Chinese Metaphor Recognition Using a Multi-stage Prompting Large Language Model

0

Sign in to get full access
Overview
- A new approach for Chinese metaphor recognition using a multi-stage prompting large language model.
- Leverages the reasoning and language understanding capabilities of large language models to tackle the complex problem of metaphor detection.
- Demonstrates improved performance compared to existing methods on a Chinese metaphor dataset.
Plain English Explanation
Metaphors are a fundamental part of human language, allowing us to express complex ideas in creative ways. However, detecting metaphors in text can be a challenging task, even for humans. This paper explores using large language models, which are powerful AI systems trained on vast amounts of text data, to recognize metaphors in Chinese.
The key insight is that these large language models can learn rules and patterns that allow them to understand the nuanced usage of language, including metaphors. The researchers developed a multi-stage prompting approach, where the language model is first primed with example metaphors, then tasked with identifying metaphors in new text.
By leveraging the capabilities of large language models in this way, the system is able to outperform existing metaphor detection methods on a Chinese dataset. This suggests that prompt engineering techniques can be a powerful tool for extracting task-specific knowledge from these large AI models.
Technical Explanation
The paper presents a novel approach for Chinese metaphor recognition using a multi-stage prompting technique with a large language model. The key steps are:
-
Pretraining: The researchers start with a large pretrained language model, DeBERTa, which has been trained on a massive amount of Chinese text data.
-
Metaphor Prompt Stage: They then fine-tune the model by presenting it with a series of metaphor examples, along with their corresponding literal meanings. This helps the model learn to recognize the patterns and structure of metaphorical language.
-
Metaphor Detection Stage: Finally, the model is prompted with new Chinese sentences and asked to identify whether each sentence contains a metaphor or not. This multi-stage prompting approach allows the model to leverage its understanding of metaphors to accurately detect them in novel text.
The performance of this approach is evaluated on the CMEKG Chinese metaphor dataset. The results show that the multi-stage prompting model outperforms previous state-of-the-art methods for Chinese metaphor recognition.
Critical Analysis
One of the key strengths of this approach is its ability to leverage the powerful language understanding capabilities of large pretrained models without requiring a large labeled dataset for training. By using a multi-stage prompting technique, the researchers are able to fine-tune the model's metaphor recognition abilities with a relatively small number of examples.
However, the paper does not discuss the potential limitations or biases that may be present in the pretrained DeBERTa model, which could impact the model's performance on metaphor detection. Additionally, the researchers only evaluate the approach on a single Chinese metaphor dataset, so it's unclear how well it would generalize to other metaphor-related tasks or datasets.
Further research could explore applying this multi-stage prompting technique to other languages or domains, as well as investigating ways to make the approach more robust and generalizable. Additionally, incorporating soft labels and target-aware representations could potentially improve the model's ability to reason about metaphorical language.
Conclusion
This paper presents a novel approach for Chinese metaphor recognition that leverages the power of large language models through a multi-stage prompting technique. By fine-tuning the model's understanding of metaphorical language, the researchers are able to achieve state-of-the-art performance on a Chinese metaphor dataset.
The successful application of this approach suggests that prompt engineering techniques can be a valuable tool for extracting task-specific knowledge from large language models, opening up new possibilities for tackling complex language-related tasks. As large language models continue to advance, we can expect to see more innovative applications of these techniques across a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Chinese Metaphor Recognition Using a Multi-stage Prompting Large Language Model
Jie Wang, Jin Wang, Xuejie Zhang
Metaphors are common in everyday language, and the identification and understanding of metaphors are facilitated by models to achieve a better understanding of the text. Metaphors are mainly identified and generated by pre-trained models in existing research, but situations, where tenors or vehicles are not included in the metaphor, cannot be handled. The problem can be effectively solved by using Large Language Models (LLMs), but significant room for exploration remains in this early-stage research area. A multi-stage generative heuristic-enhanced prompt framework is proposed in this study to enhance the ability of LLMs to recognize tenors, vehicles, and grounds in Chinese metaphors. In the first stage, a small model is trained to obtain the required confidence score for answer candidate generation. In the second stage, questions are clustered and sampled according to specific rules. Finally, the heuristic-enhanced prompt needed is formed by combining the generated answer candidates and demonstrations. The proposed model achieved 3rd place in Track 1 of Subtask 1, 1st place in Track 2 of Subtask 1, and 1st place in both tracks of Subtask 2 at the NLPCC-2024 Shared Task 9.
Read more8/20/2024

0
Enhancing Metaphor Detection through Soft Labels and Target Word Prediction
Kaidi Jia, Rongsheng Li
Metaphors play a significant role in our everyday communication, yet detecting them presents a challenge. Traditional methods often struggle with improper application of language rules and a tendency to overlook data sparsity. To address these issues, we integrate knowledge distillation and prompt learning into metaphor detection. Our approach revolves around a tailored prompt learning framework specifically designed for metaphor detection. By strategically masking target words and providing relevant prompt data, we guide the model to accurately predict the contextual meanings of these words. This approach not only mitigates confusion stemming from the literal meanings of the words but also ensures effective application of language rules for metaphor detection. Furthermore, we've introduced a teacher model to generate valuable soft labels. These soft labels provide a similar effect to label smoothing and help prevent the model from becoming over confident and effectively addresses the challenge of data sparsity. Experimental results demonstrate that our model has achieved state-of-the-art performance, as evidenced by its remarkable results across various datasets.
Read more4/10/2024
💬
0
New!Large Language Models are Good Multi-lingual Learners : When LLMs Meet Cross-lingual Prompts
Teng Wang, Zhenqi He, Wing-Yin Yu, Xiaojin Fu, Xiongwei Han
With the advent of Large Language Models (LLMs), generating rule-based data for real-world applications has become more accessible. Due to the inherent ambiguity of natural language and the complexity of rule sets, especially in long contexts, LLMs often struggle to follow all specified rules, frequently omitting at least one. To enhance the reasoning and understanding of LLMs on long and complex contexts, we propose a novel prompting strategy Multi-Lingual Prompt, namely MLPrompt, which automatically translates the error-prone rule that an LLM struggles to follow into another language, thus drawing greater attention to it. Experimental results on public datasets across various tasks have shown MLPrompt can outperform state-of-the-art prompting methods such as Chain of Thought, Tree of Thought, and Self-Consistency. Additionally, we introduce a framework integrating MLPrompt with an auto-checking mechanism for structured data generation, with a specific case study in text-to-MIP instances. Further, we extend the proposed framework for text-to-SQL to demonstrate its generation ability towards structured data synthesis.
Read more9/18/2024
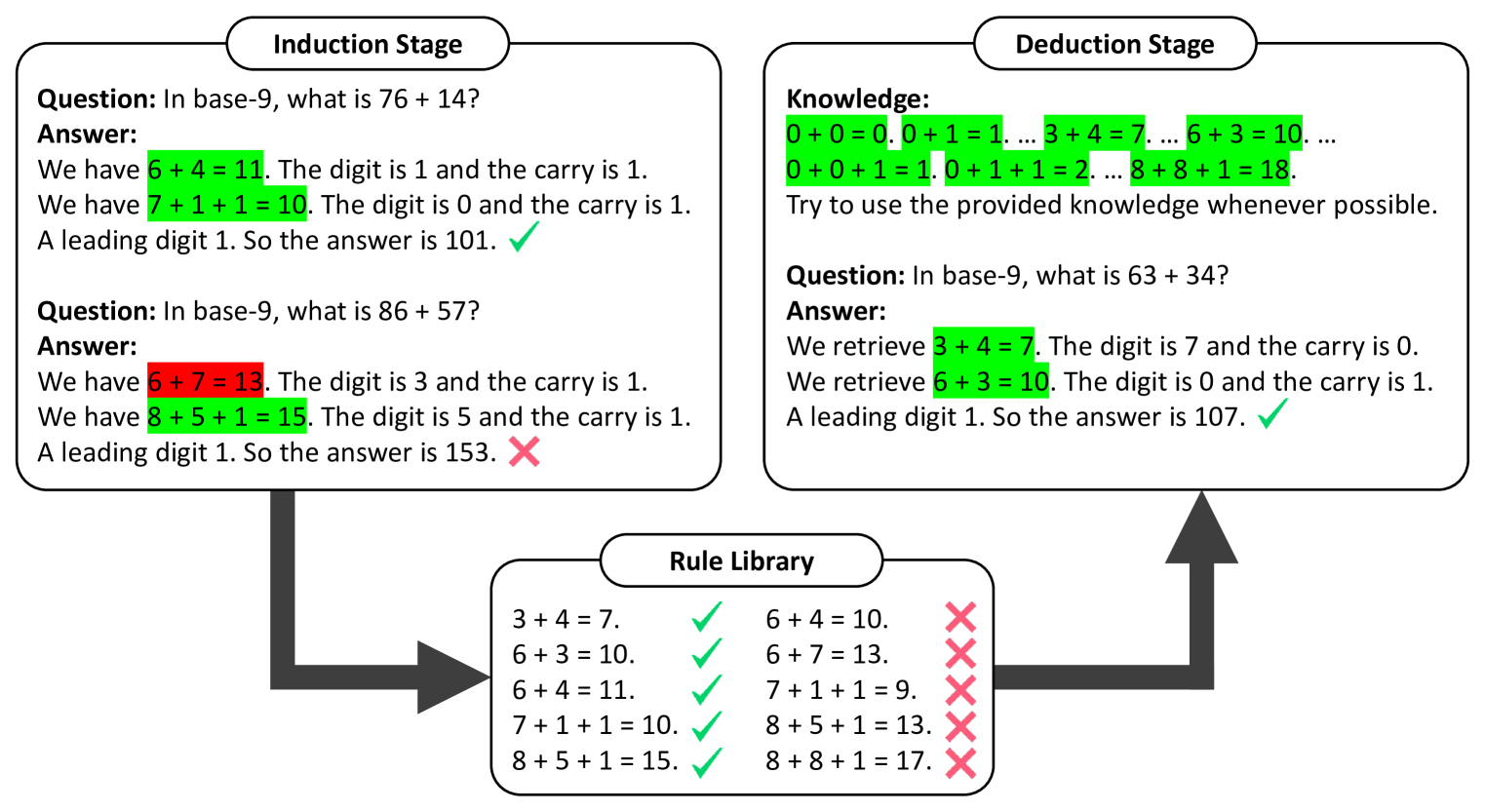
0
Large Language Models can Learn Rules
Zhaocheng Zhu, Yuan Xue, Xinyun Chen, Denny Zhou, Jian Tang, Dale Schuurmans, Hanjun Dai
When prompted with a few examples and intermediate steps, large language models (LLMs) have demonstrated impressive performance in various reasoning tasks. However, prompting methods that rely on implicit knowledge in an LLM often generate incorrect answers when the implicit knowledge is wrong or inconsistent with the task. To tackle this problem, we present Hypotheses-to-Theories (HtT), a framework that learns a rule library for reasoning with LLMs. HtT contains two stages, an induction stage and a deduction stage. In the induction stage, an LLM is first asked to generate and verify rules over a set of training examples. Rules that appear and lead to correct answers sufficiently often are collected to form a rule library. In the deduction stage, the LLM is then prompted to employ the learned rule library to perform reasoning to answer test questions. Experiments on relational reasoning, numerical reasoning and concept learning problems show that HtT improves existing prompting methods, with an absolute gain of 10-30% in accuracy. The learned rules are also transferable to different models and to different forms of the same problem.
Read more4/26/2024