Chumor 1.0: A Truly Funny and Challenging Chinese Humor Understanding Dataset from Ruo Zhi Ba

0
Sign in to get full access
Overview
- This paper introduces Chumor 1.0, a new dataset for understanding Chinese humor that is both truly funny and challenging.
- The dataset was created by Ruo Zhi Ba, a Chinese research group, to advance the field of humor AI.
- Chumor 1.0 contains a large number of crowd-sourced Chinese jokes and punchlines, with annotations on their funniness and difficulty.
Plain English Explanation
The researchers behind this paper have created a new dataset called Chumor 1.0 that is designed to help AI systems better understand and generate Chinese humor. Humor is a complex and nuanced form of communication, and it can be especially challenging for machines to grasp the subtleties of humor in different languages and cultural contexts.
To address this, the researchers crowd-sourced a large collection of Chinese jokes and punchlines, and then had people rate how funny and how difficult each one was. This creates a dataset that can be used to train AI models on the characteristics of humor that humans find amusing, as well as the level of complexity involved. By having this kind of detailed information, the hope is that AI systems will be able to better recognize, understand, and even generate humorous content in Chinese.
The creation of Chumor 1.0 builds on efforts in the field of humor AI to create large-scale datasets that can support the development of more advanced humor-understanding capabilities. It also complements work on enhancing language models with slang and multimodal humor datasets to tackle the challenge of humor from multiple angles.
Technical Explanation
The researchers collected over 100,000 Chinese jokes and punchlines from various online sources, including social media, humor websites, and entertainment forums. They then recruited over 5,000 human raters to evaluate each item on two dimensions: funniness and difficulty.
The funniness rating was a score from 1 to 5, where 1 was not funny at all and 5 was extremely funny. The difficulty rating was also a score from 1 to 5, indicating how challenging the joke or punchline was to understand, with 1 being very easy and 5 being very difficult.
This resulting dataset, Chumor 1.0, provides a rich resource for training and evaluating AI systems on Chinese humor understanding. The researchers demonstrate the usefulness of the dataset by training several state-of-the-art language models on the task of predicting the funniness and difficulty scores for new humor examples. The models achieved promising results, showing the potential of Chumor 1.0 to advance the field of humor generation and reasoning.
Critical Analysis
The Chumor 1.0 dataset represents an important step forward in the study of humor from a computational perspective. By providing a large-scale, annotated collection of Chinese jokes and punchlines, the researchers have created a valuable resource for training and evaluating AI systems on this challenging task.
However, it's important to note that humor is inherently subjective and culturally-dependent. While the crowd-sourced ratings provide a useful proxy for humor, there may still be significant individual and cultural differences in perceptions of what is funny. Additionally, the dataset is limited to text-based humor, whereas multimodal humor involving images, videos, or audio may require different approaches.
Further research is needed to better understand the cognitive and linguistic mechanisms underlying humor, as well as the role of cultural context and individual differences. Expanding the Chumor 1.0 dataset to include more diverse forms of humor, as well as exploring cross-cultural comparisons, could be fruitful avenues for future work.
Conclusion
The Chumor 1.0 dataset introduced in this paper represents a significant contribution to the field of humor AI and computational humor understanding. By providing a large-scale, annotated dataset of Chinese jokes and punchlines, the researchers have given researchers and practitioners a valuable tool for training and evaluating AI systems on this challenging task.
The potential applications of this work include more engaging and naturalistic conversational agents, better understanding of human communication and social dynamics, and even the development of AI-powered humor generation and analysis tools. As the field of multimodal sentiment analysis continues to advance, the Chumor 1.0 dataset may also prove useful in understanding the role of humor in human expression and interaction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Chumor 1.0: A Truly Funny and Challenging Chinese Humor Understanding Dataset from Ruo Zhi Ba
Ruiqi He, Yushu He, Longju Bai, Jiarui Liu, Zhenjie Sun, Zenghao Tang, He Wang, Hanchen Xia, Naihao Deng
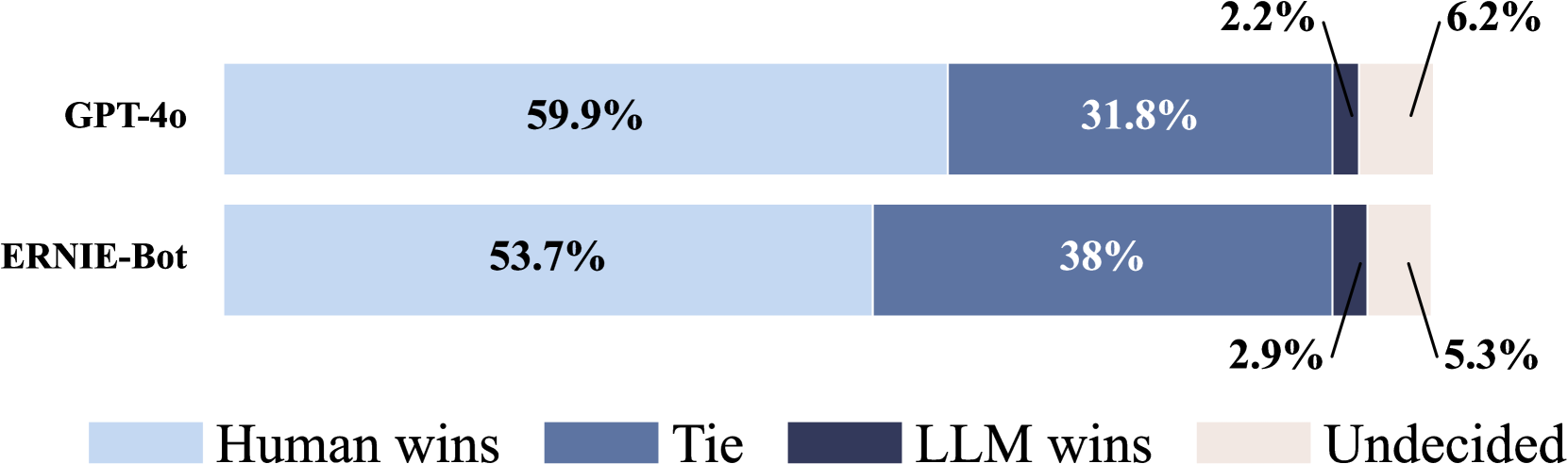
Existing humor datasets and evaluations predominantly focus on English, lacking resources for culturally nuanced humor in non-English languages like Chinese. To address this gap, we construct Chumor, a dataset sourced from Ruo Zhi Ba (RZB), a Chinese Reddit-like platform dedicated to sharing intellectually challenging and culturally specific jokes. We annotate explanations for each joke and evaluate human explanations against two state-of-the-art LLMs, GPT-4o and ERNIE Bot, through A/B testing by native Chinese speakers. Our evaluation shows that Chumor is challenging even for SOTA LLMs, and the human explanations for Chumor jokes are significantly better than explanations generated by the LLMs.
Read more6/19/2024

0
Getting Serious about Humor: Crafting Humor Datasets with Unfunny Large Language Models
Zachary Horvitz, Jingru Chen, Rahul Aditya, Harshvardhan Srivastava, Robert West, Zhou Yu, Kathleen McKeown
Humor is a fundamental facet of human cognition and interaction. Yet, despite recent advances in natural language processing, humor detection remains a challenging task that is complicated by the scarcity of datasets that pair humorous texts with similar non-humorous counterparts. In our work, we investigate whether large language models (LLMs), can generate synthetic data for humor detection via editing texts. We benchmark LLMs on an existing human dataset and show that current LLMs display an impressive ability to 'unfun' jokes, as judged by humans and as measured on the downstream task of humor detection. We extend our approach to a code-mixed English-Hindi humor dataset, where we find that GPT-4's synthetic data is highly rated by bilingual annotators and provides challenging adversarial examples for humor classifiers.
Read more6/24/2024

0
Is AI fun? HumorDB: a curated dataset and benchmark to investigate graphical humor
Veedant Jain, Felipe dos Santos Alves Feitosa, Gabriel Kreiman
Despite significant advancements in computer vision, understanding complex scenes, particularly those involving humor, remains a substantial challenge. This paper introduces HumorDB, a novel image-only dataset specifically designed to advance visual humor understanding. HumorDB consists of meticulously curated image pairs with contrasting humor ratings, emphasizing subtle visual cues that trigger humor and mitigating potential biases. The dataset enables evaluation through binary classification(Funny or Not Funny), range regression(funniness on a scale from 1 to 10), and pairwise comparison tasks(Which Image is Funnier?), effectively capturing the subjective nature of humor perception. Initial experiments reveal that while vision-only models struggle, vision-language models, particularly those leveraging large language models, show promising results. HumorDB also shows potential as a valuable zero-shot benchmark for powerful large multimodal models. We open-source both the dataset and code under the CC BY 4.0 license.
Read more6/21/2024
🔮
0
Towards Multimodal Prediction of Spontaneous Humour: A Novel Dataset and First Results
Lukas Christ, Shahin Amiriparian, Alexander Kathan, Niklas Muller, Andreas Konig, Bjorn W. Schuller
Humor is a substantial element of human social behavior, affect, and cognition. Its automatic understanding can facilitate a more naturalistic human-AI interaction. Current methods of humor detection have been exclusively based on staged data, making them inadequate for real-world applications. We contribute to addressing this deficiency by introducing the novel Passau-Spontaneous Football Coach Humor (Passau-SFCH) dataset, comprising about 11 hours of recordings. The Passau-SFCH dataset is annotated for the presence of humor and its dimensions (sentiment and direction) as proposed in Martin's Humor Style Questionnaire. We conduct a series of experiments employing pretrained Transformers, convolutional neural networks, and expert-designed features. The performance of each modality (text, audio, video) for spontaneous humor recognition is analyzed and their complementarity is investigated. Our findings suggest that for the automatic analysis of humor and its sentiment, facial expressions are most promising, while humor direction can be best modeled via text-based features. Further, we experiment with different multimodal approaches to humor recognition, including decision-level fusion and MulT, a multimodal Transformer approach. In this context, we propose a novel multimodal architecture that yields the best overall results. Finally, we make our code publicly available at https://www.github.com/lc0197/passau-sfch. The Passau-SFCH dataset is available upon request.
Read more7/9/2024