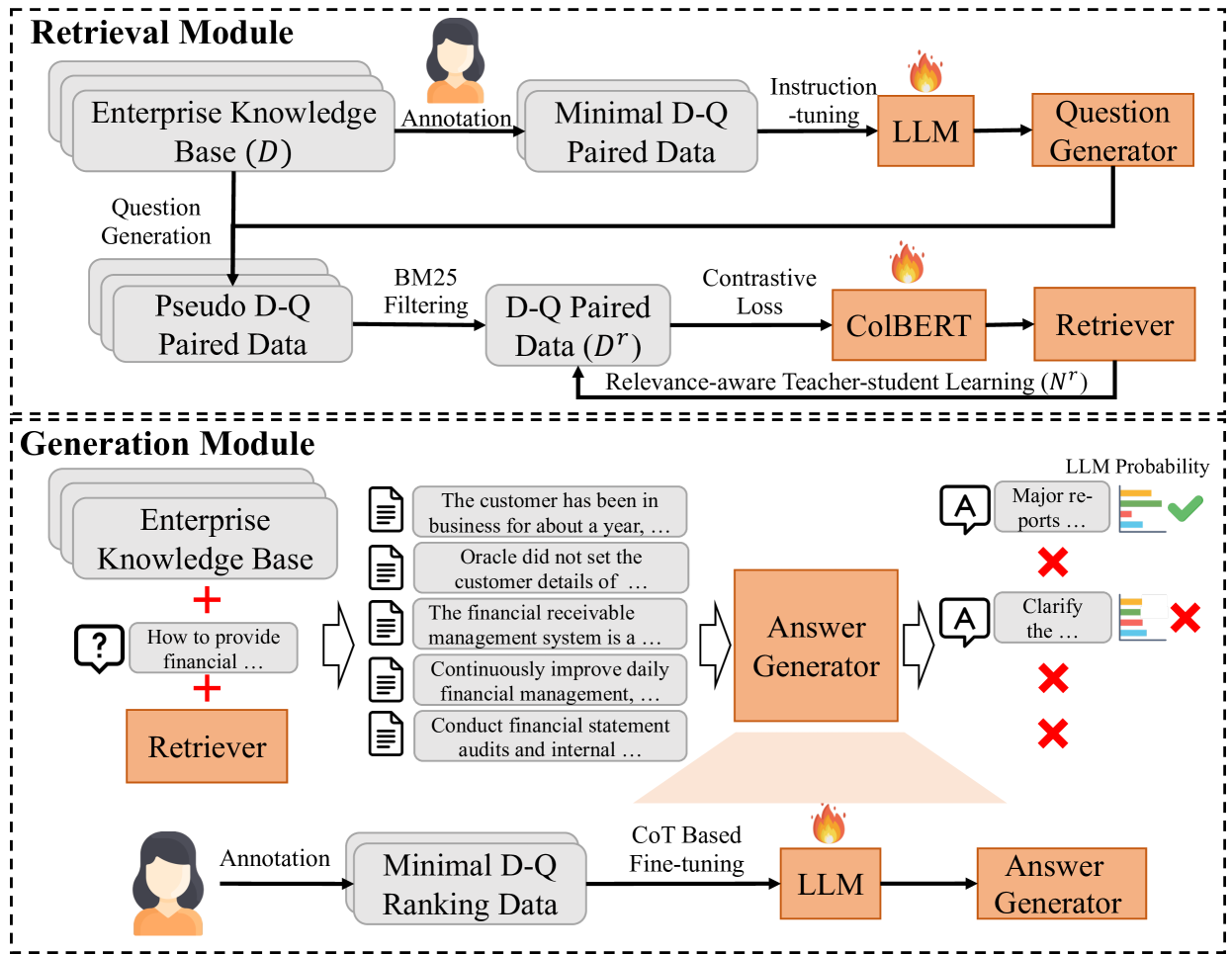
Efficient knowledge management plays a pivotal role in augmenting both the operational efficiency and the innovative capacity of businesses and organizations. By indexing knowledge through vectorization, a variety of knowledge retrieval methods have emerged, significantly enhancing the efficacy of knowledge management systems. Recently, the rapid advancements in generative natural language processing technologies paved the way for generating precise and coherent answers after retrieving relevant documents tailored to user queries. However, for enterprise knowledge bases, assembling extensive training data from scratch for knowledge retrieval and generation is a formidable challenge due to the privacy and security policies of private data, frequently entailing substantial costs. To address the challenge above, in this paper, we propose EKRG, a novel Retrieval-Generation framework based on large language models (LLMs), expertly designed to enable question-answering for Enterprise Knowledge bases with limited annotation costs. Specifically, for the retrieval process, we first introduce an instruction-tuning method using an LLM to generate sufficient document-question pairs for training a knowledge retriever. This method, through carefully designed instructions, efficiently generates diverse questions for enterprise knowledge bases, encompassing both fact-oriented and solution-oriented knowledge. Additionally, we develop a relevance-aware teacher-student learning strategy to further enhance the efficiency of the training process. For the generation process, we propose a novel chain of thought (CoT) based fine-tuning method to empower the LLM-based generator to adeptly respond to user questions using retrieved documents. Finally, extensive experiments on real-world datasets have demonstrated the effectiveness of our proposed framework.
4/23/2024
💬
ChatKBQA: A Generate-then-Retrieve Framework for Knowledge Base Question Answering with Fine-tuned Large Language Models
Haoran Luo, Haihong E, Zichen Tang, Shiyao Peng, Yikai Guo, Wentai Zhang, Chenghao Ma, Guanting Dong, Meina Song, Wei Lin, Yifan Zhu, Luu Anh Tuan
0
0
Knowledge Base Question Answering (KBQA) aims to answer natural language questions over large-scale knowledge bases (KBs), which can be summarized into two crucial steps: knowledge retrieval and semantic parsing. However, three core challenges remain: inefficient knowledge retrieval, mistakes of retrieval adversely impacting semantic parsing, and the complexity of previous KBQA methods. To tackle these challenges, we introduce ChatKBQA, a novel and simple generate-then-retrieve KBQA framework, which proposes first generating the logical form with fine-tuned LLMs, then retrieving and replacing entities and relations with an unsupervised retrieval method, to improve both generation and retrieval more directly. Experimental results show that ChatKBQA achieves new state-of-the-art performance on standard KBQA datasets, WebQSP, and CWQ. This work can also be regarded as a new paradigm for combining LLMs with knowledge graphs (KGs) for interpretable and knowledge-required question answering. Our code is publicly available.
5/31/2024
KnowGPT: Knowledge Graph based Prompting for Large Language Models
Qinggang Zhang, Junnan Dong, Hao Chen, Daochen Zha, Zailiang Yu, Xiao Huang
0
0
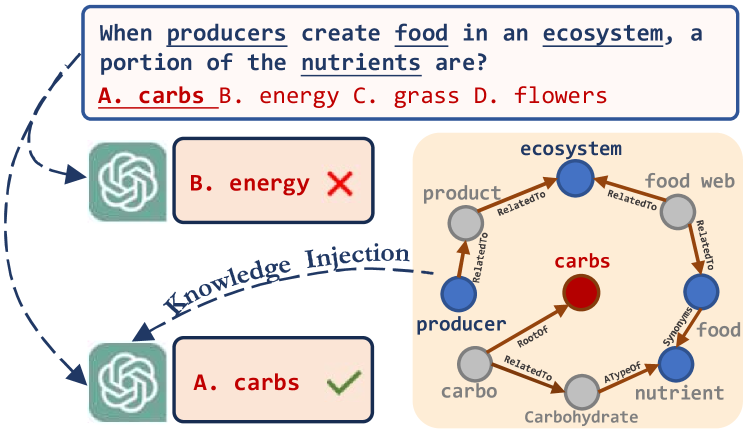
Large Language Models (LLMs) have demonstrated remarkable capabilities in many real-world applications. Nonetheless, LLMs are often criticized for their tendency to produce hallucinations, wherein the models fabricate incorrect statements on tasks beyond their knowledge and perception. To alleviate this issue, researchers have explored leveraging the factual knowledge in knowledge graphs (KGs) to ground the LLM's responses in established facts and principles. However, most state-of-the-art LLMs are closed-source, making it challenging to develop a prompting framework that can efficiently and effectively integrate KGs into LLMs with hard prompts only. Generally, existing KG-enhanced LLMs usually suffer from three critical issues, including huge search space, high API costs, and laborious prompt engineering, that impede their widespread application in practice. To this end, we introduce a novel Knowledge Graph based PrompTing framework, namely KnowGPT, to enhance LLMs with domain knowledge. KnowGPT contains a knowledge extraction module to extract the most informative knowledge from KGs, and a context-aware prompt construction module to automatically convert extracted knowledge into effective prompts. Experiments on three benchmarks demonstrate that KnowGPT significantly outperforms all competitors. Notably, KnowGPT achieves a 92.6% accuracy on OpenbookQA leaderboard, comparable to human-level performance.
6/5/2024
💬
Enhancing Text-based Knowledge Graph Completion with Zero-Shot Large Language Models: A Focus on Semantic Enhancement
Rui Yang, Jiahao Zhu, Jianping Man, Li Fang, Yi Zhou
0
0
The design and development of text-based knowledge graph completion (KGC) methods leveraging textual entity descriptions are at the forefront of research. These methods involve advanced optimization techniques such as soft prompts and contrastive learning to enhance KGC models. The effectiveness of text-based methods largely hinges on the quality and richness of the training data. Large language models (LLMs) can utilize straightforward prompts to alter text data, thereby enabling data augmentation for KGC. Nevertheless, LLMs typically demand substantial computational resources. To address these issues, we introduce a framework termed constrained prompts for KGC (CP-KGC). This CP-KGC framework designs prompts that adapt to different datasets to enhance semantic richness. Additionally, CP-KGC employs a context constraint strategy to effectively identify polysemous entities within KGC datasets. Through extensive experimentation, we have verified the effectiveness of this framework. Even after quantization, the LLM (Qwen-7B-Chat-int4) still enhances the performance of text-based KGC methods footnote{Code and datasets are available at href{https://github.com/sjlmg/CP-KGC}{https://github.com/sjlmg/CP-KGC}}. This study extends the performance limits of existing models and promotes further integration of KGC with LLMs.
6/28/2024