Class-relevant Patch Embedding Selection for Few-Shot Image Classification
2405.03722
0
0

Abstract
Effective image classification hinges on discerning relevant features from both foreground and background elements, with the foreground typically holding the critical information. While humans adeptly classify images with limited exposure, artificial neural networks often struggle with feature selection from rare samples. To address this challenge, we propose a novel method for selecting class-relevant patch embeddings. Our approach involves splitting support and query images into patches, encoding them using a pre-trained Vision Transformer (ViT) to obtain class embeddings and patch embeddings, respectively. Subsequently, we filter patch embeddings using class embeddings to retain only the class-relevant ones. For each image, we calculate the similarity between class embedding and each patch embedding, sort the similarity sequence in descending order, and only retain top-ranked patch embeddings. By prioritizing similarity between the class embedding and patch embeddings, we select top-ranked patch embeddings to be fused with class embedding to form a comprehensive image representation, enhancing pattern recognition across instances. Our strategy effectively mitigates the impact of class-irrelevant patch embeddings, yielding improved performance in pre-trained models. Extensive experiments on popular few-shot classification benchmarks demonstrate the simplicity, efficacy, and computational efficiency of our approach, outperforming state-of-the-art baselines under both 5-shot and 1-shot scenarios.
Create account to get full access
Overview
- This paper explores a novel approach to few-shot image classification by selectively embedding class-relevant patch embeddings from Vision Transformer (ViT) models.
- The proposed method, called Class-relevant Patch Embedding Selection (CPES), aims to improve the performance of few-shot learning by focusing on the most informative patch embeddings for each class.
- The research explores the use of patch embedding selection to enhance the few-shot learning capabilities of ViT models, which have shown promise in various computer vision tasks.
Plain English Explanation
In machine learning, "few-shot learning" refers to the ability to learn a new task or classify a new type of image with only a small number of training examples. This is an important challenge, as it can be costly or impractical to gather large datasets for every new task.
The researchers in this paper tackled the problem of few-shot image classification by developing a new technique called Class-relevant Patch Embedding Selection (CPES). The key insight behind CPES is that not all the "patch embeddings" (small, overlapping segments of an image) are equally important for classifying a particular class of images. By selectively focusing on the most relevant patch embeddings for each class, the researchers were able to improve the few-shot learning performance of Vision Transformer (ViT) models.
ViTs are a type of machine learning model that have shown promising results in various computer vision tasks, including few-shot learning. However, the researchers recognized that the standard ViT approach may not be optimal for few-shot learning, as it treats all patch embeddings equally, regardless of their relevance to the target classes.
The CPES method addresses this by learning to identify the most informative patch embeddings for each class and using only those in the few-shot classification task. This helps the model focus on the most distinctive and relevant features of the images, leading to better performance with limited training data.
Technical Explanation
The researchers developed the CPES method to enhance the few-shot learning capabilities of ViT models. The key steps of the CPES approach are:
-
Patch Embedding Extraction: The input image is divided into a grid of overlapping patches, and a ViT is used to extract a feature embedding for each patch.
-
Class-relevant Patch Embedding Selection: A novel class-specific patch embedding selection module is introduced to identify the most relevant patch embeddings for each class. This module learns to assign higher weights to the patch embeddings that are most informative for a particular class, based on the training data.
-
Few-Shot Classification: During the few-shot learning stage, the model uses only the class-relevant patch embeddings selected in the previous step to perform the image classification task, rather than using all patch embeddings equally.
The researchers evaluated the CPES method on several few-shot image classification benchmarks, including mini-ImageNet, tiered-ImageNet, and CIFAR-FS. The results showed that CPES consistently outperformed standard ViT models and other few-shot learning approaches, demonstrating the benefits of selective patch embedding usage for this task.
Critical Analysis
The CPES method presented in this paper is a promising approach to improving the few-shot learning capabilities of ViT models. By focusing on the most informative patch embeddings for each class, the researchers were able to achieve better performance with limited training data.
One potential limitation of the CPES method is that it relies on the assumption that certain patch embeddings are more relevant than others for a given classification task. While this assumption generally holds true, there may be cases where the most relevant features are distributed across multiple patch embeddings or where the relevance of a patch embedding can vary depending on the context.
Additionally, the CPES method may be computationally more expensive than standard ViT models, as it requires an additional module to learn the class-specific patch embedding selection weights. This could be a concern for deployment in resource-constrained environments.
Further research could explore ways to make the CPES method more efficient, such as by incorporating techniques like intra-task mutual attention, simple semantic-aided few-shot learning, or shadow removal. Investigating the generalizability of the CPES approach to other few-shot learning tasks, such as object detection or image ranking, could also be a fruitful area of future research.
Conclusion
The CPES method presented in this paper offers a novel approach to improving the few-shot learning capabilities of ViT models by selectively focusing on the most class-relevant patch embeddings. The results demonstrate the benefits of this selective embedding approach, which could have important implications for building more sample-efficient and adaptable computer vision systems.
While the CPES method has some potential limitations, the underlying idea of leveraging the most informative features for a given task is a promising direction for further research in few-shot learning and other areas of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Intra-task Mutual Attention based Vision Transformer for Few-Shot Learning
Weihao Jiang, Chang Liu, Kun He
0
0
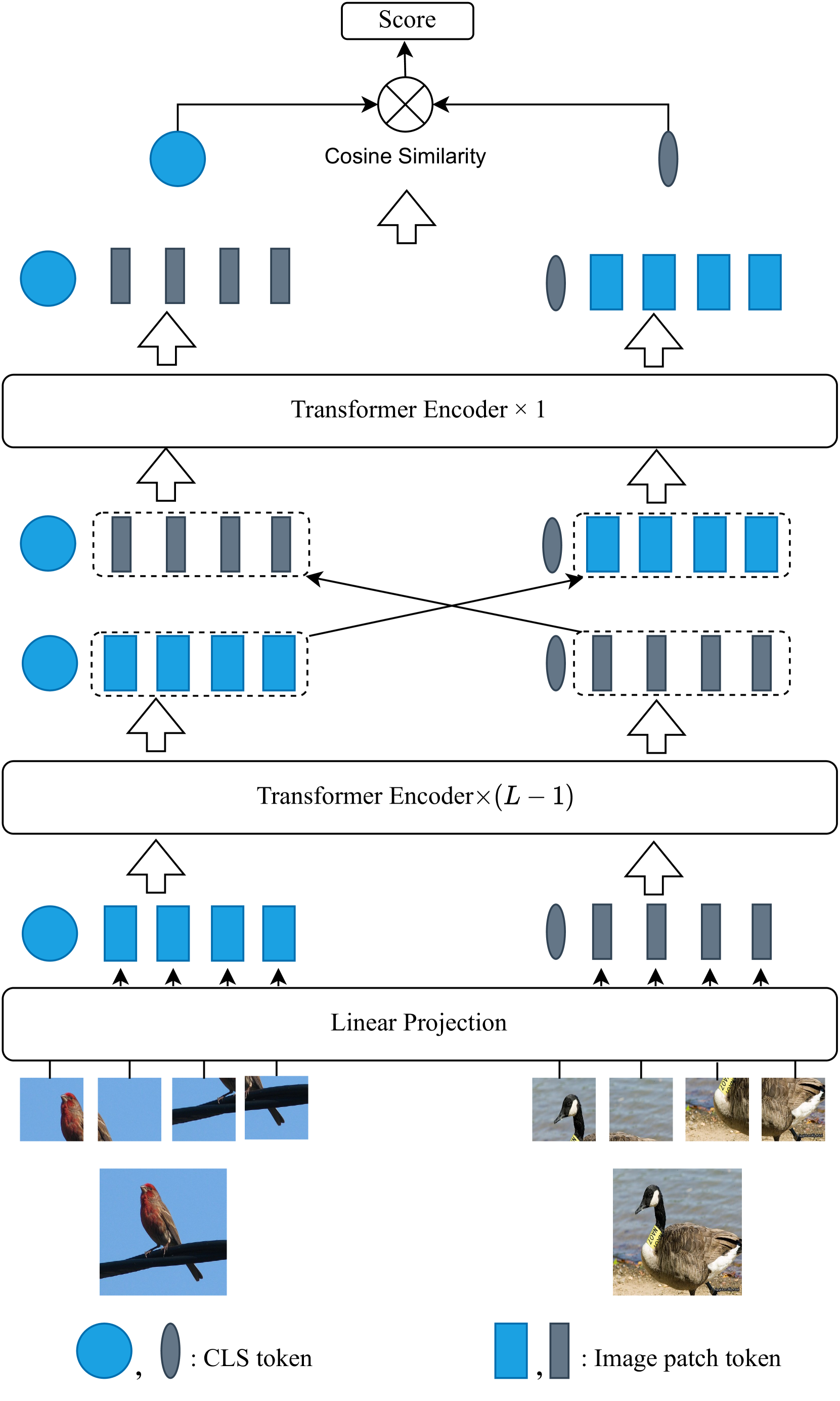
Humans possess remarkable ability to accurately classify new, unseen images after being exposed to only a few examples. Such ability stems from their capacity to identify common features shared between new and previously seen images while disregarding distractions such as background variations. However, for artificial neural network models, determining the most relevant features for distinguishing between two images with limited samples presents a challenge. In this paper, we propose an intra-task mutual attention method for few-shot learning, that involves splitting the support and query samples into patches and encoding them using the pre-trained Vision Transformer (ViT) architecture. Specifically, we swap the class (CLS) token and patch tokens between the support and query sets to have the mutual attention, which enables each set to focus on the most useful information. This facilitates the strengthening of intra-class representations and promotes closer proximity between instances of the same class. For implementation, we adopt the ViT-based network architecture and utilize pre-trained model parameters obtained through self-supervision. By leveraging Masked Image Modeling as a self-supervised training task for pre-training, the pre-trained model yields semantically meaningful representations while successfully avoiding supervision collapse. We then employ a meta-learning method to fine-tune the last several layers and CLS token modules. Our strategy significantly reduces the num- ber of parameters that require fine-tuning while effectively uti- lizing the capability of pre-trained model. Extensive experiments show that our framework is simple, effective and computationally efficient, achieving superior performance as compared to the state-of-the-art baselines on five popular few-shot classification benchmarks under the 5-shot and 1-shot scenarios
5/7/2024
Simple Semantic-Aided Few-Shot Learning
Hai Zhang, Junzhe Xu, Shanlin Jiang, Zhenan He
0
0
Learning from a limited amount of data, namely Few-Shot Learning, stands out as a challenging computer vision task. Several works exploit semantics and design complicated semantic fusion mechanisms to compensate for rare representative features within restricted data. However, relying on naive semantics such as class names introduces biases due to their brevity, while acquiring extensive semantics from external knowledge takes a huge time and effort. This limitation severely constrains the potential of semantics in Few-Shot Learning. In this paper, we design an automatic way called Semantic Evolution to generate high-quality semantics. The incorporation of high-quality semantics alleviates the need for complex network structures and learning algorithms used in previous works. Hence, we employ a simple two-layer network termed Semantic Alignment Network to transform semantics and visual features into robust class prototypes with rich discriminative features for few-shot classification. The experimental results show our framework outperforms all previous methods on six benchmarks, demonstrating a simple network with high-quality semantics can beat intricate multi-modal modules on few-shot classification tasks. Code is available at https://github.com/zhangdoudou123/SemFew.
4/10/2024

A Single Simple Patch is All You Need for AI-generated Image Detection
Jiaxuan Chen, Jieteng Yao, Li Niu
0
0
The recent development of generative models unleashes the potential of generating hyper-realistic fake images. To prevent the malicious usage of fake images, AI-generated image detection aims to distinguish fake images from real images. However, existing method suffer from severe performance drop when detecting images generated by unseen generators. We find that generative models tend to focus on generating the patches with rich textures to make the images more realistic while neglecting the hidden noise caused by camera capture present in simple patches. In this paper, we propose to exploit the noise pattern of a single simple patch to identify fake images. Furthermore, due to the performance decline when handling low-quality generated images, we introduce an enhancement module and a perception module to remove the interfering information. Extensive experiments demonstrate that our method can achieve state-of-the-art performance on public benchmarks.
4/23/2024
Task-oriented Embedding Counts: Heuristic Clustering-driven Feature Fine-tuning for Whole Slide Image Classification
Xuenian Wang, Shanshan Shi, Renao Yan, Qiehe Sun, Lianghui Zhu, Tian Guan, Yonghong He
0
0
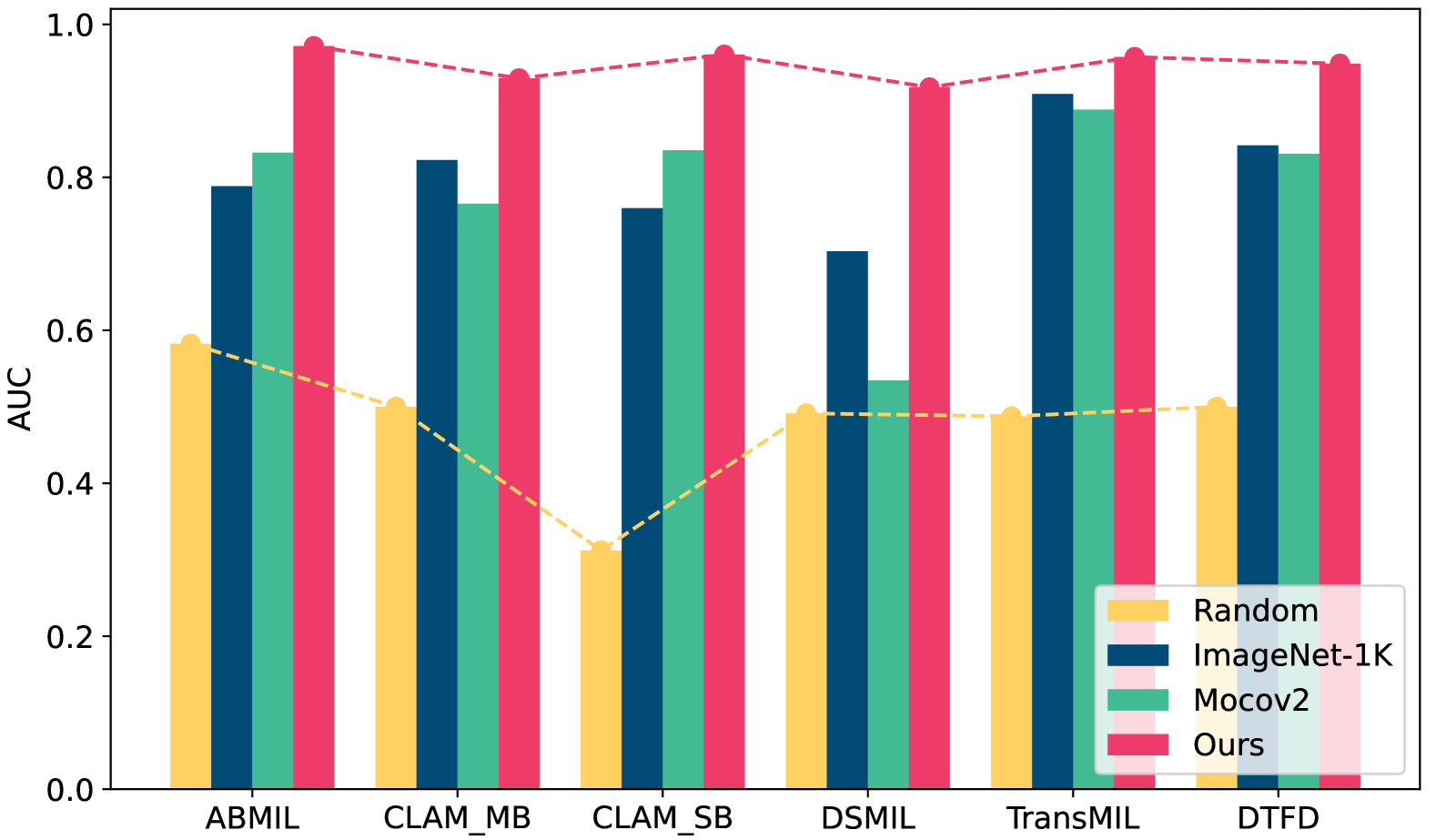
In the field of whole slide image (WSI) classification, multiple instance learning (MIL) serves as a promising approach, commonly decoupled into feature extraction and aggregation. In this paradigm, our observation reveals that discriminative embeddings are crucial for aggregation to the final prediction. Among all feature updating strategies, task-oriented ones can capture characteristics specifically for certain tasks. However, they can be prone to overfitting and contaminated by samples assigned with noisy labels. To address this issue, we propose a heuristic clustering-driven feature fine-tuning method (HC-FT) to enhance the performance of multiple instance learning by providing purified positive and hard negative samples. Our method first employs a well-trained MIL model to evaluate the confidence of patches. Then, patches with high confidence are marked as positive samples, while the remaining patches are used to identify crucial negative samples. After two rounds of heuristic clustering and selection, purified positive and hard negative samples are obtained to facilitate feature fine-tuning. The proposed method is evaluated on both CAMELYON16 and BRACS datasets, achieving an AUC of 97.13% and 85.85%, respectively, consistently outperforming all compared methods.
6/4/2024