The Devil is in the Few Shots: Iterative Visual Knowledge Completion for Few-shot Learning
2404.09778
0
0
Abstract
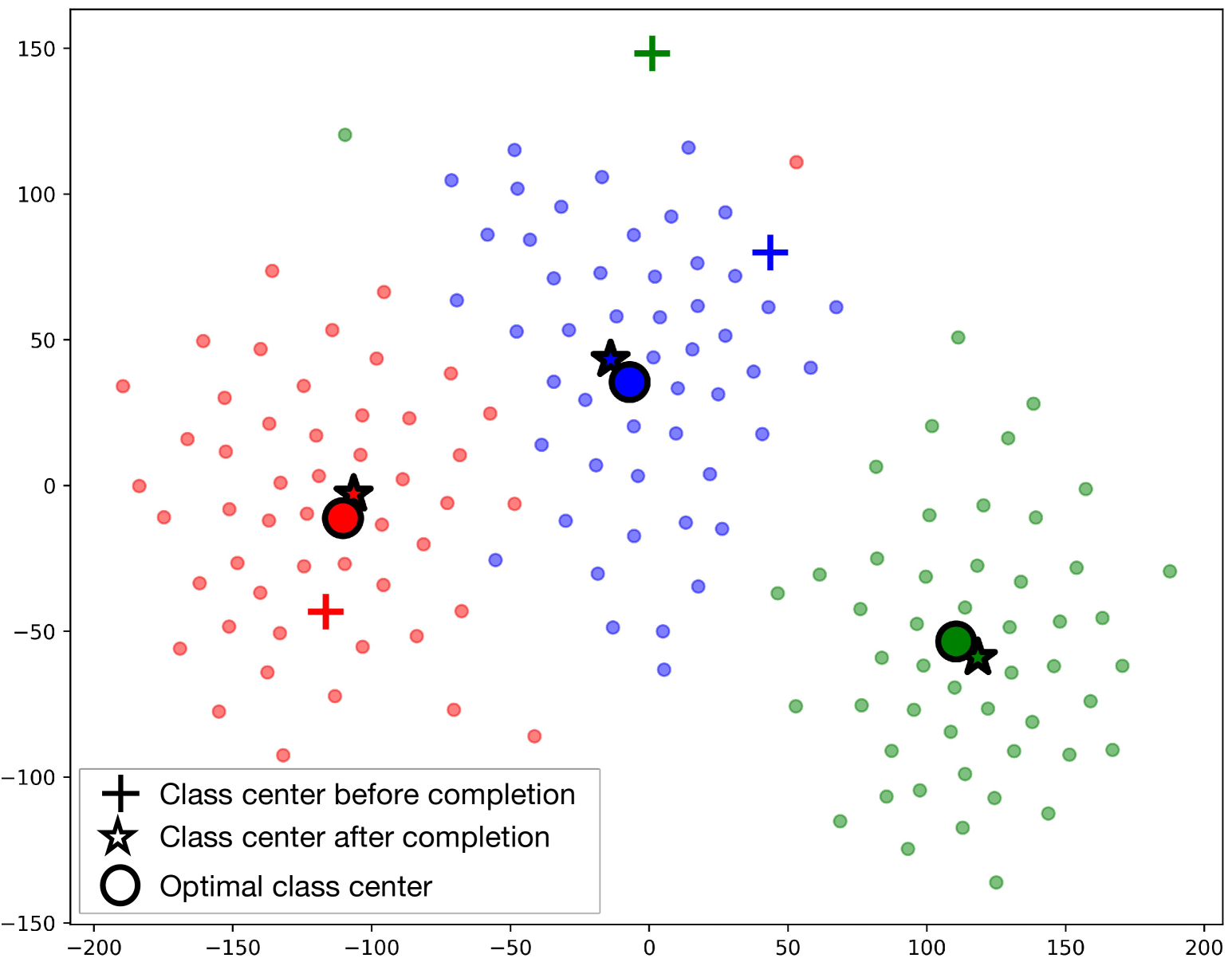
Contrastive Language-Image Pre-training (CLIP) has shown powerful zero-shot learning performance. Few-shot learning aims to further enhance the transfer capability of CLIP by giving few images in each class, aka 'few shots'. Most existing methods either implicitly learn from the few shots by incorporating learnable prompts or adapters, or explicitly embed them in a cache model for inference. However, the narrow distribution of few shots often contains incomplete class information, leading to biased visual knowledge with high risk of misclassification. To tackle this problem, recent methods propose to supplement visual knowledge by generative models or extra databases, which can be costly and time-consuming. In this paper, we propose an Iterative Visual Knowledge CompLetion (KCL) method to complement visual knowledge by properly taking advantages of unlabeled samples without access to any auxiliary or synthetic data. Specifically, KCL first measures the similarities between unlabeled samples and each category. Then, the samples with top confidence to each category is selected and collected by a designed confidence criterion. Finally, the collected samples are treated as labeled ones and added to few shots to jointly re-estimate the remaining unlabeled ones. The above procedures will be repeated for a certain number of iterations with more and more samples being collected until convergence, ensuring a progressive and robust knowledge completion process. Extensive experiments on 11 benchmark datasets demonstrate the effectiveness and efficiency of KCL as a plug-and-play module under both few-shot and zero-shot learning settings. Code is available at https://github.com/Mark-Sky/KCL.
Create account to get full access
Overview
- This paper proposes an "Iterative Visual Knowledge Completion" (IVKC) approach to address the challenge of few-shot learning in vision-language models.
- The key idea is to iteratively complete the visual knowledge of a model by gradually incorporating additional information from few labeled examples.
- The method aims to improve the model's ability to understand and reason about visual concepts, even with limited training data.
Plain English Explanation
The paper focuses on the challenge of <a href="https://aimodels.fyi/papers/arxiv/class-incremental-few-shot-event-detection">few-shot learning</a> in vision-language models. This means teaching these models to recognize and understand new visual concepts using only a small number of examples, rather than the large datasets typically required.
The researchers developed a technique called "Iterative Visual Knowledge Completion" (IVKC) to address this challenge. The core idea is to gradually build up the model's visual knowledge by incrementally incorporating information from the few labeled examples available.
Rather than trying to learn everything at once from a small dataset, the IVKC approach allows the model to iteratively refine and expand its understanding. This helps the model better grasp the new visual concepts, even when very little training data is available.
The researchers demonstrate that this iterative approach can lead to significant improvements in the model's few-shot learning capabilities, compared to more conventional methods. By gradually completing the model's visual knowledge, it becomes better equipped to recognize and reason about new visual concepts from limited examples.
Technical Explanation
The paper proposes an "Iterative Visual Knowledge Completion" (IVKC) approach to address few-shot learning in vision-language models. The key components of the IVKC method are:
-
Knowledge Initialization: The model is first pre-trained on a large-scale vision-language dataset to acquire general visual and linguistic knowledge.
-
Iterative Knowledge Completion: In the few-shot learning stage, the model iteratively refines its visual knowledge by incorporating information from the limited labeled examples. This is done through a series of steps:
- <a href="https://aimodels.fyi/papers/arxiv/simple-semantic-aided-few-shot-learning">Semantic-guided Visual Completion</a>: The model leverages semantic information from the few labeled examples to guide the completion of its visual knowledge.
- <a href="https://aimodels.fyi/papers/arxiv/pre-trained-vision-language-transformers-are-few">Vision-Language Reasoning</a>: The model uses its acquired visual and linguistic knowledge to reason about the new visual concepts.
- <a href="https://aimodels.fyi/papers/arxiv/mixture-low-rank-experts-transferable-ai-generated">Knowledge Distillation</a>: The model distills knowledge from the completed visual representation to improve its overall few-shot learning performance.
The researchers evaluate the IVKC approach on standard few-shot learning benchmarks, such as <a href="https://aimodels.fyi/papers/arxiv/clip-embed-kd-computationally-efficient-knowledge-distillation">miniImageNet and tieredImageNet</a>. Their results demonstrate significant improvements in few-shot learning accuracy compared to various baseline methods.
Critical Analysis
The paper presents a well-designed and thorough approach to addressing the challenge of few-shot learning in vision-language models. The key strengths of the IVKC method include:
- Iterative Refinement: The iterative nature of the knowledge completion process allows the model to gradually build up its visual understanding, which is a more natural and effective way to learn from limited data.
- Leveraging Semantic Information: The incorporation of semantic guidance from the few labeled examples helps the model better contextualize and complete its visual knowledge.
- Vision-Language Reasoning: The ability to reason about new visual concepts using the model's acquired linguistic and visual understanding is a valuable capability for few-shot learning.
However, the paper also acknowledges some potential limitations and areas for further research:
- Scalability: The iterative knowledge completion process may become computationally expensive as the number of iterations or the size of the dataset increases.
- Generalization: While the method demonstrates strong performance on the evaluated benchmarks, its ability to generalize to more diverse and challenging real-world scenarios could be further explored.
- Interpretability: The inner workings of the iterative knowledge completion process may not be entirely transparent, which could limit the model's interpretability and make it harder to diagnose failure cases.
Overall, the IVKC approach represents a promising step forward in addressing the few-shot learning challenge for vision-language models. Further research into improving its efficiency, generalization, and interpretability could lead to even more robust and practical few-shot learning solutions.
Conclusion
The paper presents an "Iterative Visual Knowledge Completion" (IVKC) approach to improve the few-shot learning capabilities of vision-language models. By gradually building up the model's visual understanding through an iterative process of semantic-guided completion, vision-language reasoning, and knowledge distillation, the IVKC method demonstrates significant improvements in few-shot learning performance.
The key innovation of this work is the iterative nature of the knowledge completion process, which allows the model to learn new visual concepts more effectively from limited data. This represents an important advancement in the field of few-shot learning, with potential applications in a wide range of domains where data scarcity is a challenge.
While the paper identifies some areas for further research, such as improving scalability and interpretability, the IVKC approach showcases a thoughtful and well-executed strategy for enhancing the few-shot learning abilities of vision-language models. As the need for efficient and data-efficient learning continues to grow, this research provides a valuable contribution to the ongoing efforts in this critical area of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
Multimodal CLIP Inference for Meta-Few-Shot Image Classification
Constance Ferragu, Philomene Chagniot, Vincent Coyette
0
0
In recent literature, few-shot classification has predominantly been defined by the N-way k-shot meta-learning problem. Models designed for this purpose are usually trained to excel on standard benchmarks following a restricted setup, excluding the use of external data. Given the recent advancements in large language and vision models, a question naturally arises: can these models directly perform well on meta-few-shot learning benchmarks? Multimodal foundation models like CLIP, which learn a joint (image, text) embedding, are of particular interest. Indeed, multimodal training has proven to enhance model robustness, especially regarding ambiguities, a limitation frequently observed in the few-shot setup. This study demonstrates that combining modalities from CLIP's text and image encoders outperforms state-of-the-art meta-few-shot learners on widely adopted benchmarks, all without additional training. Our results confirm the potential and robustness of multimodal foundation models like CLIP and serve as a baseline for existing and future approaches leveraging such models.
5/21/2024
⛏️
Transductive Zero-Shot and Few-Shot CLIP
S'egol`ene Martin (OPIS, CVN), Yunshi Huang (ETS), Fereshteh Shakeri (ETS), Jean-Christophe Pesquet (OPIS, CVN), Ismail Ben Ayed (ETS)
0
0
Transductive inference has been widely investigated in few-shot image classification, but completely overlooked in the recent, fast growing literature on adapting vision-langage models like CLIP. This paper addresses the transductive zero-shot and few-shot CLIP classification challenge, in which inference is performed jointly across a mini-batch of unlabeled query samples, rather than treating each instance independently. We initially construct informative vision-text probability features, leading to a classification problem on the unit simplex set. Inspired by Expectation-Maximization (EM), our optimization-based classification objective models the data probability distribution for each class using a Dirichlet law. The minimization problem is then tackled with a novel block Majorization-Minimization algorithm, which simultaneously estimates the distribution parameters and class assignments. Extensive numerical experiments on 11 datasets underscore the benefits and efficacy of our batch inference approach.On zero-shot tasks with test batches of 75 samples, our approach yields near 20% improvement in ImageNet accuracy over CLIP's zero-shot performance. Additionally, we outperform state-of-the-art methods in the few-shot setting. The code is available at: https://github.com/SegoleneMartin/transductive-CLIP.
5/30/2024
🛸
Rethinking Prior Information Generation with CLIP for Few-Shot Segmentation
Jin Wang, Bingfeng Zhang, Jian Pang, Honglong Chen, Weifeng Liu
0
0
Few-shot segmentation remains challenging due to the limitations of its labeling information for unseen classes. Most previous approaches rely on extracting high-level feature maps from the frozen visual encoder to compute the pixel-wise similarity as a key prior guidance for the decoder. However, such a prior representation suffers from coarse granularity and poor generalization to new classes since these high-level feature maps have obvious category bias. In this work, we propose to replace the visual prior representation with the visual-text alignment capacity to capture more reliable guidance and enhance the model generalization. Specifically, we design two kinds of training-free prior information generation strategy that attempts to utilize the semantic alignment capability of the Contrastive Language-Image Pre-training model (CLIP) to locate the target class. Besides, to acquire more accurate prior guidance, we build a high-order relationship of attention maps and utilize it to refine the initial prior information. Experiments on both the PASCAL-5{i} and COCO-20{i} datasets show that our method obtains a clearly substantial improvement and reaches the new state-of-the-art performance.
5/15/2024
📈
CLIP-KD: An Empirical Study of CLIP Model Distillation
Chuanguang Yang, Zhulin An, Libo Huang, Junyu Bi, Xinqiang Yu, Han Yang, Boyu Diao, Yongjun Xu
0
0
Contrastive Language-Image Pre-training (CLIP) has become a promising language-supervised visual pre-training framework. This paper aims to distill small CLIP models supervised by a large teacher CLIP model. We propose several distillation strategies, including relation, feature, gradient and contrastive paradigms, to examine the effectiveness of CLIP-Knowledge Distillation (KD). We show that a simple feature mimicry with Mean Squared Error loss works surprisingly well. Moreover, interactive contrastive learning across teacher and student encoders is also effective in performance improvement. We explain that the success of CLIP-KD can be attributed to maximizing the feature similarity between teacher and student. The unified method is applied to distill several student models trained on CC3M+12M. CLIP-KD improves student CLIP models consistently over zero-shot ImageNet classification and cross-modal retrieval benchmarks. When using ViT-L/14 pretrained on Laion-400M as the teacher, CLIP-KD achieves 57.5% and 55.4% zero-shot top-1 ImageNet accuracy over ViT-B/16 and ResNet-50, surpassing the original CLIP without KD by 20.5% and 20.1% margins, respectively. Our code is released on https://github.com/winycg/CLIP-KD.
5/8/2024