Large Language Models can Learn Rules
2310.07064
1
0
Abstract
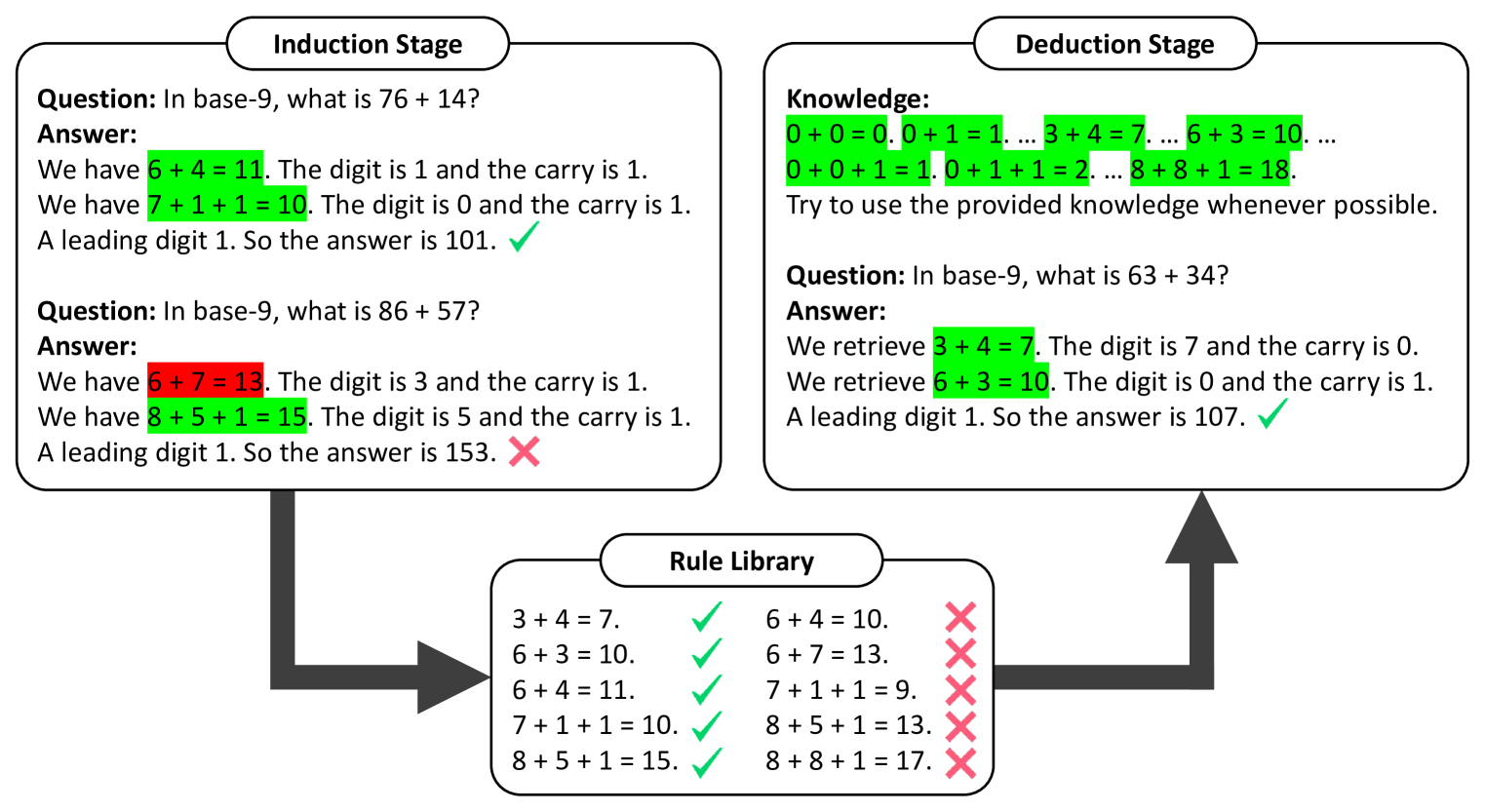
When prompted with a few examples and intermediate steps, large language models (LLMs) have demonstrated impressive performance in various reasoning tasks. However, prompting methods that rely on implicit knowledge in an LLM often generate incorrect answers when the implicit knowledge is wrong or inconsistent with the task. To tackle this problem, we present Hypotheses-to-Theories (HtT), a framework that learns a rule library for reasoning with LLMs. HtT contains two stages, an induction stage and a deduction stage. In the induction stage, an LLM is first asked to generate and verify rules over a set of training examples. Rules that appear and lead to correct answers sufficiently often are collected to form a rule library. In the deduction stage, the LLM is then prompted to employ the learned rule library to perform reasoning to answer test questions. Experiments on relational reasoning, numerical reasoning and concept learning problems show that HtT improves existing prompting methods, with an absolute gain of 10-30% in accuracy. The learned rules are also transferable to different models and to different forms of the same problem.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper investigates whether large language models (LLMs) can learn and apply rules through a novel "hypotheses-to-theories" prompting approach.
- The researchers explore how LLMs can generate hypotheses, verify them, and then construct general theories or rules.
- The findings suggest that LLMs can indeed learn rules, with potential applications in areas like automated reasoning and commonsense understanding.
Plain English Explanation
Large language models (LLMs) are powerful artificial intelligence systems that can understand and generate human-like text. This paper explores whether these LLMs can also learn and apply rules, going beyond just generating text.
The researchers used a novel "hypotheses-to-theories" prompting approach, where they asked the LLM to:
- Generate hypotheses about a given scenario or problem
- Verify those hypotheses by testing them against additional information
- Construct general theories or rules based on the verified hypotheses
For example, the LLM might be asked to come up with hypotheses about how the weather affects plant growth, test those hypotheses, and then formulate a general rule or theory about the relationship between weather and plant growth.
The results show that LLMs can indeed learn and apply rules in this way. This is an important finding because it suggests that these powerful AI systems can go beyond just generating text and can actually reason about the world and learn general principles.
This could have many applications, such as:
- Automated reasoning and problem-solving
- Commonsense understanding of the world
- Assisting humans in tasks that require rule-based reasoning
Of course, there are still limitations and areas for further research, but this paper demonstrates an exciting new capability of large language models.
Technical Explanation
The paper presents a novel "hypotheses-to-theories" prompting approach to investigate whether large language models (LLMs) can learn and apply rules. The researchers designed a multi-stage process where the LLM is first asked to generate hypotheses about a given scenario or problem, then verify those hypotheses by testing them against additional information, and finally construct general theories or rules based on the verified hypotheses.
The experiments were conducted using the GPT-3 LLM, with the researchers evaluating the LLM's performance on a range of tasks, including commonsense reasoning, temporal reasoning, and deductive competence. The results show that the LLM was able to successfully learn and apply rules through this prompting approach, demonstrating its ability to engage in inductive, deductive, and abductive reasoning.
The key insights from the paper include:
- LLMs can generate hypotheses, test them, and construct general theories or rules, going beyond just text generation.
- This rule-learning capability has potential applications in areas like automated reasoning, commonsense understanding, and human-AI collaboration.
- The researchers provide a framework for probing the reasoning abilities of LLMs, which can inform future model development and evaluation.
Critical Analysis
The paper presents a promising approach for enabling LLMs to learn and apply rules, but it also highlights some limitations and areas for further research:
- The experiments were conducted on a limited set of tasks, and it's unclear how well the approach would scale to more complex or open-ended problems.
- The paper does not address potential biases or inconsistencies that may arise in the LLM's rule-learning process, which could be an important consideration for real-world applications.
- The researchers acknowledge that the LLM's performance may be influenced by the specific prompting and task design, and further investigation is needed to understand the generalizability of the findings.
Additionally, while the paper demonstrates the LLM's ability to learn rules, it does not explore the interpretability or explainability of the rules learned. This could be an important factor in understanding the reasoning behind the LLM's outputs and ensuring its reliability and trustworthiness.
Overall, this paper represents an important step forward in understanding the reasoning capabilities of large language models, but more research is needed to fully realize the potential of this approach and address its limitations.
Conclusion
This paper presents a novel "hypotheses-to-theories" prompting approach that enables large language models (LLMs) to learn and apply rules, going beyond just text generation. The findings suggest that LLMs can engage in inductive, deductive, and abductive reasoning to generate hypotheses, verify them, and construct general theories or rules.
The ability of LLMs to learn rules has significant implications, as it opens up new possibilities for automated reasoning, commonsense understanding, and human-AI collaboration. While the paper highlights some limitations and areas for further research, it represents an important advancement in our understanding of the reasoning capabilities of these powerful AI systems.
As the field of large language models continues to evolve, this research can inform the development of more sophisticated and versatile AI systems that can tackle increasingly complex problems and assist humans in a wide range of tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Hypothesis Generation with Large Language Models
Yangqiaoyu Zhou, Haokun Liu, Tejes Srivastava, Hongyuan Mei, Chenhao Tan
0
0
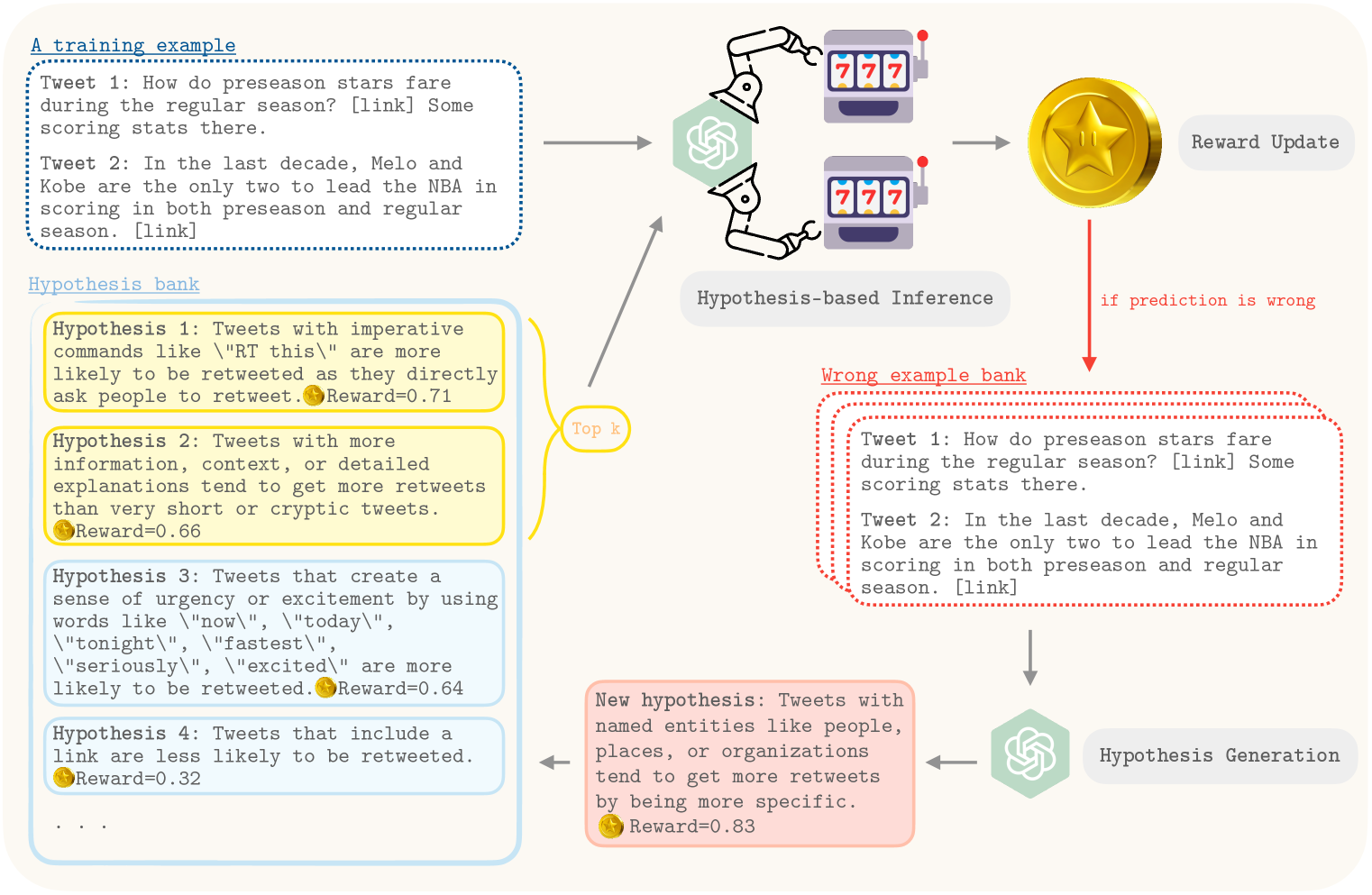
Effective generation of novel hypotheses is instrumental to scientific progress. So far, researchers have been the main powerhouse behind hypothesis generation by painstaking data analysis and thinking (also known as the Eureka moment). In this paper, we examine the potential of large language models (LLMs) to generate hypotheses. We focus on hypothesis generation based on data (i.e., labeled examples). To enable LLMs to handle arbitrarily long contexts, we generate initial hypotheses from a small number of examples and then update them iteratively to improve the quality of hypotheses. Inspired by multi-armed bandits, we design a reward function to inform the exploitation-exploration tradeoff in the update process. Our algorithm is able to generate hypotheses that enable much better predictive performance than few-shot prompting in classification tasks, improving accuracy by 31.7% on a synthetic dataset and by 13.9%, 3.3% and, 24.9% on three real-world datasets. We also outperform supervised learning by 12.8% and 11.2% on two challenging real-world datasets. Furthermore, we find that the generated hypotheses not only corroborate human-verified theories but also uncover new insights for the tasks.
4/9/2024
Can Small Language Models Help Large Language Models Reason Better?: LM-Guided Chain-of-Thought
Jooyoung Lee, Fan Yang, Thanh Tran, Qian Hu, Emre Barut, Kai-Wei Chang, Chengwei Su
0
0
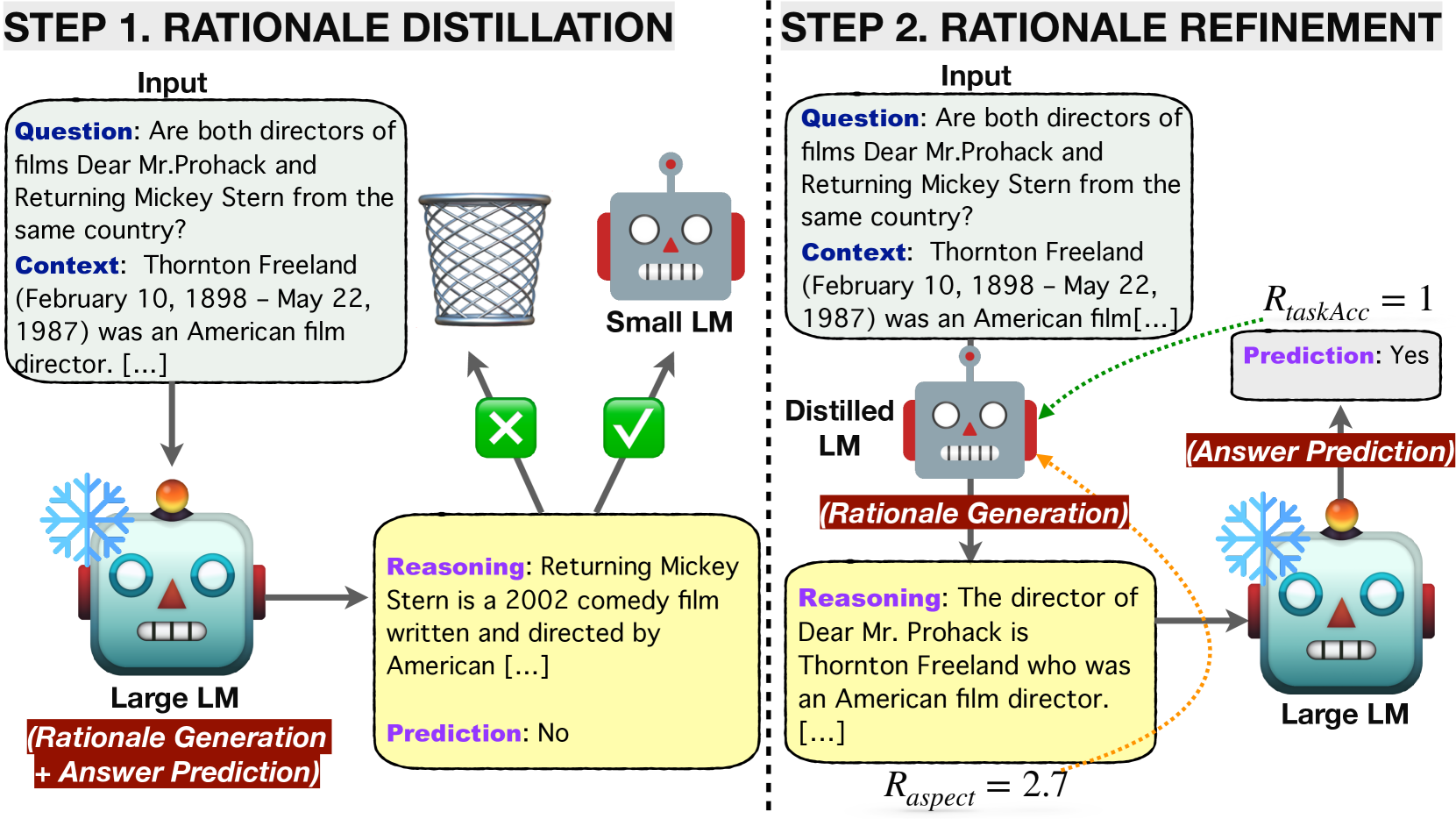
We introduce a novel framework, LM-Guided CoT, that leverages a lightweight (i.e., 10B) LM in reasoning tasks. Specifically, the lightweight LM first generates a rationale for each input instance. The Frozen large LM is then prompted to predict a task output based on the rationale generated by the lightweight LM. Our approach is resource-efficient in the sense that it only requires training the lightweight LM. We optimize the model through 1) knowledge distillation and 2) reinforcement learning from rationale-oriented and task-oriented reward signals. We assess our method with multi-hop extractive question answering (QA) benchmarks, HotpotQA, and 2WikiMultiHopQA. Experimental results show that our approach outperforms all baselines regarding answer prediction accuracy. We also find that reinforcement learning helps the model to produce higher-quality rationales with improved QA performance.
4/5/2024
Large Language Models Can Learn Temporal Reasoning
Siheng Xiong, Ali Payani, Ramana Kompella, Faramarz Fekri
0
0
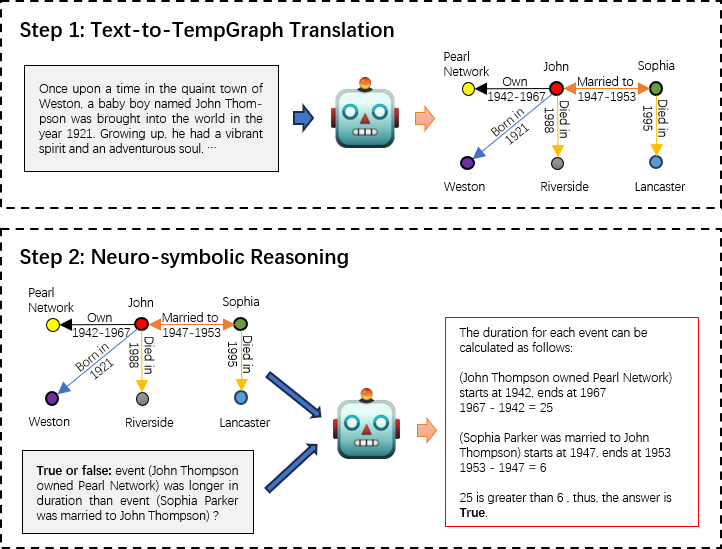
While large language models (LLMs) have demonstrated remarkable reasoning capabilities, they are not without their flaws and inaccuracies. Recent studies have introduced various methods to mitigate these limitations. Temporal reasoning (TR), in particular, presents a significant challenge for LLMs due to its reliance on diverse temporal expressions and intricate temporal logic. In this paper, we propose TG-LLM, a novel framework towards language-based TR. Instead of reasoning over the original context, we adopt a latent representation, temporal graph (TG) that facilitates the TR learning. A synthetic dataset (TGQA), which is fully controllable and requires minimal supervision, is constructed for fine-tuning LLMs on this text-to-TG translation task. We confirmed in experiments that the capability of TG translation learned on our dataset can be transferred to other TR tasks and benchmarks. On top of that, we teach LLM to perform deliberate reasoning over the TGs via Chain of Thought (CoT) bootstrapping and graph data augmentation. We observed that those strategies, which maintain a balance between usefulness and diversity, bring more reliable CoTs and final results than the vanilla CoT distillation.
4/23/2024
💬
Evaluating the Deductive Competence of Large Language Models
Spencer M. Seals, Valerie L. Shalin
0
0
The development of highly fluent large language models (LLMs) has prompted increased interest in assessing their reasoning and problem-solving capabilities. We investigate whether several LLMs can solve a classic type of deductive reasoning problem from the cognitive science literature. The tested LLMs have limited abilities to solve these problems in their conventional form. We performed follow up experiments to investigate if changes to the presentation format and content improve model performance. We do find performance differences between conditions; however, they do not improve overall performance. Moreover, we find that performance interacts with presentation format and content in unexpected ways that differ from human performance. Overall, our results suggest that LLMs have unique reasoning biases that are only partially predicted from human reasoning performance and the human-generated language corpora that informs them.
4/16/2024