Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models
2401.01301
2
0
Abstract
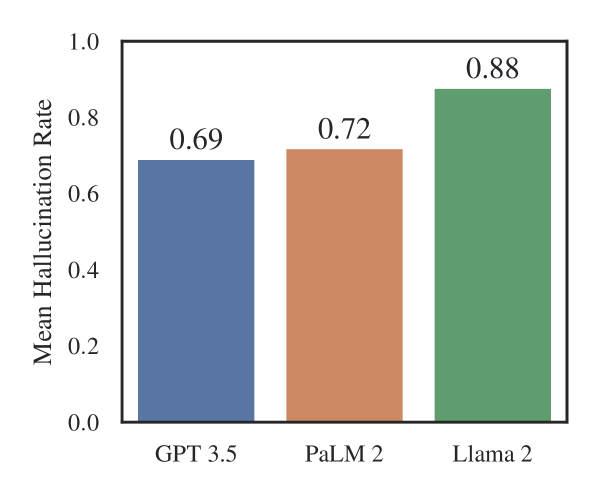
Do large language models (LLMs) know the law? These models are increasingly being used to augment legal practice, education, and research, yet their revolutionary potential is threatened by the presence of hallucinations -- textual output that is not consistent with legal facts. We present the first systematic evidence of these hallucinations, documenting LLMs' varying performance across jurisdictions, courts, time periods, and cases. Our work makes four key contributions. First, we develop a typology of legal hallucinations, providing a conceptual framework for future research in this area. Second, we find that legal hallucinations are alarmingly prevalent, occurring between 58% of the time with ChatGPT 4 and 88% with Llama 2, when these models are asked specific, verifiable questions about random federal court cases. Third, we illustrate that LLMs often fail to correct a user's incorrect legal assumptions in a contra-factual question setup. Fourth, we provide evidence that LLMs cannot always predict, or do not always know, when they are producing legal hallucinations. Taken together, our findings caution against the rapid and unsupervised integration of popular LLMs into legal tasks. Even experienced lawyers must remain wary of legal hallucinations, and the risks are highest for those who stand to benefit from LLMs the most -- pro se litigants or those without access to traditional legal resources.
Create account to get full access
Overview
- This paper examines the problem of "legal hallucinations" in large language models (LLMs), where the models generate legally relevant content that is factually incorrect or nonsensical.
- The researchers profile the occurrence of these legal hallucinations across a range of LLM architectures and evaluate their potential impact on legal tasks.
- The findings provide insights into the limitations of current LLMs when it comes to legal reasoning and highlight the need for more robust approaches to ensure the reliability and trustworthiness of LLM-powered legal applications.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. However, these models can sometimes produce content that is legally inaccurate or nonsensical, a phenomenon known as "legal hallucinations."
This paper explores the prevalence of legal hallucinations across different LLM architectures and examines their potential impact on legal tasks. The researchers found that these legal hallucinations can be surprisingly common, even in LLMs that are generally considered to be high-performing.
This is a significant concern because LLMs are increasingly being used in legal applications, such as contract analysis, legal research, and even legal decision-making. If these models are generating inaccurate or misleading legal information, it could have serious consequences for the individuals and organizations relying on their outputs.
To address this issue, the researchers suggest the need for more robust approaches to ensure the reliability and trustworthiness of LLM-powered legal applications. This might involve techniques such as better data curation, more comprehensive testing, and the development of specialized legal reasoning capabilities within the models.
Overall, this paper highlights an important challenge facing the use of LLMs in high-stakes domains like law, and underscores the need for continued research and development to address the limitations of these powerful, yet fallible, AI systems.
Technical Explanation
The paper begins by establishing the terminology and background concepts related to legal hallucinations in LLMs. The researchers define legal hallucinations as instances where an LLM generates legally relevant content that is factually incorrect or nonsensical, often due to the model's inability to accurately reason about legal concepts and principles.
To investigate the prevalence of these legal hallucinations, the researchers conducted a series of experiments across a range of LLM architectures, including GPT-3, InstructGPT, and PaLM. They designed prompts that were intended to elicit legally relevant responses from the models and then analyzed the outputs for accuracy, coherence, and adherence to legal principles.
The results of these experiments revealed that legal hallucinations were surprisingly common, even in models that are generally considered to be high-performing. The researchers found that the frequency and severity of the legal hallucinations varied across different model architectures and prompt types, suggesting that the underlying capabilities and limitations of the models play a significant role in their ability to reason about legal concepts.
To further explore the potential impact of these legal hallucinations, the researchers also conducted case studies involving the use of LLMs for legal tasks, such as contract analysis and legal research. These case studies highlighted the ways in which legal hallucinations could lead to misleading or even harmful outputs, underscoring the importance of addressing this issue.
Critical Analysis
The researchers acknowledge several limitations and areas for further research in their paper. For example, they note that their experiments were limited to a relatively small set of prompts and LLM architectures, and that more comprehensive testing would be needed to fully characterize the scope and nature of legal hallucinations in LLMs.
Additionally, the paper does not delve deeply into the underlying causes of legal hallucinations, such as the training data and modeling techniques used to develop the LLMs. A more thorough investigation of these factors could potentially yield insights that could inform the development of more robust and reliable LLM-powered legal applications.
It is also worth considering whether the issue of legal hallucinations is unique to the legal domain or if it is symptomatic of a more general challenge in ensuring the trustworthiness of LLM outputs, especially in high-stakes applications.
Conclusion
This paper provides a valuable contribution to the growing body of research on the limitations and challenges of using large language models in high-stakes domains like law. By profiling the prevalence of legal hallucinations across a range of LLM architectures, the researchers have highlighted a significant obstacle to the reliable and trustworthy deployment of LLM-powered legal applications.
The findings of this study underscore the need for continued research and development to address the fundamental limitations of current LLMs, and to develop more robust approaches that can ensure the accuracy and reliability of legally relevant content generated by these powerful AI systems.
As LLMs become increasingly ubiquitous in various industries and applications, it is crucial that we continue to carefully evaluate their capabilities and limitations, and work towards solutions that mitigate the risks of legal hallucinations and other forms of unreliable or misleading output.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Survey on Hallucination in Large Vision-Language Models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, Wei Peng
0
0
Recent development of Large Vision-Language Models (LVLMs) has attracted growing attention within the AI landscape for its practical implementation potential. However, ``hallucination'', or more specifically, the misalignment between factual visual content and corresponding textual generation, poses a significant challenge of utilizing LVLMs. In this comprehensive survey, we dissect LVLM-related hallucinations in an attempt to establish an overview and facilitate future mitigation. Our scrutiny starts with a clarification of the concept of hallucinations in LVLMs, presenting a variety of hallucination symptoms and highlighting the unique challenges inherent in LVLM hallucinations. Subsequently, we outline the benchmarks and methodologies tailored specifically for evaluating hallucinations unique to LVLMs. Additionally, we delve into an investigation of the root causes of these hallucinations, encompassing insights from the training data and model components. We also critically review existing methods for mitigating hallucinations. The open questions and future directions pertaining to hallucinations within LVLMs are discussed to conclude this survey.
5/7/2024
On Large Language Models' Hallucination with Regard to Known Facts
Che Jiang, Biqing Qi, Xiangyu Hong, Dayuan Fu, Yang Cheng, Fandong Meng, Mo Yu, Bowen Zhou, Jie Zhou
0
0
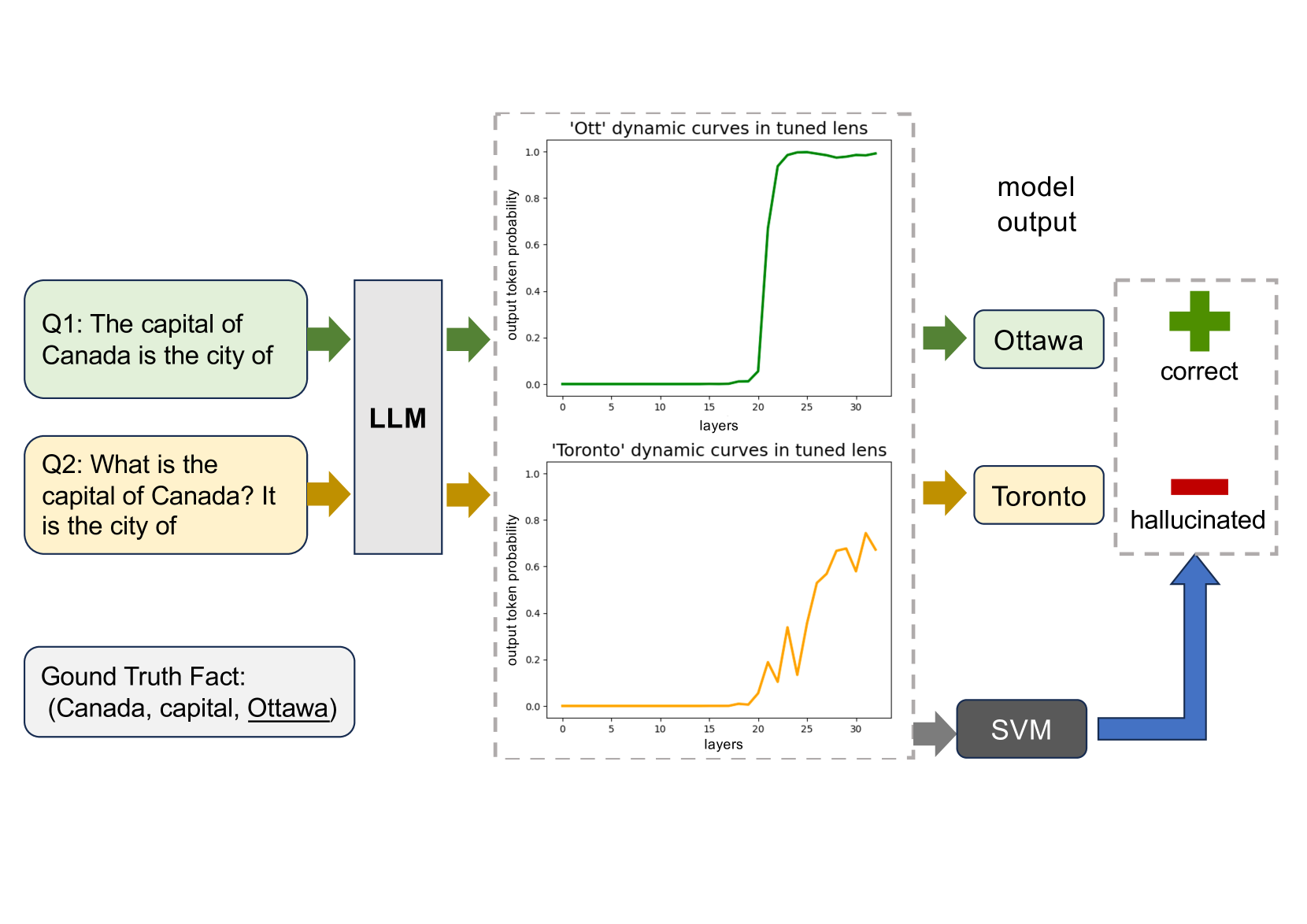
Large language models are successful in answering factoid questions but are also prone to hallucination.We investigate the phenomenon of LLMs possessing correct answer knowledge yet still hallucinating from the perspective of inference dynamics, an area not previously covered in studies on hallucinations.We are able to conduct this analysis via two key ideas.First, we identify the factual questions that query the same triplet knowledge but result in different answers. The difference between the model behaviors on the correct and incorrect outputs hence suggests the patterns when hallucinations happen. Second, to measure the pattern, we utilize mappings from the residual streams to vocabulary space. We reveal the different dynamics of the output token probabilities along the depths of layers between the correct and hallucinated cases. In hallucinated cases, the output token's information rarely demonstrates abrupt increases and consistent superiority in the later stages of the model. Leveraging the dynamic curve as a feature, we build a classifier capable of accurately detecting hallucinatory predictions with an 88% success rate. Our study shed light on understanding the reasons for LLMs' hallucinations on their known facts, and more importantly, on accurately predicting when they are hallucinating.
4/1/2024
💬
Hallucination of Multimodal Large Language Models: A Survey
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, Mike Zheng Shou
0
0
This survey presents a comprehensive analysis of the phenomenon of hallucination in multimodal large language models (MLLMs), also known as Large Vision-Language Models (LVLMs), which have demonstrated significant advancements and remarkable abilities in multimodal tasks. Despite these promising developments, MLLMs often generate outputs that are inconsistent with the visual content, a challenge known as hallucination, which poses substantial obstacles to their practical deployment and raises concerns regarding their reliability in real-world applications. This problem has attracted increasing attention, prompting efforts to detect and mitigate such inaccuracies. We review recent advances in identifying, evaluating, and mitigating these hallucinations, offering a detailed overview of the underlying causes, evaluation benchmarks, metrics, and strategies developed to address this issue. Additionally, we analyze the current challenges and limitations, formulating open questions that delineate potential pathways for future research. By drawing the granular classification and landscapes of hallucination causes, evaluation benchmarks, and mitigation methods, this survey aims to deepen the understanding of hallucinations in MLLMs and inspire further advancements in the field. Through our thorough and in-depth review, we contribute to the ongoing dialogue on enhancing the robustness and reliability of MLLMs, providing valuable insights and resources for researchers and practitioners alike. Resources are available at: https://github.com/showlab/Awesome-MLLM-Hallucination.
4/30/2024

Don't Believe Everything You Read: Enhancing Summarization Interpretability through Automatic Identification of Hallucinations in Large Language Models
Priyesh Vakharia, Devavrat Joshi, Meenal Chavan, Dhananjay Sonawane, Bhrigu Garg, Parsa Mazaheri
0
0
Large Language Models (LLMs) are adept at text manipulation -- tasks such as machine translation and text summarization. However, these models can also be prone to hallucination, which can be detrimental to the faithfulness of any answers that the model provides. Recent works in combating hallucinations in LLMs deal with identifying hallucinated sentences and categorizing the different ways in which models hallucinate. This paper takes a deep dive into LLM behavior with respect to hallucinations, defines a token-level approach to identifying different kinds of hallucinations, and further utilizes this token-level tagging to improve the interpretability and faithfulness of LLMs in dialogue summarization tasks. Through this, the paper presents a new, enhanced dataset and a new training paradigm.
4/4/2024