The MuSe 2024 Multimodal Sentiment Analysis Challenge: Social Perception and Humor Recognition

0
👁️
Sign in to get full access
Overview
- The MuSe 2024 Multimodal Sentiment Analysis Challenge focuses on two key areas: social perception and humor recognition.
- The challenge aims to advance the field of affective computing by developing models that can accurately analyze sentiment, social cues, and humor in multimodal data.
- Participants will work on tasks related to detecting sentiment and social perceptions from audio, visual, and text data, as well as recognizing humor in multimodal content.
Plain English Explanation
The MuSe 2024 Multimodal Sentiment Analysis Challenge is an opportunity for researchers and developers to push the boundaries of affective computing. The challenge focuses on two key areas: understanding social perception and detecting humor in multimodal data.
In the social perception task, participants will work on building models that can analyze sentiment, social cues, and interpersonal dynamics from a combination of audio, visual, and text data. This could involve things like detecting the emotional state of a speaker based on their tone of voice, facial expressions, and the words they use.
The humor recognition task challenges participants to develop models that can identify when content is meant to be humorous, even if it's not explicitly stated. This might involve looking for patterns in the way people communicate, such as the use of irony, sarcasm, or exaggeration, to recognize when they are trying to be funny.
By tackling these challenging problems, the MuSe 2024 challenge aims to advance the state-of-the-art in affective computing and create new opportunities for applications that can better understand and respond to human emotion and social dynamics.
Technical Explanation
The MuSe 2024 Multimodal Sentiment Analysis Challenge consists of two sub-challenges: social perception and humor recognition.
In the social perception task, participants will develop models that can analyze sentiment, social cues, and interpersonal dynamics from multimodal data, including audio, visual, and text. This could involve tasks like detecting the emotional state of a speaker based on their tone of voice, facial expressions, and the words they use.
The humor recognition task challenges participants to build models that can identify when content is meant to be humorous, even if it's not explicitly stated. This might involve looking for patterns in the way people communicate, such as the use of irony, sarcasm, or exaggeration, to recognize when they are trying to be funny.
The datasets provided for the challenge will include a variety of multimodal content, such as online videos, social media posts, and other forms of user-generated content. Participants will need to develop innovative approaches to fuse and analyze these different modalities to tackle the tasks effectively.
Critical Analysis
The MuSe 2024 Multimodal Sentiment Analysis Challenge addresses important and complex problems in the field of affective computing. Accurately detecting social perception and humor in multimodal data is a significant challenge that requires sophisticated models and approaches.
One potential limitation of the challenge is the reliance on user-generated content, which can be noisy, biased, and context-dependent. Developing models that can handle these challenges may require additional techniques, such as semi-supervised learning or noise-robust architectures.
Additionally, the challenge may face issues with dataset bias, as the content used may not be representative of diverse cultural and linguistic contexts. Addressing this will be crucial for developing models that can be applied broadly.
Overall, the MuSe 2024 Multimodal Sentiment Analysis Challenge presents an exciting opportunity to advance the field of affective computing. However, researchers and developers will need to carefully consider the challenges and limitations of the tasks to develop truly effective and robust solutions.
Conclusion
The MuSe 2024 Multimodal Sentiment Analysis Challenge is an important initiative that aims to drive progress in the field of affective computing. By focusing on the challenging problems of social perception and humor recognition, the challenge will push researchers and developers to create innovative models and approaches that can better understand and respond to human emotion and social dynamics.
The success of the challenge will depend on the ability of participants to handle the complexities of multimodal data and develop robust, generalized models that can work across diverse contexts. As the field of affective computing continues to evolve, the insights and advancements made through the MuSe 2024 challenge will likely have far-reaching implications for a wide range of applications, from social media analysis to human-computer interaction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
0
The MuSe 2024 Multimodal Sentiment Analysis Challenge: Social Perception and Humor Recognition
Shahin Amiriparian, Lukas Christ, Alexander Kathan, Maurice Gerczuk, Niklas Muller, Steffen Klug, Lukas Stappen, Andreas Konig, Erik Cambria, Bjorn Schuller, Simone Eulitz
The Multimodal Sentiment Analysis Challenge (MuSe) 2024 addresses two contemporary multimodal affect and sentiment analysis problems: In the Social Perception Sub-Challenge (MuSe-Perception), participants will predict 16 different social attributes of individuals such as assertiveness, dominance, likability, and sincerity based on the provided audio-visual data. The Cross-Cultural Humor Detection Sub-Challenge (MuSe-Humor) dataset expands upon the Passau Spontaneous Football Coach Humor (Passau-SFCH) dataset, focusing on the detection of spontaneous humor in a cross-lingual and cross-cultural setting. The main objective of MuSe 2024 is to unite a broad audience from various research domains, including multimodal sentiment analysis, audio-visual affective computing, continuous signal processing, and natural language processing. By fostering collaboration and exchange among experts in these fields, the MuSe 2024 endeavors to advance the understanding and application of sentiment analysis and affective computing across multiple modalities. This baseline paper provides details on each sub-challenge and its corresponding dataset, extracted features from each data modality, and discusses challenge baselines. For our baseline system, we make use of a range of Transformers and expert-designed features and train Gated Recurrent Unit (GRU)-Recurrent Neural Network (RNN) models on them, resulting in a competitive baseline system. On the unseen test datasets of the respective sub-challenges, it achieves a mean Pearson's Correlation Coefficient ($rho$) of 0.3573 for MuSe-Perception and an Area Under the Curve (AUC) value of 0.8682 for MuSe-Humor.
Read more6/13/2024
🔮
0
Towards Multimodal Prediction of Spontaneous Humour: A Novel Dataset and First Results
Lukas Christ, Shahin Amiriparian, Alexander Kathan, Niklas Muller, Andreas Konig, Bjorn W. Schuller
Humor is a substantial element of human social behavior, affect, and cognition. Its automatic understanding can facilitate a more naturalistic human-AI interaction. Current methods of humor detection have been exclusively based on staged data, making them inadequate for real-world applications. We contribute to addressing this deficiency by introducing the novel Passau-Spontaneous Football Coach Humor (Passau-SFCH) dataset, comprising about 11 hours of recordings. The Passau-SFCH dataset is annotated for the presence of humor and its dimensions (sentiment and direction) as proposed in Martin's Humor Style Questionnaire. We conduct a series of experiments employing pretrained Transformers, convolutional neural networks, and expert-designed features. The performance of each modality (text, audio, video) for spontaneous humor recognition is analyzed and their complementarity is investigated. Our findings suggest that for the automatic analysis of humor and its sentiment, facial expressions are most promising, while humor direction can be best modeled via text-based features. Further, we experiment with different multimodal approaches to humor recognition, including decision-level fusion and MulT, a multimodal Transformer approach. In this context, we propose a novel multimodal architecture that yields the best overall results. Finally, we make our code publicly available at https://www.github.com/lc0197/passau-sfch. The Passau-SFCH dataset is available upon request.
Read more7/9/2024
🗣️
0
MSP-Podcast SER Challenge 2024: L'antenne du Ventoux Multimodal Self-Supervised Learning for Speech Emotion Recognition
Jarod Duret (LIA), Mickael Rouvier (LIA), Yannick Est`eve (LIA)
In this work, we detail our submission to the 2024 edition of the MSP-Podcast Speech Emotion Recognition (SER) Challenge. This challenge is divided into two distinct tasks: Categorical Emotion Recognition and Emotional Attribute Prediction. We concentrated our efforts on Task 1, which involves the categorical classification of eight emotional states using data from the MSP-Podcast dataset. Our approach employs an ensemble of models, each trained independently and then fused at the score level using a Support Vector Machine (SVM) classifier. The models were trained using various strategies, including Self-Supervised Learning (SSL) fine-tuning across different modalities: speech alone, text alone, and a combined speech and text approach. This joint training methodology aims to enhance the system's ability to accurately classify emotional states. This joint training methodology aims to enhance the system's ability to accurately classify emotional states. Thus, the system obtained F1-macro of 0.35% on development set.
Read more7/9/2024
0
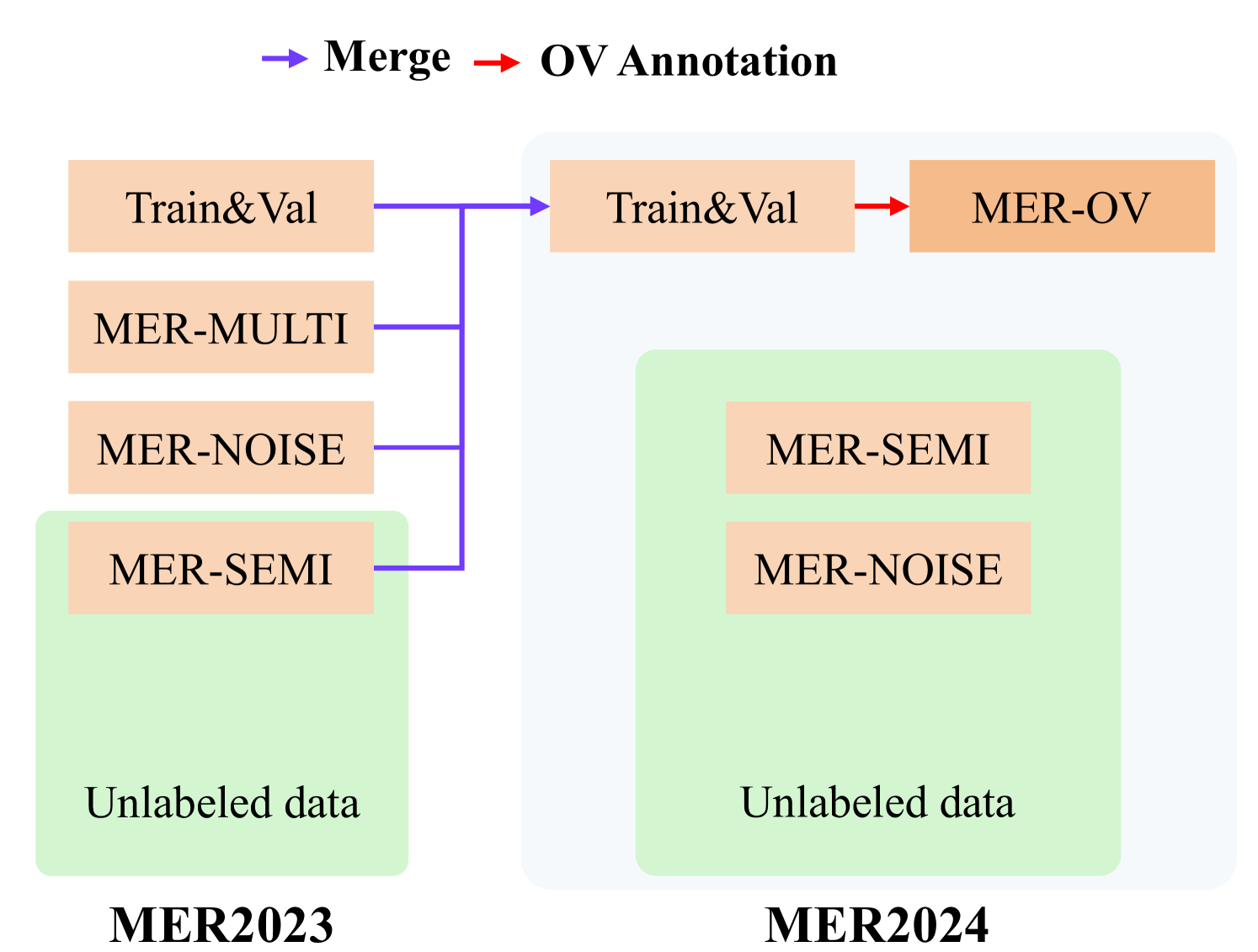
MER 2024: Semi-Supervised Learning, Noise Robustness, and Open-Vocabulary Multimodal Emotion Recognition
Zheng Lian, Haiyang Sun, Licai Sun, Zhuofan Wen, Siyuan Zhang, Shun Chen, Hao Gu, Jinming Zhao, Ziyang Ma, Xie Chen, Jiangyan Yi, Rui Liu, Kele Xu, Bin Liu, Erik Cambria, Guoying Zhao, Bjorn W. Schuller, Jianhua Tao
Multimodal emotion recognition is an important research topic in artificial intelligence. Over the past few decades, researchers have made remarkable progress by increasing the dataset size and building more effective algorithms. However, due to problems such as complex environments and inaccurate annotations, current systems are hard to meet the demands of practical applications. Therefore, we organize the MER series of competitions to promote the development of this field. Last year, we launched MER2023, focusing on three interesting topics: multi-label learning, noise robustness, and semi-supervised learning. In this year's MER2024, besides expanding the dataset size, we further introduce a new track around open-vocabulary emotion recognition. The main purpose of this track is that existing datasets usually fix the label space and use majority voting to enhance the annotator consistency. However, this process may lead to inaccurate annotations, such as ignoring non-majority or non-candidate labels. In this track, we encourage participants to generate any number of labels in any category, aiming to describe emotional states as accurately as possible. Our baseline code relies on MERTools and is available at: https://github.com/zeroQiaoba/MERTools/tree/master/MER2024.
Read more7/19/2024