Optimizing Checkpoint-Restart Mechanisms for HPC with DMTCP in Containers at NERSC

0

Sign in to get full access
Overview
- This paper explores techniques for optimizing checkpoint-restart mechanisms in high-performance computing (HPC) environments, using the Distributed MultiThreaded CheckPointing (DMTCP) tool and containers.
- The research was conducted at the National Energy Research Scientific Computing Center (NERSC), a leading HPC facility.
- The study aims to understand the performance and scalability of checkpoint-restart using DMTCP within containerized HPC applications.
Plain English Explanation
When running large, complex simulations or calculations on powerful computers, it's important to have a way to "save the progress" in case the system crashes or needs to be restarted. This is called "checkpoint-restart," and it's a crucial feature for high-performance computing (HPC) systems.
The researchers in this study looked at ways to optimize the checkpoint-restart process using a tool called DMTCP (Distributed MultiThreaded CheckPointing). DMTCP allows you to pause a running program, save its state, and then resume it later from that saved point. The researchers tested DMTCP inside specialized software containers, which are like self-contained virtual environments that can run on different computer systems.
By using DMTCP and containers together, the researchers hoped to find a more efficient and scalable way to handle checkpoint-restart for HPC applications. This is important because as HPC systems get larger and more complex, the checkpoint-restart process can become a bottleneck that slows down the overall computation.
Technical Explanation
The researchers evaluated the performance and scalability of DMTCP-based checkpoint-restart within Shifter and Podman-HPC containers running on the NERSC HPC platform. They measured the overhead of the checkpoint-restart process, as well as the impact on application performance.
The key findings include:
- DMTCP was able to successfully checkpoint and restart HPC applications running in both Shifter and Podman-HPC containers.
- The checkpoint-restart overhead was relatively low, ranging from 2-4% for smaller test cases to 7-10% for larger, more complex applications.
- DMTCP demonstrated good scalability, handling checkpoint-restart for applications running on up to 1,024 CPU cores without significant performance degradation.
The researchers also identified some limitations and areas for future work, such as exploring techniques to further reduce the checkpoint-restart overhead and integrating DMTCP more seamlessly with container runtime environments.
Critical Analysis
The research provides a promising approach for optimizing checkpoint-restart mechanisms in HPC environments using DMTCP and containers. The low overhead and good scalability demonstrated by DMTCP are encouraging, as they suggest this technique could be viable for real-world HPC applications.
However, the paper does not explore the impact of DMTCP on the overall energy consumption or resource utilization of the HPC system, which could be an important consideration for large-scale deployments. Additionally, the researchers only tested a limited set of applications, and further validation with a broader range of HPC workloads would be helpful to better understand the generalizability of the findings.
Future research could also investigate ways to further integrate DMTCP with container runtimes, potentially automating the checkpoint-restart process and making it more transparent to the end user. Exploring the use of DMTCP in hybrid HPC environments that combine traditional supercomputers with cloud-based resources could also be a valuable area of study.
Conclusion
This research demonstrates the potential of using DMTCP and containers to optimize checkpoint-restart mechanisms for HPC applications. The low overhead and good scalability observed suggest that this approach could be a practical solution for improving the resilience and fault tolerance of large-scale HPC systems. As HPC continues to grow in complexity, techniques like this will be increasingly important for ensuring the efficient and reliable execution of critical scientific and engineering simulations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Optimizing Checkpoint-Restart Mechanisms for HPC with DMTCP in Containers at NERSC
Madan Timalsina, Lisa Gerhardt, Nicholas Tyler, Johannes P. Blaschke, William Arndt
This paper presents an in-depth examination of checkpoint-restart mechanisms in High-Performance Computing (HPC). It focuses on the use of Distributed MultiThreaded CheckPointing (DMTCP) in various computational settings, including both within and outside of containers. The study is grounded in real-world applications running on NERSC Perlmutter, a state-of-the-art supercomputing system. We discuss the advantages of checkpoint-restart (C/R) in managing complex and lengthy computations in HPC, highlighting its efficiency and reliability in such environments. The role of DMTCP in enhancing these workflows, especially in multi-threaded and distributed applications, is thoroughly explored. Additionally, the paper delves into the use of HPC containers, such as Shifter and Podman-HPC, which aid in the management of computational tasks, ensuring uniform performance across different environments. The methods, results, and potential future directions of this research, including its application in various scientific domains, are also covered, showcasing the critical advancements made in computational methodologies through this study.
Read more7/30/2024

0
Checkpoint and Restart: An Energy Consumption Characterization in Clusters
Marina Moran, Javier Balladini, Dolores Rexachs, Emilio Luque
The fault tolerance method currently used in High Performance Computing (HPC) is the rollback-recovery method by using checkpoints. This, like any other fault tolerance method, adds an additional energy consumption to that of the execution of the application. The objective of this work is to determine the factors that affect the energy consumption of the computing nodes on homogeneous cluster, when performing checkpoint and restart operations, on SPMD (Single Program Multiple Data) applications. We have focused on the energetic study of compute nodes, contemplating different configurations of hardware and software parameters. We studied the effect of performance states (states P) and power states (states C) of processors, application problem size, checkpoint software (DMTCP) and distributed file system (NFS) configuration. The results analysis allowed to identify opportunities to reduce the energy consumption of checkpoint and restart operations.
Read more9/5/2024
0
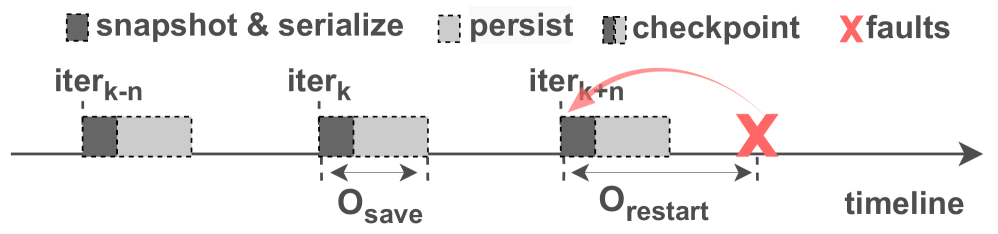
Towards Fault-Tolerant Hybrid-Parallel Training at Scale with Reliable and Efficient In-memory Checkpointing
Yuxin Wang, Xueze Kang, Shaohuai Shi, Xin He, Zhenheng Tang, Xinglin Pan, Yang Zheng, Xiaoyu Wu, Amelie Chi Zhou, Bingsheng He, Xiaowen Chu
To efficiently scale large model (LM) training, researchers transition from data parallelism (DP) to hybrid parallelism (HP) on GPU clusters, which frequently experience hardware and software failures. Existing works introduce in-memory checkpointing optimizations that snapshot parameters to device memory for rapid failure recovery. However, these methods introduce severe resource competition between checkpointing and training, which can work under DP but can hardly scale under resource-intensive HP. To ensure low checkpointing overhead for hybrid-parallel training, this paper introduces a distributed in-memory checkpointing system with near-zero in-memory saving overhead. It strives from two aspects to mitigate the on-host resource competition caused by in-memory checkpointing: (1) It introduces Hierarchical Asynchronous Snapshotting Coordination in the checkpoint saving stage. This approach uses three-level asynchronous on-device scheduling to enhance parallelism between snapshotting and training, thereby minimizing snapshotting overhead. (2) It proposes Hybrid In-memory Checkpoint Protection to enhance checkpoint completeness during hardware failures. Unlike methods that require inter-node communications, which may block training under HP, it creates intra-node redundancy with efficient resource utilization, protecting training against hardware failures with minimal overhead. With these methods, this work enables fast restart for failed HP training with Distributed In-memory Checkpoint Loading, bypassing inefficiencies in NFS reads. In our evaluation, we achieve zero in-memory checkpoint saving overhead on Frontier while training Llama-2-34B on 256 MI250X devices (512 GPUs).
Read more8/20/2024
0
Understanding Layered Portability from HPC to Cloud in Containerized Environments
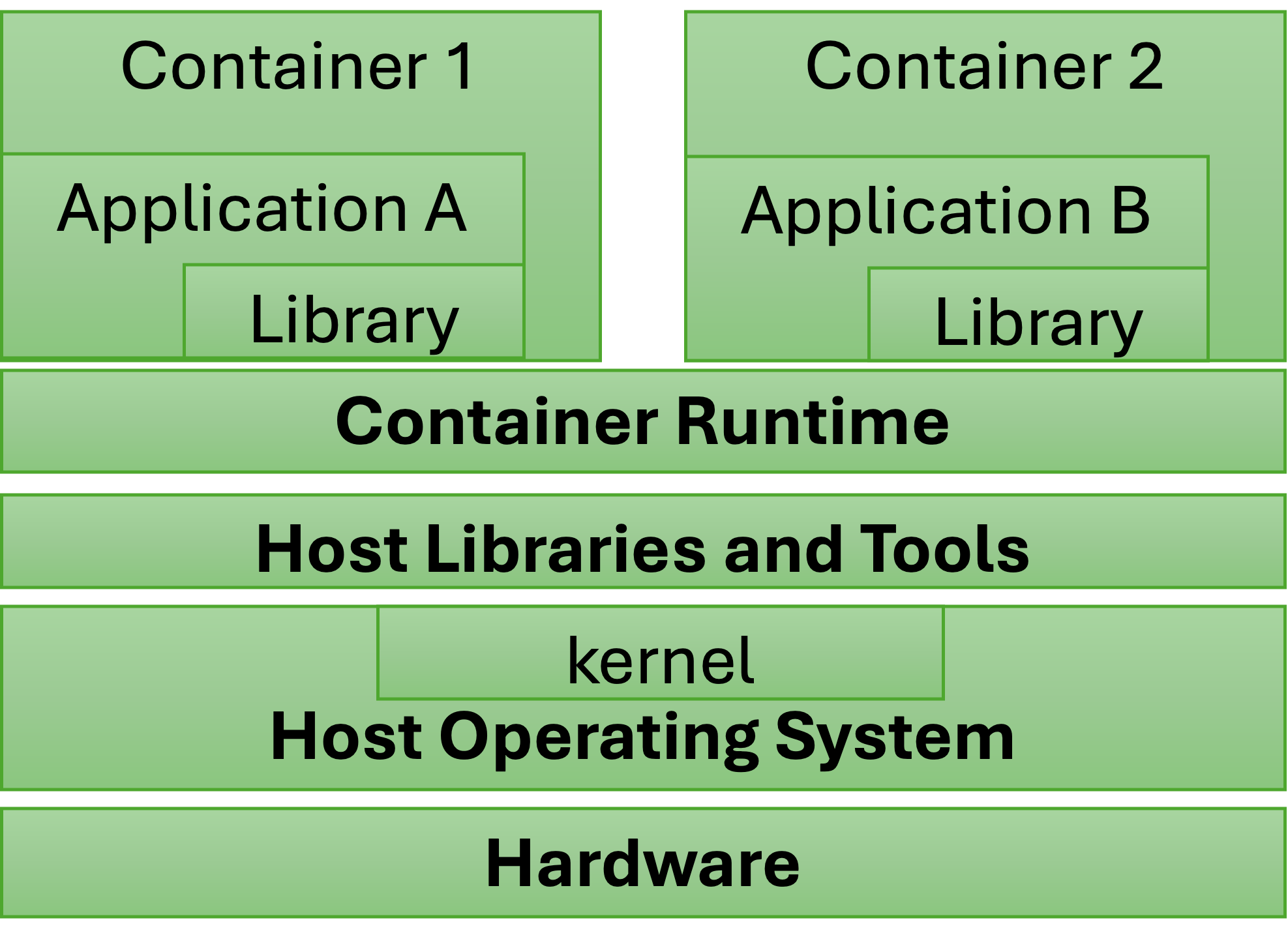
Daniel Medeiros, Gabin Schieffer, Jacob Wahlgren, Ivy Peng
Recent development in lightweight OS-level virtualization, containers, provides a potential solution for running HPC applications on the cloud platform. In this work, we focus on the impact of different layers in a containerized environment when migrating HPC containers from a dedicated HPC system to a cloud platform. On three ARM-based platforms, including the latest Nvidia Grace CPU, we use six representative HPC applications to characterize the impact of container virtualization, host OS and kernel, and rootless and privileged container execution. Our results indicate less than 4% container overhead in DGEMM, miniMD, and XSBench, but 8%-10% overhead in FFT, HPCG, and Hypre. We also show that changing between the container execution modes results in negligible performance differences in the six applications.
Read more6/18/2024