Checkpoint and Restart: An Energy Consumption Characterization in Clusters

0

Sign in to get full access
Overview
- Examines the energy consumption characteristics of checkpoint and restart mechanisms in cluster environments
- Evaluates the impact of various factors on energy consumption, including checkpoint frequency, checkpoint size, and execution time
- Provides insights to help optimize checkpoint and restart strategies for improved energy efficiency
Plain English Explanation
This research paper investigates the energy consumption associated with checkpoint and restart mechanisms in cluster computing environments. Checkpoint and restart is a technique used to save the state of a running program at regular intervals, allowing it to be resumed from the last checkpoint in case of a failure or interruption.
The researchers examined how different factors, such as the frequency of checkpointing, the size of the checkpoint data, and the overall execution time, impact the energy consumption of this process. By understanding these relationships, the researchers aim to provide insights that can help optimize checkpoint and restart strategies for improved energy efficiency in cluster computing.
Technical Explanation
The study was conducted in a cluster environment, where the researchers measured the energy consumption of the checkpoint and restart process under various conditions. They varied the checkpoint frequency, the size of the checkpoint data, and the execution time of the programs, and then analyzed the resulting energy consumption patterns.
The researchers used a combination of hardware and software tools to monitor and measure the energy consumption data. They collected detailed information on the power usage, CPU utilization, and other relevant metrics during the execution of the programs with different checkpoint and restart configurations.
The findings from this research provide valuable insights into the tradeoffs and considerations involved in optimizing checkpoint and restart mechanisms for energy efficiency in cluster computing environments. The researchers identified key factors that influence energy consumption and provided recommendations for adjusting checkpoint and restart strategies to achieve better energy efficiency.
Critical Analysis
The research paper provides a comprehensive analysis of the energy consumption characteristics of checkpoint and restart mechanisms in cluster environments. However, the study is limited to a specific set of experimental conditions and may not fully capture the complexities of real-world cluster deployments.
While the researchers have identified several important factors that influence energy consumption, there may be other variables, such as network bandwidth, storage performance, or system workload, that could also impact the energy efficiency of checkpoint and restart operations. Further research may be needed to explore these additional factors and their interactions.
Additionally, the paper does not delve into the potential trade-offs between energy efficiency and other performance metrics, such as checkpoint overhead, response time, or throughput. A more holistic assessment of the impact of checkpoint and restart strategies on the overall system performance and efficiency would be valuable for practitioners and researchers in the field.
Conclusion
This research paper offers a detailed examination of the energy consumption characteristics of checkpoint and restart mechanisms in cluster computing environments. The findings provide valuable insights that can help system administrators and application developers optimize their checkpoint and restart strategies for improved energy efficiency.
By understanding the relationship between factors such as checkpoint frequency, checkpoint size, and execution time, and their impact on energy consumption, researchers and practitioners can make informed decisions to balance performance, reliability, and energy efficiency in their cluster computing systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Checkpoint and Restart: An Energy Consumption Characterization in Clusters
Marina Moran, Javier Balladini, Dolores Rexachs, Emilio Luque
The fault tolerance method currently used in High Performance Computing (HPC) is the rollback-recovery method by using checkpoints. This, like any other fault tolerance method, adds an additional energy consumption to that of the execution of the application. The objective of this work is to determine the factors that affect the energy consumption of the computing nodes on homogeneous cluster, when performing checkpoint and restart operations, on SPMD (Single Program Multiple Data) applications. We have focused on the energetic study of compute nodes, contemplating different configurations of hardware and software parameters. We studied the effect of performance states (states P) and power states (states C) of processors, application problem size, checkpoint software (DMTCP) and distributed file system (NFS) configuration. The results analysis allowed to identify opportunities to reduce the energy consumption of checkpoint and restart operations.
Read more9/5/2024

0
Optimizing Checkpoint-Restart Mechanisms for HPC with DMTCP in Containers at NERSC
Madan Timalsina, Lisa Gerhardt, Nicholas Tyler, Johannes P. Blaschke, William Arndt
This paper presents an in-depth examination of checkpoint-restart mechanisms in High-Performance Computing (HPC). It focuses on the use of Distributed MultiThreaded CheckPointing (DMTCP) in various computational settings, including both within and outside of containers. The study is grounded in real-world applications running on NERSC Perlmutter, a state-of-the-art supercomputing system. We discuss the advantages of checkpoint-restart (C/R) in managing complex and lengthy computations in HPC, highlighting its efficiency and reliability in such environments. The role of DMTCP in enhancing these workflows, especially in multi-threaded and distributed applications, is thoroughly explored. Additionally, the paper delves into the use of HPC containers, such as Shifter and Podman-HPC, which aid in the management of computational tasks, ensuring uniform performance across different environments. The methods, results, and potential future directions of this research, including its application in various scientific domains, are also covered, showcasing the critical advancements made in computational methodologies through this study.
Read more7/30/2024

0
A Comprehensive Analysis of Process Energy Consumption on Multi-Socket Systems with GPUs
Luis G. Le'on-Vega, Niccol`o Tosato, Stefano Cozzini
Robustly estimating energy consumption in High-Performance Computing (HPC) is essential for assessing the energy footprint of modern workloads, particularly in fields such as Artificial Intelligence (AI) research, development, and deployment. The extensive use of supercomputers for AI training has heightened concerns about energy consumption and carbon emissions. Existing energy estimation tools often assume exclusive use of computing nodes, a premise that becomes problematic with the advent of supercomputers integrating microservices, as seen in initiatives like Acceleration as a Service (XaaS) and cloud computing. This work investigates the impact of executed instructions on overall power consumption, providing insights into the comprehensive behaviour of HPC systems. We introduce two novel mathematical models to estimate a process's energy consumption based on the total node energy, process usage, and a normalised vector of the probability distribution of instruction types for CPU and GPU processes. Our approach enables energy accounting for specific processes without the need for isolation. Our models demonstrate high accuracy, predicting CPU power consumption with a mere 1.9% error. For GPU predictions, the models achieve a central relative error of 9.7%, showing a clear tendency to fit the test data accurately. These results pave the way for new tools to measure and account for energy consumption in shared supercomputing environments.
Read more9/10/2024
0
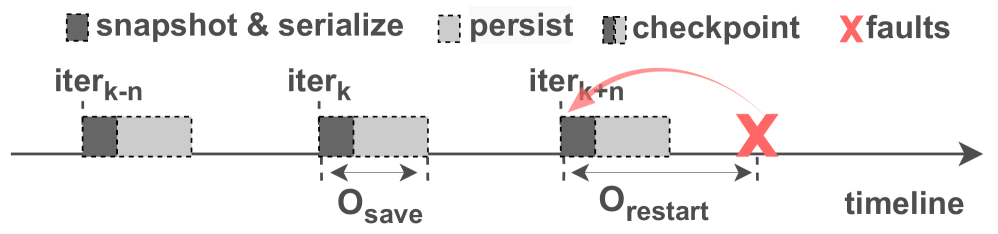
Towards Fault-Tolerant Hybrid-Parallel Training at Scale with Reliable and Efficient In-memory Checkpointing
Yuxin Wang, Xueze Kang, Shaohuai Shi, Xin He, Zhenheng Tang, Xinglin Pan, Yang Zheng, Xiaoyu Wu, Amelie Chi Zhou, Bingsheng He, Xiaowen Chu
To efficiently scale large model (LM) training, researchers transition from data parallelism (DP) to hybrid parallelism (HP) on GPU clusters, which frequently experience hardware and software failures. Existing works introduce in-memory checkpointing optimizations that snapshot parameters to device memory for rapid failure recovery. However, these methods introduce severe resource competition between checkpointing and training, which can work under DP but can hardly scale under resource-intensive HP. To ensure low checkpointing overhead for hybrid-parallel training, this paper introduces a distributed in-memory checkpointing system with near-zero in-memory saving overhead. It strives from two aspects to mitigate the on-host resource competition caused by in-memory checkpointing: (1) It introduces Hierarchical Asynchronous Snapshotting Coordination in the checkpoint saving stage. This approach uses three-level asynchronous on-device scheduling to enhance parallelism between snapshotting and training, thereby minimizing snapshotting overhead. (2) It proposes Hybrid In-memory Checkpoint Protection to enhance checkpoint completeness during hardware failures. Unlike methods that require inter-node communications, which may block training under HP, it creates intra-node redundancy with efficient resource utilization, protecting training against hardware failures with minimal overhead. With these methods, this work enables fast restart for failed HP training with Distributed In-memory Checkpoint Loading, bypassing inefficiencies in NFS reads. In our evaluation, we achieve zero in-memory checkpoint saving overhead on Frontier while training Llama-2-34B on 256 MI250X devices (512 GPUs).
Read more8/20/2024