Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
2404.14219
410
0

Abstract
We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Introduces a highly capable language model, Phi-3, that can run locally on a cell phone
- Provides technical details on the model's architecture, performance, and capabilities
- Explores the potential benefits and challenges of deploying large language models on mobile devices
Plain English Explanation
This research paper describes a new language model called Phi-3 that can run directly on a cell phone, without needing to connect to the internet or a remote server. Highly capable language models like GPT-3 have shown impressive abilities at tasks like answering questions, summarizing text, and generating human-like writing. However, these models are usually very large and require significant computing power to run, making them difficult to deploy on everyday mobile devices.
The key innovation of Phi-3 is that it is designed to deliver high performance and capability while still being small enough to run locally on a cell phone. This means you could use advanced language AI features like natural language generation or question answering without needing an internet connection or cloud computing resources. The researchers achieved this by carefully optimizing the model architecture and training process to balance size, speed, and accuracy.
If successful, Phi-3 could pave the way for a new generation of highly capable AI assistants that can run directly on our smartphones and other mobile devices, without the need to send our data to the cloud. This could have important implications for privacy, security, and accessibility, especially in areas with unreliable internet access. However, there are also technical challenges in making such a powerful model run efficiently on limited hardware.
Technical Explanation
The Phi-3 model is built using a transformer-based architecture, similar to large language models like GPT-3, but with several key optimizations to reduce the model size and improve efficiency. These include:
- Lightweight attention mechanisms: The model uses a more efficient attention module design compared to standard transformers, reducing the number of parameters required.
- Knowledge distillation: The researchers trained Phi-3 by distilling knowledge from a larger teacher model, allowing it to achieve high performance with a much smaller model size.
- Quantization: The model weights are quantized to lower precision data types (e.g. 8-bit integers), further reducing the memory footprint without significant accuracy loss.
Through these and other optimizations, the final Phi-3 model is able to achieve state-of-the-art performance on a range of language tasks while being small enough to run locally on a smartphone processor. The researchers report that Phi-3 has a model size under 500MB and can perform inference in under 500ms, making it viable for real-time applications.
The paper also includes detailed evaluations of Phi-3's performance, comparing it to other compact language models such as Octopus V3 and TinyGPT-V. The results demonstrate Phi-3's ability to match or exceed the accuracy of these other models while being significantly smaller in size.
Critical Analysis
The Phi-3 research represents an important step towards making highly capable language AI models practical for deployment on mobile and edge devices. By addressing the challenges of model size and computational efficiency, the researchers have shown it is possible to bring cutting-edge natural language processing capabilities directly to users' fingertips.
However, the paper does not deeply explore some potential limitations and tradeoffs of this approach. For example, it is unclear how Phi-3's performance would scale to more complex or open-ended language tasks compared to larger cloud-based models. There may also be challenges in keeping the model up-to-date and adapting it to new domains without access to the compute resources available in the cloud.
Additionally, while the focus on privacy and accessibility is commendable, the paper does not address potential misuse or societal impacts of having such powerful language AI running directly on user devices. Issues around algorithmic bias, data privacy, and the responsible development of these technologies should be carefully considered.
Overall, the Phi-3 research represents an exciting step forward, but follow-up work will be needed to fully realize the potential benefits and mitigate the risks of deploying large language models on mobile devices.
Conclusion
The Phi-3 technical report describes a highly capable language model that can run locally on a cell phone, overcoming the typical size and performance constraints of deploying such models on mobile hardware. This innovation has the potential to enable a new generation of advanced AI assistants that operate directly on user devices, without the need for an internet connection or cloud computing resources.
By carefully optimizing the model architecture and training process, the researchers have demonstrated that it is possible to achieve state-of-the-art natural language processing capabilities in a compact, efficient package. If successful, this work could have far-reaching implications for privacy, accessibility, and the real-world deployment of large language AI models.
However, the paper also highlights the need for further research to fully address the challenges and potential risks of this approach. Ongoing work will be required to ensure these technologies are developed and deployed responsibly, with a focus on user safety, algorithmic fairness, and the broader societal impact.
Related Papers
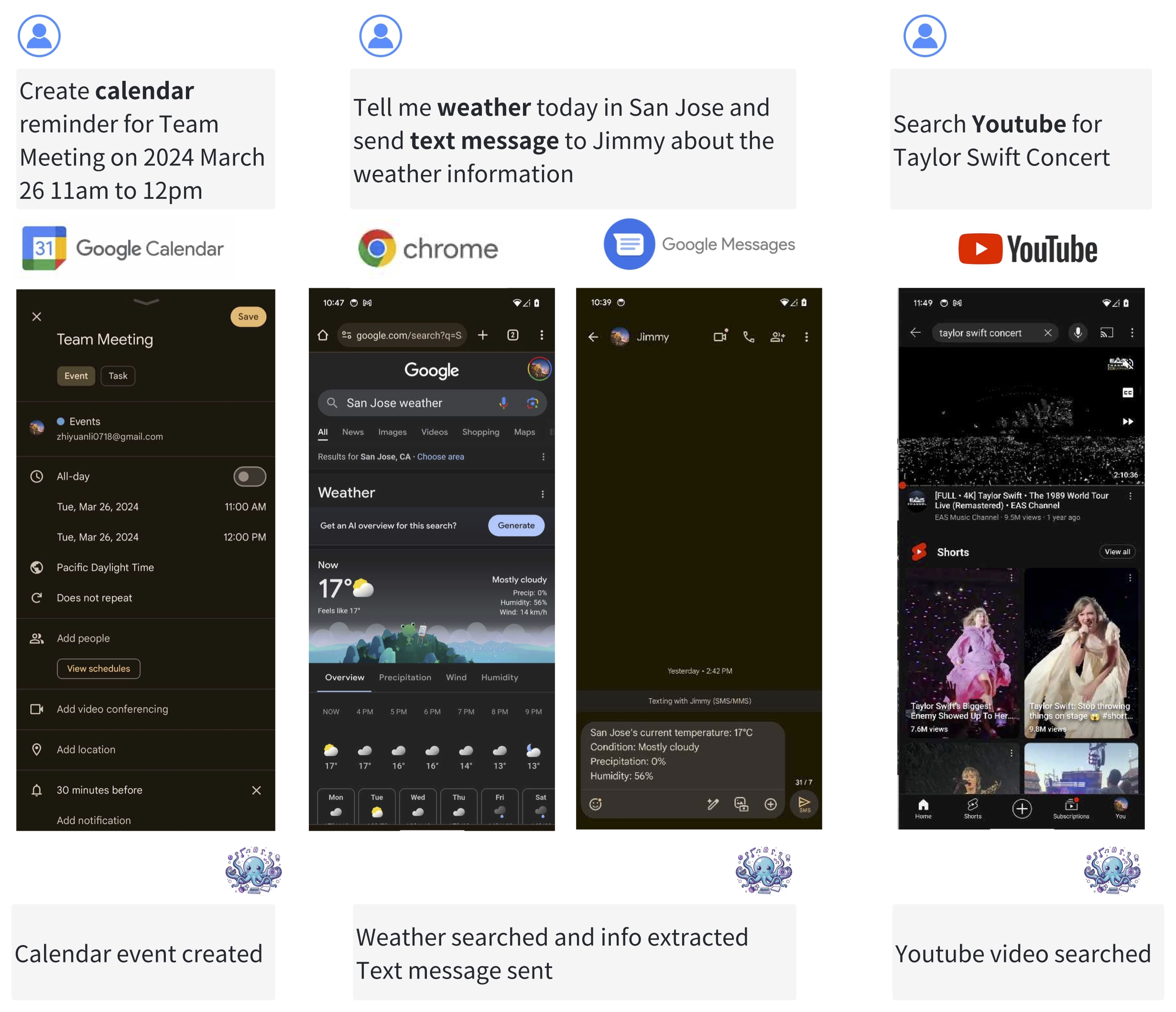
Octopus v2: On-device language model for super agent
Wei Chen, Zhiyuan Li
0
0
Language models have shown effectiveness in a variety of software applications, particularly in tasks related to automatic workflow. These models possess the crucial ability to call functions, which is essential in creating AI agents. Despite the high performance of large-scale language models in cloud environments, they are often associated with concerns over privacy and cost. Current on-device models for function calling face issues with latency and accuracy. Our research presents a new method that empowers an on-device model with 2 billion parameters to surpass the performance of GPT-4 in both accuracy and latency, and decrease the context length by 95%. When compared to Llama-7B with a RAG-based function calling mechanism, our method enhances latency by 35-fold. This method reduces the latency to levels deemed suitable for deployment across a variety of edge devices in production environments, aligning with the performance requisites for real-world applications.
4/17/2024
🎯
ChuXin: 1.6B Technical Report
Xiaomin Zhuang, Yufan Jiang, Qiaozhi He, Zhihua Wu
0
0
In this report, we present ChuXin, an entirely open-source language model with a size of 1.6 billion parameters. Unlike the majority of works that only open-sourced the model weights and architecture, we have made everything needed to train a model available, including the training data, the training process, and the evaluation code. Our goal is to empower and strengthen the open research community, fostering transparency and enabling a new wave of innovation in the field of language modeling. Furthermore, we extend the context length to 1M tokens through lightweight continual pretraining and demonstrate strong needle-in-a-haystack retrieval performance. The weights for both models are available at Hugging Face to download and use.
5/9/2024
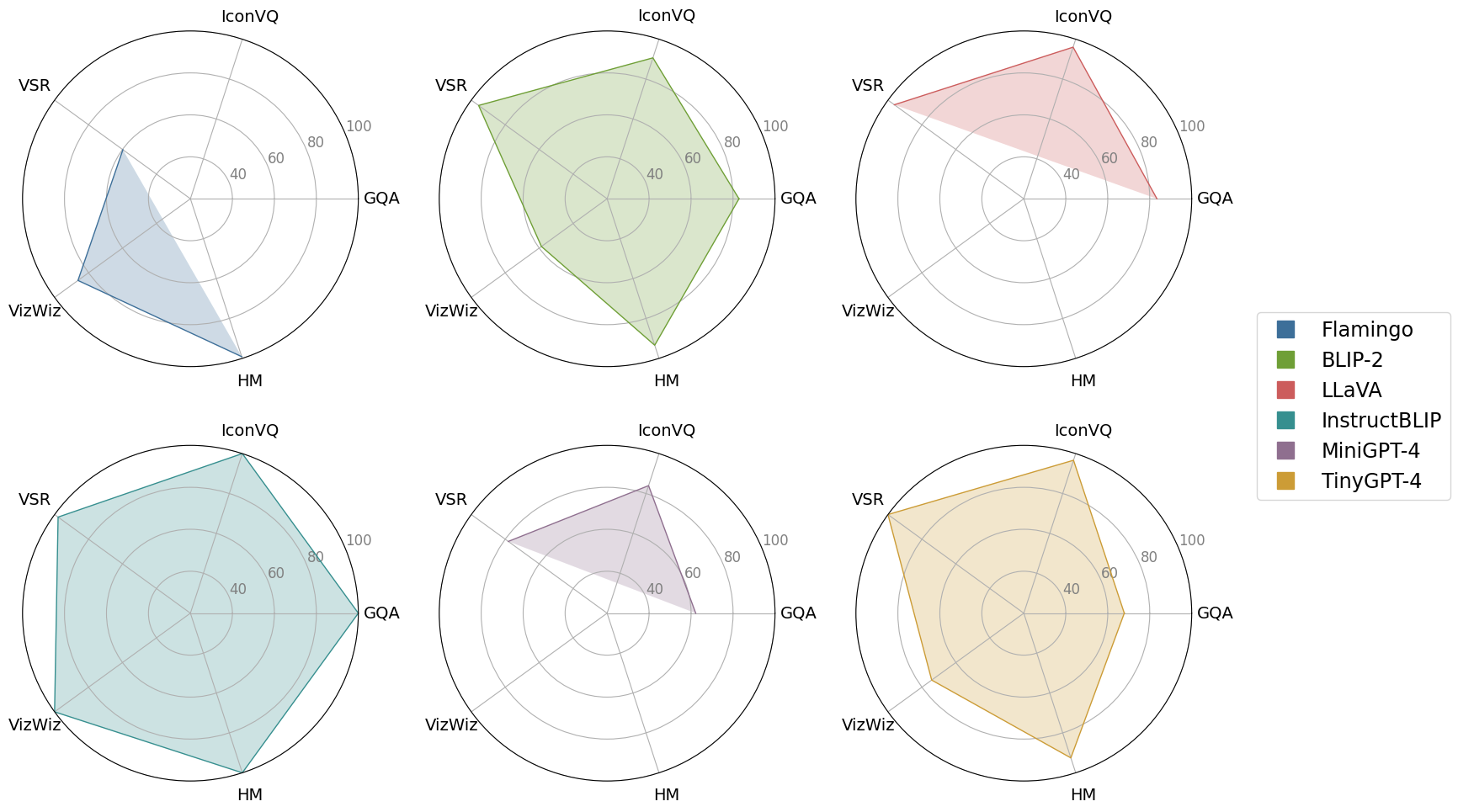
TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones
Zhengqing Yuan, Zhaoxu Li, Weiran Huang, Yanfang Ye, Lichao Sun
0
0
In recent years, multimodal large language models (MLLMs) such as GPT-4V have demonstrated remarkable advancements, excelling in a variety of vision-language tasks. Despite their prowess, the closed-source nature and computational demands of such models limit their accessibility and applicability. This study introduces TinyGPT-V, a novel open-source MLLM, designed for efficient training and inference across various vision-language tasks, including image captioning (IC) and visual question answering (VQA). Leveraging a compact yet powerful architecture, TinyGPT-V integrates the Phi-2 language model with pre-trained vision encoders, utilizing a unique mapping module for visual and linguistic information fusion. With a training regimen optimized for small backbones and employing a diverse dataset amalgam, TinyGPT-V requires significantly lower computational resources 24GB for training and as little as 8GB for inference without compromising on performance. Our experiments demonstrate that TinyGPT-V, with its language model 2.8 billion parameters, achieves comparable results in VQA and image inference tasks to its larger counterparts while being uniquely suited for deployment on resource-constrained devices through innovative quantization techniques. This work not only paves the way for more accessible and efficient MLLMs but also underscores the potential of smaller, optimized models in bridging the gap between high performance and computational efficiency in real-world applications. Additionally, this paper introduces a new approach to multimodal large language models using smaller backbones. Our code and training weights are available in url{https://github.com/DLYuanGod/TinyGPT-V}.
4/8/2024
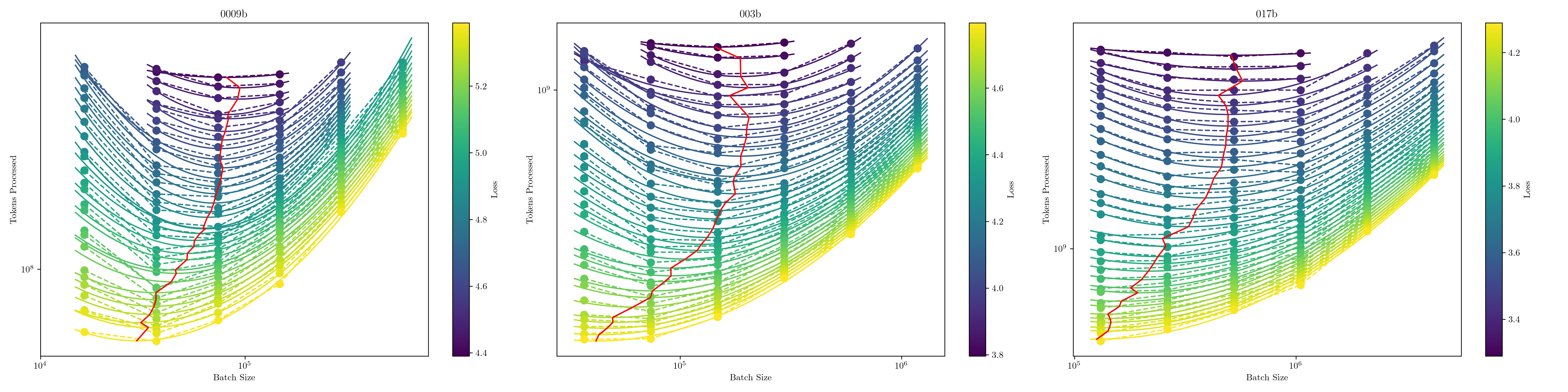
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
Shengding Hu, Yuge Tu, Xu Han, Chaoqun He, Ganqu Cui, Xiang Long, Zhi Zheng, Yewei Fang, Yuxiang Huang, Weilin Zhao, Xinrong Zhang, Zheng Leng Thai, Kaihuo Zhang, Chongyi Wang, Yuan Yao, Chenyang Zhao, Jie Zhou, Jie Cai, Zhongwu Zhai, Ning Ding, Chao Jia, Guoyang Zeng, Dahai Li, Zhiyuan Liu, Maosong Sun
0
0
The burgeoning interest in developing Large Language Models (LLMs) with up to trillion parameters has been met with concerns regarding resource efficiency and practical expense, particularly given the immense cost of experimentation. This scenario underscores the importance of exploring the potential of Small Language Models (SLMs) as a resource-efficient alternative. In this context, we introduce MiniCPM, specifically the 1.2B and 2.4B non-embedding parameter variants, not only excel in their respective categories but also demonstrate capabilities on par with 7B-13B LLMs. While focusing on SLMs, our approach exhibits scalability in both model and data dimensions for future LLM research. Regarding model scaling, we employ extensive model wind tunnel experiments for stable and optimal scaling. For data scaling, we introduce a Warmup-Stable-Decay (WSD) learning rate scheduler (LRS), conducive to continuous training and domain adaptation. We present an in-depth analysis of the intriguing training dynamics that occurred in the WSD LRS. With WSD LRS, we are now able to efficiently study data-model scaling law without extensive retraining experiments on both axes of model and data, from which we derive the much higher compute optimal data-model ratio than Chinchilla Optimal. Additionally, we introduce MiniCPM family, including MiniCPM-DPO, MiniCPM-MoE and MiniCPM-128K, whose excellent performance further cementing MiniCPM's foundation in diverse SLM applications. MiniCPM models are available publicly at https://github.com/OpenBMB/MiniCPM .
4/23/2024