Chatlaw: A Multi-Agent Collaborative Legal Assistant with Knowledge Graph Enhanced Mixture-of-Experts Large Language Model

0

Sign in to get full access
Overview
- ChatLaw is an open-source legal large language model (LLM) that integrates external knowledge bases to enhance legal reasoning and decision-making.
- The model aims to provide a powerful tool for legal professionals, researchers, and the general public to access and leverage a wealth of legal knowledge.
- Key features include natural language processing capabilities, access to curated legal databases, and explainable AI to improve transparency and trust.
Plain English Explanation
ChatLaw is a new AI system that has been designed to help people with legal tasks and questions. It is an advanced language model, which means it can understand and generate human-like text, but it has also been specially trained on a lot of legal information and data.
This allows ChatLaw to do things like summarize legal documents, provide legal advice and analysis, and even assist with legal research and decision-making. The system has been designed to be open-source, meaning the code and models are freely available for others to use and build upon.
One of the key things that sets ChatLaw apart is that it integrates information from various external legal knowledge bases. This allows it to draw upon a much larger pool of legal knowledge and expertise than a typical AI system. For example, it might be able to provide more comprehensive and accurate responses to legal questions by combining information from court rulings, legal textbooks, and other authoritative sources.
The goal is to make legal knowledge and services more accessible and understandable to a wider range of people, not just legal professionals. ChatLaw aims to be a powerful tool that can help individuals, businesses, and organizations navigate the complex world of law more effectively.
Technical Explanation
ChatLaw is an open-source legal large language model (LLM) that has been designed to integrate external knowledge bases to enhance its legal reasoning and decision-making capabilities. The model is built on top of a powerful natural language processing (NLP) foundation, which allows it to understand and generate human-like text.
One of the key innovations of ChatLaw is its ability to seamlessly integrate information from various curated legal databases and knowledge sources. This includes case law, statutes, regulations, legal treatises, and other authoritative legal materials. By combining this external knowledge with its own sophisticated language understanding, ChatLaw can provide more comprehensive and accurate responses to legal queries.
The system also includes explainable AI (XAI) components, which help to improve the transparency and interpretability of its decision-making processes. This is important in the legal domain, where trust and accountability are paramount. Users can better understand the reasoning behind ChatLaw's outputs, which can enhance their confidence in the system's recommendations.
Overall, the goal of ChatLaw is to provide a powerful, open-source tool that can help legal professionals, researchers, and the general public access and leverage a wealth of legal knowledge. By integrating external data sources and employing advanced NLP and XAI techniques, the model aims to be a valuable resource for tasks such as legal research, analysis, and decision-making.
Critical Analysis
The ChatLaw project represents an ambitious and potentially impactful effort to harness the power of large language models and external knowledge bases to enhance legal services and decision-making. The integration of curated legal data sources is a particularly compelling aspect of the system, as it allows ChatLaw to draw upon a much broader and more authoritative pool of information than a typical LLM.
However, it's important to note that the success of ChatLaw will ultimately depend on the quality and comprehensiveness of the underlying data and knowledge bases. If there are gaps or biases in the information that the system is trained on, this could lead to inaccurate or biased outputs, which could be especially problematic in the legal domain.
Additionally, while the inclusion of explainable AI components is a positive step towards transparency, there may still be challenges in fully understanding and trusting the model's decision-making processes, particularly for complex or ambiguous legal questions. Ongoing research and evaluation will be necessary to address these concerns and refine the system over time.
It will also be important to carefully consider the ethical implications of deploying a powerful AI system in the legal domain, where the stakes are high and the potential for harm is significant. Issues around data privacy, algorithmic bias, and the appropriate use of AI in legal decision-making will need to be thoroughly addressed.
Despite these potential challenges, the ChatLaw project represents an important and innovative step forward in the integration of AI and legal services. By making legal knowledge and expertise more accessible and understandable to a wider audience, the system has the potential to significantly improve the accessibility and quality of legal services, ultimately benefiting individuals, businesses, and society as a whole.
Conclusion
ChatLaw is an exciting new open-source legal large language model that aims to revolutionize the way we access and leverage legal knowledge. By integrating a wealth of curated legal data and employing advanced natural language processing and explainable AI techniques, the system has the potential to become a valuable tool for legal professionals, researchers, and the general public alike.
The project's emphasis on transparency, accessibility, and the integration of external knowledge sources sets it apart from traditional legal AI systems. However, critical analysis highlights the importance of carefully addressing potential challenges around data quality, algorithmic bias, and ethical considerations as the system continues to evolve.
Overall, the ChatLaw project represents a significant step forward in the convergence of AI and legal services, with the ultimate goal of making the law more understandable, accessible, and effective for all. As the field of legal AI continues to advance, initiatives like ChatLaw will play a crucial role in shaping the future of the legal landscape.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Chatlaw: A Multi-Agent Collaborative Legal Assistant with Knowledge Graph Enhanced Mixture-of-Experts Large Language Model
Jiaxi Cui, Munan Ning, Zongjian Li, Bohua Chen, Yang Yan, Hao Li, Bin Ling, Yonghong Tian, Li Yuan
AI legal assistants based on Large Language Models (LLMs) can provide accessible legal consulting services, but the hallucination problem poses potential legal risks. This paper presents Chatlaw, an innovative legal assistant utilizing a Mixture-of-Experts (MoE) model and a multi-agent system to enhance the reliability and accuracy of AI-driven legal services. By integrating knowledge graphs with artificial screening, we construct a high-quality legal dataset to train the MoE model. This model utilizes different experts to address various legal issues, optimizing the accuracy of legal responses. Additionally, Standardized Operating Procedures (SOP), modeled after real law firm workflows, significantly reduce errors and hallucinations in legal services. Our MoE model outperforms GPT-4 in the Lawbench and Unified Qualification Exam for Legal Professionals by 7.73% in accuracy and 11 points, respectively, and also surpasses other models in multiple dimensions during real-case consultations, demonstrating our robust capability for legal consultation.
Read more5/31/2024
0
LawLuo: A Chinese Law Firm Co-run by LLM Agents
Jingyun Sun, Chengxiao Dai, Zhongze Luo, Yangbo Chang, Yang Li
Large Language Models (LLMs) demonstrate substantial potential in delivering legal consultation services to users without a legal background, attributed to their superior text comprehension and generation capabilities. Nonetheless, existing Chinese legal LLMs limit interaction to a single model-user dialogue, unlike the collaborative consultations typical of law firms, where multiple staff members contribute to a single consultation. This limitation prevents an authentic consultation experience. Additionally, extant Chinese legal LLMs suffer from critical limitations: (1) insufficient control over the quality of instruction fine-tuning data; (2) increased model hallucination resulting from users' ambiguous queries; and (3) a reduction in the model's ability to follow instructions over multiple dialogue turns. In response to these challenges, we propose a novel legal dialogue framework that leverages the collaborative capabilities of multiple LLM agents, termed LawLuo. This framework encompasses four agents: a receptionist, a lawyer, a secretary, and a boss, each responsible for different functionalities, collaboratively providing a comprehensive legal consultation to users. Additionally, we constructed two high-quality legal dialogue datasets, KINLED and MURLED, and fine-tuned ChatGLM-3-6b using these datasets. We propose a legal query clarification algorithm called ToLC. Experimental results demonstrate that LawLuo outperforms baseline LLMs, including GPT-4, across three dimensions: lawyer-like language style, the usefulness of legal advice, and the accuracy of legal knowledge. Our code and datasets are available at https://github.com/NEFUJing/LawLuo.
Read more7/24/2024
1
Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models
Matthew Dahl, Varun Magesh, Mirac Suzgun, Daniel E. Ho
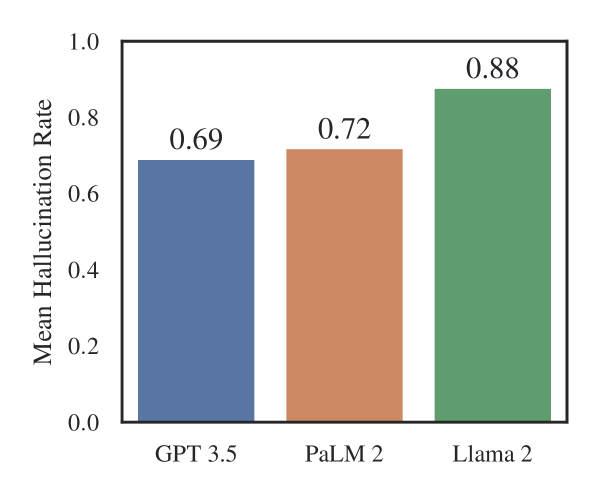
Do large language models (LLMs) know the law? These models are increasingly being used to augment legal practice, education, and research, yet their revolutionary potential is threatened by the presence of hallucinations -- textual output that is not consistent with legal facts. We present the first systematic evidence of these hallucinations, documenting LLMs' varying performance across jurisdictions, courts, time periods, and cases. Our work makes four key contributions. First, we develop a typology of legal hallucinations, providing a conceptual framework for future research in this area. Second, we find that legal hallucinations are alarmingly prevalent, occurring between 58% of the time with ChatGPT 4 and 88% with Llama 2, when these models are asked specific, verifiable questions about random federal court cases. Third, we illustrate that LLMs often fail to correct a user's incorrect legal assumptions in a contra-factual question setup. Fourth, we provide evidence that LLMs cannot always predict, or do not always know, when they are producing legal hallucinations. Taken together, our findings caution against the rapid and unsupervised integration of popular LLMs into legal tasks. Even experienced lawyers must remain wary of legal hallucinations, and the risks are highest for those who stand to benefit from LLMs the most -- pro se litigants or those without access to traditional legal resources.
Read more6/24/2024

0
Optimizing Numerical Estimation and Operational Efficiency in the Legal Domain through Large Language Models
Jia-Hong Huang, Chao-Chun Yang, Yixian Shen, Alessio M. Pacces, Evangelos Kanoulas
The legal landscape encompasses a wide array of lawsuit types, presenting lawyers with challenges in delivering timely and accurate information to clients, particularly concerning critical aspects like potential imprisonment duration or financial repercussions. Compounded by the scarcity of legal experts, there's an urgent need to enhance the efficiency of traditional legal workflows. Recent advances in deep learning, especially Large Language Models (LLMs), offer promising solutions to this challenge. Leveraging LLMs' mathematical reasoning capabilities, we propose a novel approach integrating LLM-based methodologies with specially designed prompts to address precision requirements in legal Artificial Intelligence (LegalAI) applications. The proposed work seeks to bridge the gap between traditional legal practices and modern technological advancements, paving the way for a more accessible, efficient, and equitable legal system. To validate this method, we introduce a curated dataset tailored to precision-oriented LegalAI tasks, serving as a benchmark for evaluating LLM-based approaches. Extensive experimentation confirms the efficacy of our methodology in generating accurate numerical estimates within the legal domain, emphasizing the role of LLMs in streamlining legal processes and meeting the evolving demands of LegalAI.
Read more7/30/2024