Class-Incremental Few-Shot Event Detection

0

Sign in to get full access
Overview
- This paper introduces a novel approach to class-incremental few-shot event detection, which aims to expand the capabilities of event detection models to handle new event types with limited training data.
- The proposed method leverages meta-learning and prototypical networks to enable efficient adaptation to new event types while preserving performance on previously learned types.
- The paper evaluates the approach on a standard event detection benchmark and demonstrates its effectiveness compared to existing few-shot and incremental learning techniques.
Plain English Explanation
Event detection is the task of automatically identifying and categorizing different types of events, such as natural disasters, business deals, or political changes, from text data. This is an important capability for many real-world applications, like monitoring news feeds or social media.
However, most existing event detection models are limited in their ability to handle new types of events that may emerge over time. They typically require large amounts of labeled training data for each event type, which can be costly and time-consuming to obtain.
The researchers in this paper propose a new approach that can efficiently learn to detect new event types with just a few examples. Their key insight is to use meta-learning, which trains the model to quickly adapt to new tasks with limited data. Specifically, they leverage prototypical networks, a meta-learning technique that learns to represent each event type as a "prototype" in a high-dimensional space.
When presented with a new event type, the model can compare the examples to these prototypes and quickly determine the appropriate classification, without needing to completely retrain the entire model. This allows the event detection system to continuously expand its capabilities as new event types arise, without forgetting how to handle the types it has learned previously.
Technical Explanation
The paper introduces a class-incremental few-shot event detection framework that can learn to recognize new event types from limited examples, while preserving performance on previously learned types.
The core of the approach is a prototypical network, which learns a metric space representation where each event type is encoded as a prototype vector. When presented with a new event type, the model compares the examples to the existing prototypes and assigns the new type to the closest one.
To enable incremental learning, the authors propose a novel episodic training procedure that simulates the arrival of new event types over time. During each training episode, the model learns to classify a mix of familiar and novel event types, encouraging it to both retain knowledge of old types and quickly adapt to new ones.
The method is evaluated on the ACE 2005 event detection benchmark, where it outperforms standard few-shot and incremental learning baselines. Ablation studies confirm the importance of the episodic training scheme and the prototypical network architecture for the task.
Critical Analysis
The proposed class-incremental few-shot event detection approach represents an important step forward in building more flexible and adaptive event understanding systems. By enabling efficient learning of new event types from limited data, it helps address a key limitation of current event detection models.
However, the paper does not thoroughly explore the model's ability to handle highly related or overlapping event types, which could pose challenges in a real-world setting where the event ontology is continuously evolving. The authors also do not assess the model's robustness to noisy or ambiguous training examples, which are common issues in practical event detection applications.
Additionally, while the prototypical network architecture is well-suited for few-shot learning, it may struggle to capture more complex relationships between event types. Exploring alternative meta-learning techniques or hybrid approaches could potentially yield further improvements in performance and flexibility.
Overall, this work provides a strong foundation for advancing the state-of-the-art in event detection, but there remains ample room for future research to address the remaining challenges in building truly versatile and robust event understanding systems.
Conclusion
This paper presents a novel class-incremental few-shot learning approach for event detection that can efficiently adapt to recognize new event types from limited examples, while preserving its performance on previously learned types. The key innovation is the use of prototypical networks, which learn to represent each event type as a compact prototype in a learned metric space.
This enables the model to quickly classify new event instances by comparing them to the existing prototypes, without the need for costly retraining. Experiments on a standard benchmark demonstrate the effectiveness of the proposed method compared to existing few-shot and incremental learning techniques.
While further research is needed to address certain limitations, this work represents an important step towards building more flexible and adaptive event detection systems that can continually expand their capabilities to handle the evolving real-world event landscape.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Class-Incremental Few-Shot Event Detection
Kailin Zhao, Xiaolong Jin, Long Bai, Jiafeng Guo, Xueqi Cheng
Event detection is one of the fundamental tasks in information extraction and knowledge graph. However, a realistic event detection system often needs to deal with new event classes constantly. These new classes usually have only a few labeled instances as it is time-consuming and labor-intensive to annotate a large number of unlabeled instances. Therefore, this paper proposes a new task, called class-incremental few-shot event detection. Nevertheless, this task faces two problems, i.e., old knowledge forgetting and new class overfitting. To solve these problems, this paper further presents a novel knowledge distillation and prompt learning based method, called Prompt-KD. Specifically, to handle the forgetting problem about old knowledge, Prompt-KD develops an attention based multi-teacher knowledge distillation framework, where the ancestor teacher model pre-trained on base classes is reused in all learning sessions, and the father teacher model derives the current student model via adaptation. On the other hand, in order to cope with the few-shot learning scenario and alleviate the corresponding new class overfitting problem, Prompt-KD is also equipped with a prompt learning mechanism. Extensive experiments on two benchmark datasets, i.e., FewEvent and MAVEN, demonstrate the superior performance of Prompt-KD.
Read more4/3/2024
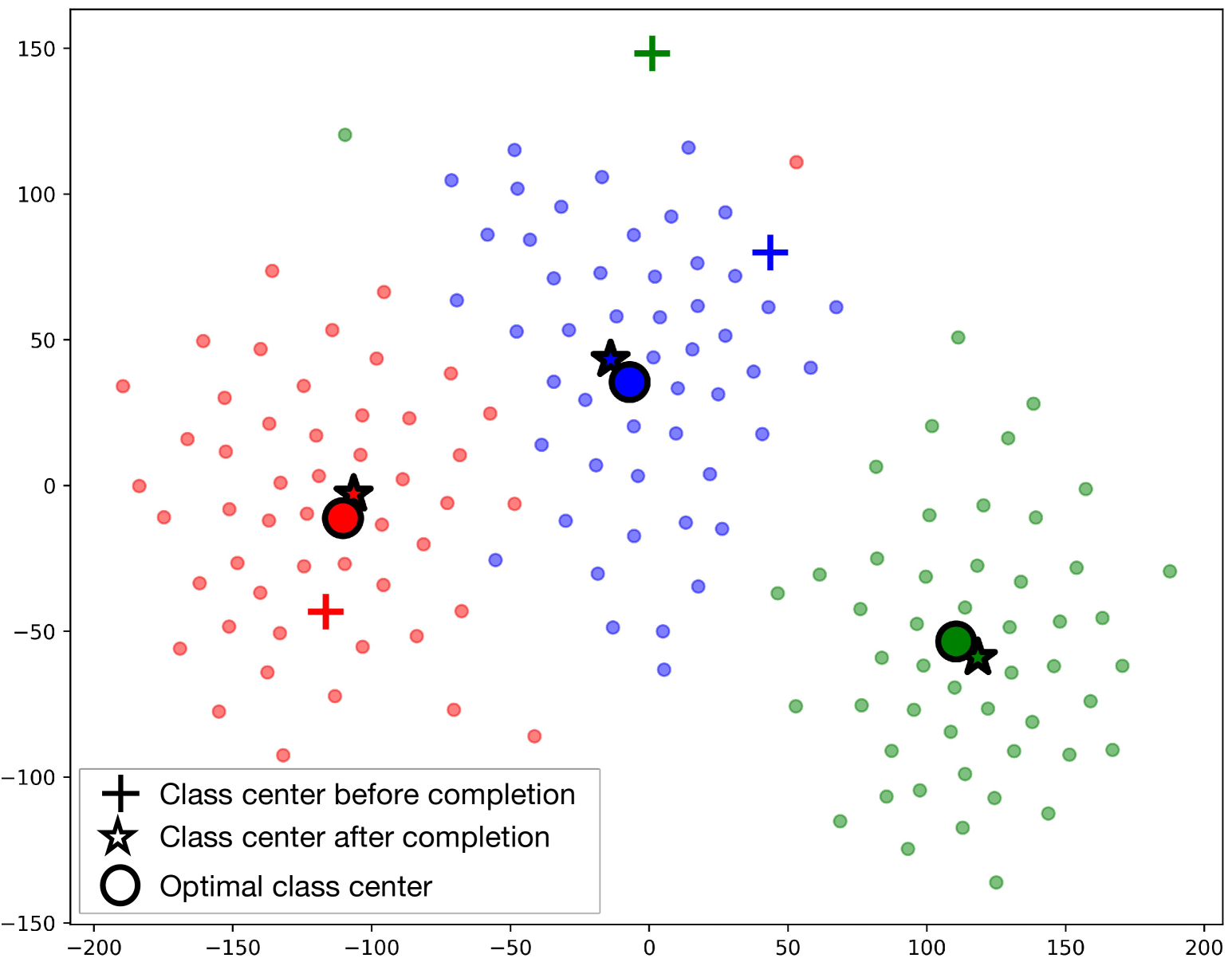
0
The Devil is in the Few Shots: Iterative Visual Knowledge Completion for Few-shot Learning
Yaohui Li, Qifeng Zhou, Haoxing Chen, Jianbing Zhang, Xinyu Dai, Hao Zhou
Contrastive Language-Image Pre-training (CLIP) has shown powerful zero-shot learning performance. Few-shot learning aims to further enhance the transfer capability of CLIP by giving few images in each class, aka 'few shots'. Most existing methods either implicitly learn from the few shots by incorporating learnable prompts or adapters, or explicitly embed them in a cache model for inference. However, the narrow distribution of few shots often contains incomplete class information, leading to biased visual knowledge with high risk of misclassification. To tackle this problem, recent methods propose to supplement visual knowledge by generative models or extra databases, which can be costly and time-consuming. In this paper, we propose an Iterative Visual Knowledge CompLetion (KCL) method to complement visual knowledge by properly taking advantages of unlabeled samples without access to any auxiliary or synthetic data. Specifically, KCL first measures the similarities between unlabeled samples and each category. Then, the samples with top confidence to each category is selected and collected by a designed confidence criterion. Finally, the collected samples are treated as labeled ones and added to few shots to jointly re-estimate the remaining unlabeled ones. The above procedures will be repeated for a certain number of iterations with more and more samples being collected until convergence, ensuring a progressive and robust knowledge completion process. Extensive experiments on 11 benchmark datasets demonstrate the effectiveness and efficiency of KCL as a plug-and-play module under both few-shot and zero-shot learning settings. Code is available at https://github.com/Mark-Sky/KCL.
Read more4/22/2024

0
Knowledge Adaptation Network for Few-Shot Class-Incremental Learning
Ye Wang, Yaxiong Wang, Guoshuai Zhao, Xueming Qian
Few-shot class-incremental learning (FSCIL) aims to incrementally recognize new classes using a few samples while maintaining the performance on previously learned classes. One of the effective methods to solve this challenge is to construct prototypical evolution classifiers. Despite the advancement achieved by most existing methods, the classifier weights are simply initialized using mean features. Because representations for new classes are weak and biased, we argue such a strategy is suboptimal. In this paper, we tackle this issue from two aspects. Firstly, thanks to the development of foundation models, we employ a foundation model, the CLIP, as the network pedestal to provide a general representation for each class. Secondly, to generate a more reliable and comprehensive instance representation, we propose a Knowledge Adapter (KA) module that summarizes the data-specific knowledge from training data and fuses it into the general representation. Additionally, to tune the knowledge learned from the base classes to the upcoming classes, we propose a mechanism of Incremental Pseudo Episode Learning (IPEL) by simulating the actual FSCIL. Taken together, our proposed method, dubbed as Knowledge Adaptation Network (KANet), achieves competitive performance on a wide range of datasets, including CIFAR100, CUB200, and ImageNet-R.
Read more9/19/2024

0
Few-Shot Class-Incremental Learning with Non-IID Decentralized Data
Cuiwei Liu, Siang Xu, Huaijun Qiu, Jing Zhang, Zhi Liu, Liang Zhao
Few-shot class-incremental learning is crucial for developing scalable and adaptive intelligent systems, as it enables models to acquire new classes with minimal annotated data while safeguarding the previously accumulated knowledge. Nonetheless, existing methods deal with continuous data streams in a centralized manner, limiting their applicability in scenarios that prioritize data privacy and security. To this end, this paper introduces federated few-shot class-incremental learning, a decentralized machine learning paradigm tailored to progressively learn new classes from scarce data distributed across multiple clients. In this learning paradigm, clients locally update their models with new classes while preserving data privacy, and then transmit the model updates to a central server where they are aggregated globally. However, this paradigm faces several issues, such as difficulties in few-shot learning, catastrophic forgetting, and data heterogeneity. To address these challenges, we present a synthetic data-driven framework that leverages replay buffer data to maintain existing knowledge and facilitate the acquisition of new knowledge. Within this framework, a noise-aware generative replay module is developed to fine-tune local models with a balance of new and replay data, while generating synthetic data of new classes to further expand the replay buffer for future tasks. Furthermore, a class-specific weighted aggregation strategy is designed to tackle data heterogeneity by adaptively aggregating class-specific parameters based on local models performance on synthetic data. This enables effective global model optimization without direct access to client data. Comprehensive experiments across three widely-used datasets underscore the effectiveness and preeminence of the introduced framework.
Read more9/19/2024