ChuXin: 1.6B Technical Report
2405.04828
0
0
🎯
Abstract
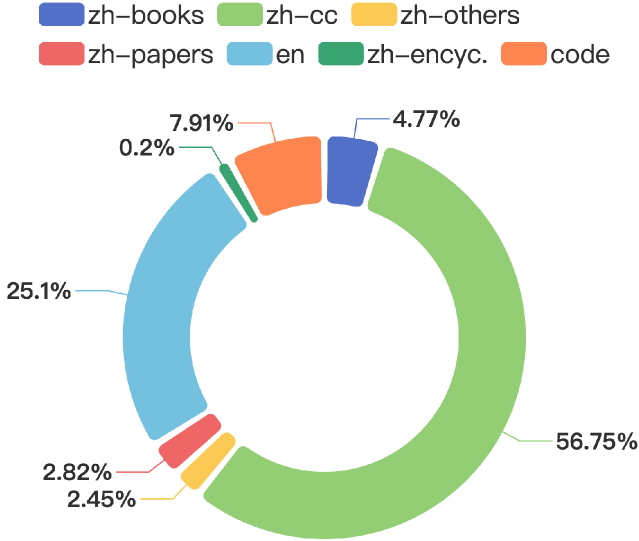
In this report, we present ChuXin, an entirely open-source language model with a size of 1.6 billion parameters. Unlike the majority of works that only open-sourced the model weights and architecture, we have made everything needed to train a model available, including the training data, the training process, and the evaluation code. Our goal is to empower and strengthen the open research community, fostering transparency and enabling a new wave of innovation in the field of language modeling. Furthermore, we extend the context length to 1M tokens through lightweight continual pretraining and demonstrate strong needle-in-a-haystack retrieval performance. The weights for both models are available at Hugging Face to download and use.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- ChuXin is an open-source language model with 1.6 billion parameters
- Unlike most other open-source models, ChuXin provides the training data, process, and evaluation code in addition to the model weights and architecture
- The goal is to empower the research community and enable innovation in language modeling
- ChuXin extends the context length to 1 million tokens through continual pretraining
- The model weights are available on Hugging Face for download and use
Plain English Explanation
ChuXin is a new open-source language model that is different from most other open-source models in an important way. Usually, when a language model is open-sourced, only the final model weights and architecture are made available. However, with ChuXin, the researchers have gone a step further and also released the training data, the process used to train the model, and the code used to evaluate it.
The researchers' goal in doing this is to empower and strengthen the open research community. By providing all the necessary components, they hope to foster transparency and enable more innovation in the field of language modeling. In addition to this, ChuXin has a longer "context length" of 1 million tokens, which means it can understand and generate longer passages of text.
The ChuXin model weights are available for anyone to download and use on the Hugging Face platform. This makes it easy for researchers and developers to access and experiment with the model.
Technical Explanation
ChuXin is a 1.6 billion parameter language model that the researchers have open-sourced entirely, including the training data, training process, and evaluation code. This level of transparency is unusual, as most open-source language models only provide the final model weights and architecture.
By making all of these components available, the researchers aim to empower the open research community and enable further innovation in the field of language modeling. They have also extended ChuXin's context length to 1 million tokens through a process called "lightweight continual pretraining." This allows the model to understand and generate longer passages of text.
The ChuXin model weights are hosted on the Hugging Face platform, making them easily accessible for download and use by researchers and developers.
Critical Analysis
The open-sourcing of ChuXin's training data, process, and evaluation code is a commendable step that aligns with the principles of open science and transparency. This level of access can foster collaboration, enable reproducibility, and catalyze further advancements in the field of language modeling.
However, the paper does not provide detailed information about the specific training data used or the exact continual pretraining process. Additionally, the evaluation of the model's performance, particularly the "needle-in-a-haystack" retrieval task, could benefit from more comprehensive analysis and comparisons to other state-of-the-art models.
Nonetheless, the ChuXin project represents a valuable contribution to the open-source language modeling ecosystem, and it will be interesting to see how the research community builds upon this foundation in the future.
Conclusion
ChuXin is an open-source language model that breaks new ground by making its training data, process, and evaluation code publicly available, in addition to the model weights and architecture. This level of transparency is intended to empower the research community and enable further innovation in language modeling.
By extending the context length to 1 million tokens, ChuXin also demonstrates strong performance on long-range text understanding and retrieval tasks. The availability of the model weights on Hugging Face makes ChuXin easily accessible for researchers and developers to download and experiment with.
While the paper could benefit from additional details and analysis, the ChuXin project represents an important step towards fostering open and collaborative advancements in the field of natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Chinese Tiny LLM: Pretraining a Chinese-Centric Large Language Model
Xinrun Du, Zhouliang Yu, Songyang Gao, Ding Pan, Yuyang Cheng, Ziyang Ma, Ruibin Yuan, Xingwei Qu, Jiaheng Liu, Tianyu Zheng, Xinchen Luo, Guorui Zhou, Binhang Yuan, Wenhu Chen, Jie Fu, Ge Zhang
0
0
In this study, we introduce CT-LLM, a 2B large language model (LLM) that illustrates a pivotal shift towards prioritizing the Chinese language in developing LLMs. Uniquely initiated from scratch, CT-LLM diverges from the conventional methodology by primarily incorporating Chinese textual data, utilizing an extensive corpus of 1,200 billion tokens, including 800 billion Chinese tokens, 300 billion English tokens, and 100 billion code tokens. This strategic composition facilitates the model's exceptional proficiency in understanding and processing Chinese, a capability further enhanced through alignment techniques. Demonstrating remarkable performance on the CHC-Bench, CT-LLM excels in Chinese language tasks, and showcases its adeptness in English through SFT. This research challenges the prevailing paradigm of training LLMs predominantly on English corpora and then adapting them to other languages, broadening the horizons for LLM training methodologies. By open-sourcing the full process of training a Chinese LLM, including a detailed data processing procedure with the obtained Massive Appropriate Pretraining Chinese Corpus (MAP-CC), a well-chosen multidisciplinary Chinese Hard Case Benchmark (CHC-Bench), and the 2B-size Chinese Tiny LLM (CT-LLM), we aim to foster further exploration and innovation in both academia and industry, paving the way for more inclusive and versatile language models.
4/10/2024
🐍
Tele-FLM Technical Report
Xiang Li, Yiqun Yao, Xin Jiang, Xuezhi Fang, Chao Wang, Xinzhang Liu, Zihan Wang, Yu Zhao, Xin Wang, Yuyao Huang, Shuangyong Song, Yongxiang Li, Zheng Zhang, Bo Zhao, Aixin Sun, Yequan Wang, Zhongjiang He, Zhongyuan Wang, Xuelong Li, Tiejun Huang
0
0
Large language models (LLMs) have showcased profound capabilities in language understanding and generation, facilitating a wide array of applications. However, there is a notable paucity of detailed, open-sourced methodologies on efficiently scaling LLMs beyond 50 billion parameters with minimum trial-and-error cost and computational resources. In this report, we introduce Tele-FLM (aka FLM-2), a 52B open-sourced multilingual large language model that features a stable, efficient pre-training paradigm and enhanced factual judgment capabilities. Tele-FLM demonstrates superior multilingual language modeling abilities, measured by BPB on textual corpus. Besides, in both English and Chinese foundation model evaluation, it is comparable to strong open-sourced models that involve larger pre-training FLOPs, such as Llama2-70B and DeepSeek-67B. In addition to the model weights, we share the core designs, engineering practices, and training details, which we expect to benefit both the academic and industrial communities.
4/26/2024
TeenyTinyLlama: open-source tiny language models trained in Brazilian Portuguese
Nicholas Kluge Corr^ea, Sophia Falk, Shiza Fatimah, Aniket Sen, Nythamar de Oliveira
0
0
Large language models (LLMs) have significantly advanced natural language processing, but their progress has yet to be equal across languages. While most LLMs are trained in high-resource languages like English, multilingual models generally underperform monolingual ones. Additionally, aspects of their multilingual foundation sometimes restrict the byproducts they produce, like computational demands and licensing regimes. In this study, we document the development of open-foundation models tailored for use in low-resource settings, their limitations, and their benefits. This is the TeenyTinyLlama pair: two compact models for Brazilian Portuguese text generation. We release them under the permissive Apache 2.0 license on GitHub and Hugging Face for community use and further development. See https://github.com/Nkluge-correa/TeenyTinyLlama
5/20/2024

Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Marah Abdin, Sam Ade Jacobs, Ammar Ahmad Awan, Jyoti Aneja, Ahmed Awadallah, Hany Awadalla, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Harkirat Behl, Alon Benhaim, Misha Bilenko, Johan Bjorck, S'ebastien Bubeck, Martin Cai, Caio C'esar Teodoro Mendes, Weizhu Chen, Vishrav Chaudhary, Parul Chopra, Allie Del Giorno, Gustavo de Rosa, Matthew Dixon, Ronen Eldan, Dan Iter, Amit Garg, Abhishek Goswami, Suriya Gunasekar, Emman Haider, Junheng Hao, Russell J. Hewett, Jamie Huynh, Mojan Javaheripi, Xin Jin, Piero Kauffmann, Nikos Karampatziakis, Dongwoo Kim, Mahoud Khademi, Lev Kurilenko, James R. Lee, Yin Tat Lee, Yuanzhi Li, Chen Liang, Weishung Liu, Eric Lin, Zeqi Lin, Piyush Madan, Arindam Mitra, Hardik Modi, Anh Nguyen, Brandon Norick, Barun Patra, Daniel Perez-Becker, Thomas Portet, Reid Pryzant, Heyang Qin, Marko Radmilac, Corby Rosset, Sambudha Roy, Olatunji Ruwase, Olli Saarikivi, Amin Saied, Adil Salim, Michael Santacroce, Shital Shah, Ning Shang, Hiteshi Sharma, Xia Song, Masahiro Tanaka, Xin Wang, Rachel Ward, Guanhua Wang, Philipp Witte, Michael Wyatt, Can Xu, Jiahang Xu, Sonali Yadav, Fan Yang, Ziyi Yang, Donghan Yu, Chengruidong Zhang, Cyril Zhang, Jianwen Zhang, Li Lyna Zhang, Yi Zhang, Yue Zhang, Yunan Zhang, Xiren Zhou
0
0
We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
4/24/2024