Intra-task Mutual Attention based Vision Transformer for Few-Shot Learning
2405.03109
0
0
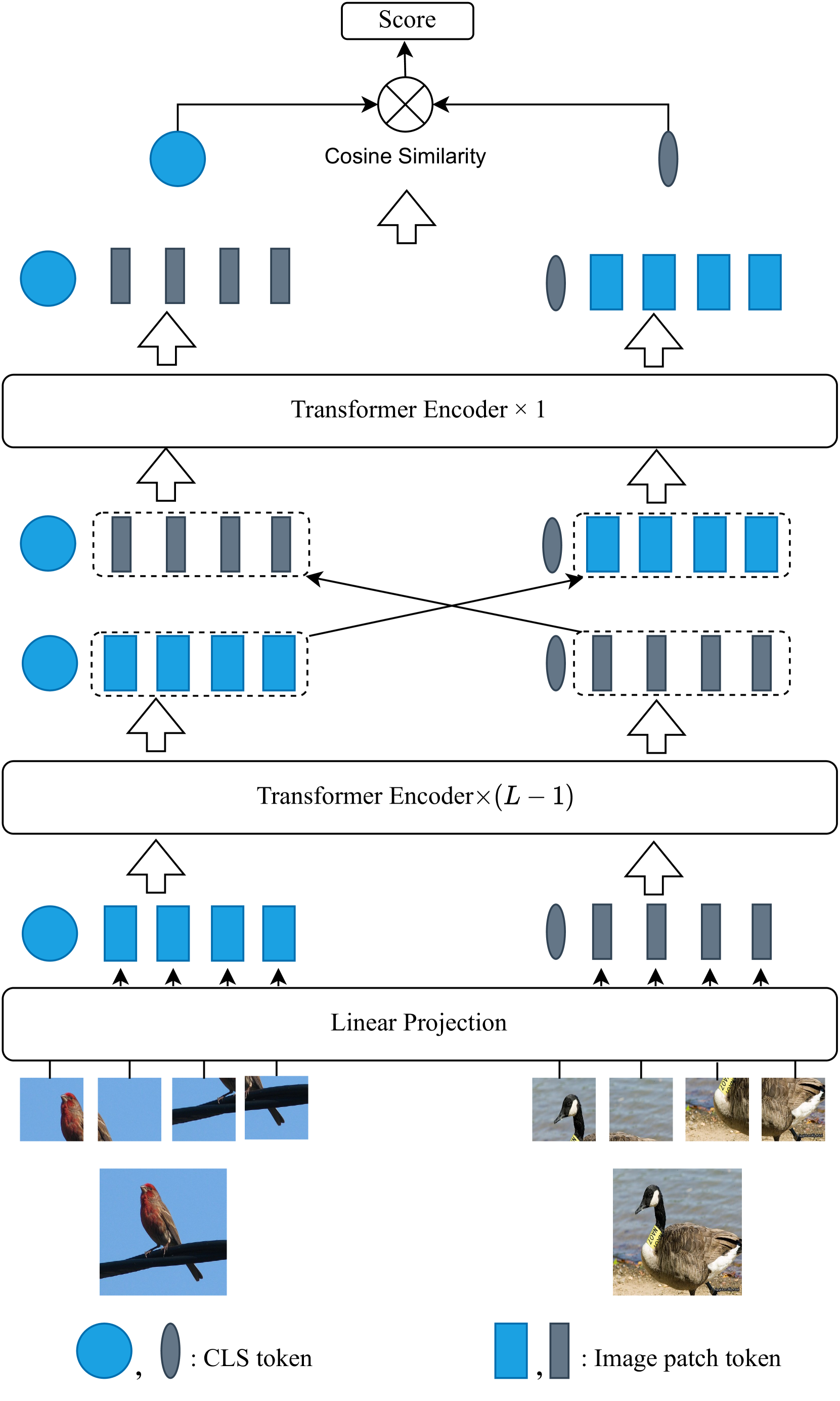
Abstract
Humans possess remarkable ability to accurately classify new, unseen images after being exposed to only a few examples. Such ability stems from their capacity to identify common features shared between new and previously seen images while disregarding distractions such as background variations. However, for artificial neural network models, determining the most relevant features for distinguishing between two images with limited samples presents a challenge. In this paper, we propose an intra-task mutual attention method for few-shot learning, that involves splitting the support and query samples into patches and encoding them using the pre-trained Vision Transformer (ViT) architecture. Specifically, we swap the class (CLS) token and patch tokens between the support and query sets to have the mutual attention, which enables each set to focus on the most useful information. This facilitates the strengthening of intra-class representations and promotes closer proximity between instances of the same class. For implementation, we adopt the ViT-based network architecture and utilize pre-trained model parameters obtained through self-supervision. By leveraging Masked Image Modeling as a self-supervised training task for pre-training, the pre-trained model yields semantically meaningful representations while successfully avoiding supervision collapse. We then employ a meta-learning method to fine-tune the last several layers and CLS token modules. Our strategy significantly reduces the num- ber of parameters that require fine-tuning while effectively uti- lizing the capability of pre-trained model. Extensive experiments show that our framework is simple, effective and computationally efficient, achieving superior performance as compared to the state-of-the-art baselines on five popular few-shot classification benchmarks under the 5-shot and 1-shot scenarios
Create account to get full access
Overview
- This paper proposes an Intra-task Mutual Attention based Vision Transformer (IMAVT) for few-shot learning, a technique that allows machine learning models to quickly adapt to new tasks with limited training data.
- The key idea is to leverage mutual attention between tokens within a task to better capture the task-specific information, which can then be used to rapidly adapt the model to new tasks.
- The authors demonstrate the effectiveness of their approach on several few-shot learning benchmarks, showing improvements over previous state-of-the-art methods.
Plain English Explanation
The paper introduces a new type of vision transformer called the Intra-task Mutual Attention based Vision Transformer (IMAVT) that is designed for few-shot learning. In few-shot learning, the goal is to train a model to perform a new task with only a small amount of example data, rather than requiring a large dataset.
The key innovation in IMAVT is the use of "mutual attention" between the different parts (called "tokens") of the input image. This allows the model to better understand the relationships and interactions between the various elements of the image, which is important for quickly adapting to new tasks.
For example, imagine you're trying to learn to recognize dogs in images with just a few examples. The mutual attention mechanism would help the model discover that certain combinations of ears, eyes, and fur patterns are important indicators of "dog-ness," even if it hasn't seen those exact features before. This allows the model to generalize more effectively to new dog images.
The authors show that IMAVT outperforms previous state-of-the-art methods for few-shot learning on standard benchmark datasets. This suggests their approach of leveraging intra-task mutual attention is a promising direction for building more flexible and sample-efficient machine learning models.
Technical Explanation
The paper introduces the Intra-task Mutual Attention based Vision Transformer (IMAVT) architecture for few-shot learning. IMAVT builds upon the standard vision transformer by incorporating an intra-task mutual attention mechanism.
Typical vision transformers process an image by splitting it into patches and passing them through a series of transformer layers. However, these layers only model the relationships between different patches, not the relationships within each patch (the "intra-task" relationships).
IMAVT addresses this by introducing an additional mutual attention module that computes the relationships between the tokens (patch representations) within each task. This allows the model to better capture the task-specific information, which can then be leveraged for rapid adaptation to new few-shot tasks.
The authors evaluate IMAVT on several few-shot learning benchmarks, including miniImageNet, tieredImageNet, and CIFAR-FS. They show that IMAVT outperforms previous state-of-the-art methods, such as Progressive Semantic-Guided Vision Transformer and Weight-Copy, demonstrating the effectiveness of their intra-task mutual attention approach for few-shot learning.
Critical Analysis
The paper presents a compelling approach to few-shot learning with IMAVT, but there are a few potential limitations and areas for further exploration:
-
Computational Complexity: The addition of the intra-task mutual attention module may increase the computational cost of the model, which could be a concern for real-world deployment, especially on resource-constrained devices. The authors do not provide a detailed analysis of the model's computational complexity.
-
Generalization to Diverse Tasks: The experiments in the paper focus on standard few-shot learning benchmarks, which may not fully represent the diversity of real-world tasks. Further research is needed to understand how well IMAVT generalizes to more heterogeneous few-shot learning scenarios.
-
Interpretability: While the mutual attention mechanism provides a way for the model to capture task-specific relationships, the interpretability of these learned representations is not thoroughly explored. Developing methods to better understand the inner workings of IMAVT could lead to additional insights and improvements.
-
Combination with Other Few-Shot Learning Techniques: The authors do not investigate how IMAVT might be combined with other state-of-the-art few-shot learning approaches, such as meta-learning or data augmentation techniques. Exploring these synergies could lead to even more powerful few-shot learning systems.
Overall, the IMAVT model presents a promising direction for few-shot learning, and the authors' results demonstrate the value of leveraging intra-task mutual attention. Further research addressing the potential limitations could help strengthen the IMAVT approach and expand its applicability to a wider range of few-shot learning challenges.
Conclusion
This paper introduces the Intra-task Mutual Attention based Vision Transformer (IMAVT), a novel architecture for few-shot learning that leverages mutual attention between tokens within a task to capture task-specific information. The authors show that IMAVT outperforms previous state-of-the-art methods on several few-shot learning benchmarks, suggesting that their approach of incorporating intra-task mutual attention is an effective way to build flexible and sample-efficient machine learning models.
While the paper presents a compelling technical contribution, there are a few potential areas for further exploration, such as analyzing the computational complexity, evaluating generalization to diverse tasks, improving interpretability, and investigating synergies with other few-shot learning techniques. Overall, the IMAVT model represents an exciting advancement in the field of few-shot learning and could have significant implications for building more robust and adaptable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

You Only Need Less Attention at Each Stage in Vision Transformers
Shuoxi Zhang, Hanpeng Liu, Stephen Lin, Kun He
0
0
The advent of Vision Transformers (ViTs) marks a substantial paradigm shift in the realm of computer vision. ViTs capture the global information of images through self-attention modules, which perform dot product computations among patchified image tokens. While self-attention modules empower ViTs to capture long-range dependencies, the computational complexity grows quadratically with the number of tokens, which is a major hindrance to the practical application of ViTs. Moreover, the self-attention mechanism in deep ViTs is also susceptible to the attention saturation issue. Accordingly, we argue against the necessity of computing the attention scores in every layer, and we propose the Less-Attention Vision Transformer (LaViT), which computes only a few attention operations at each stage and calculates the subsequent feature alignments in other layers via attention transformations that leverage the previously calculated attention scores. This novel approach can mitigate two primary issues plaguing traditional self-attention modules: the heavy computational burden and attention saturation. Our proposed architecture offers superior efficiency and ease of implementation, merely requiring matrix multiplications that are highly optimized in contemporary deep learning frameworks. Moreover, our architecture demonstrates exceptional performance across various vision tasks including classification, detection and segmentation.
6/4/2024

Class-relevant Patch Embedding Selection for Few-Shot Image Classification
Weihao Jiang, Haoyang Cui, Kun He
0
0
Effective image classification hinges on discerning relevant features from both foreground and background elements, with the foreground typically holding the critical information. While humans adeptly classify images with limited exposure, artificial neural networks often struggle with feature selection from rare samples. To address this challenge, we propose a novel method for selecting class-relevant patch embeddings. Our approach involves splitting support and query images into patches, encoding them using a pre-trained Vision Transformer (ViT) to obtain class embeddings and patch embeddings, respectively. Subsequently, we filter patch embeddings using class embeddings to retain only the class-relevant ones. For each image, we calculate the similarity between class embedding and each patch embedding, sort the similarity sequence in descending order, and only retain top-ranked patch embeddings. By prioritizing similarity between the class embedding and patch embeddings, we select top-ranked patch embeddings to be fused with class embedding to form a comprehensive image representation, enhancing pattern recognition across instances. Our strategy effectively mitigates the impact of class-irrelevant patch embeddings, yielding improved performance in pre-trained models. Extensive experiments on popular few-shot classification benchmarks demonstrate the simplicity, efficacy, and computational efficiency of our approach, outperforming state-of-the-art baselines under both 5-shot and 1-shot scenarios.
5/8/2024
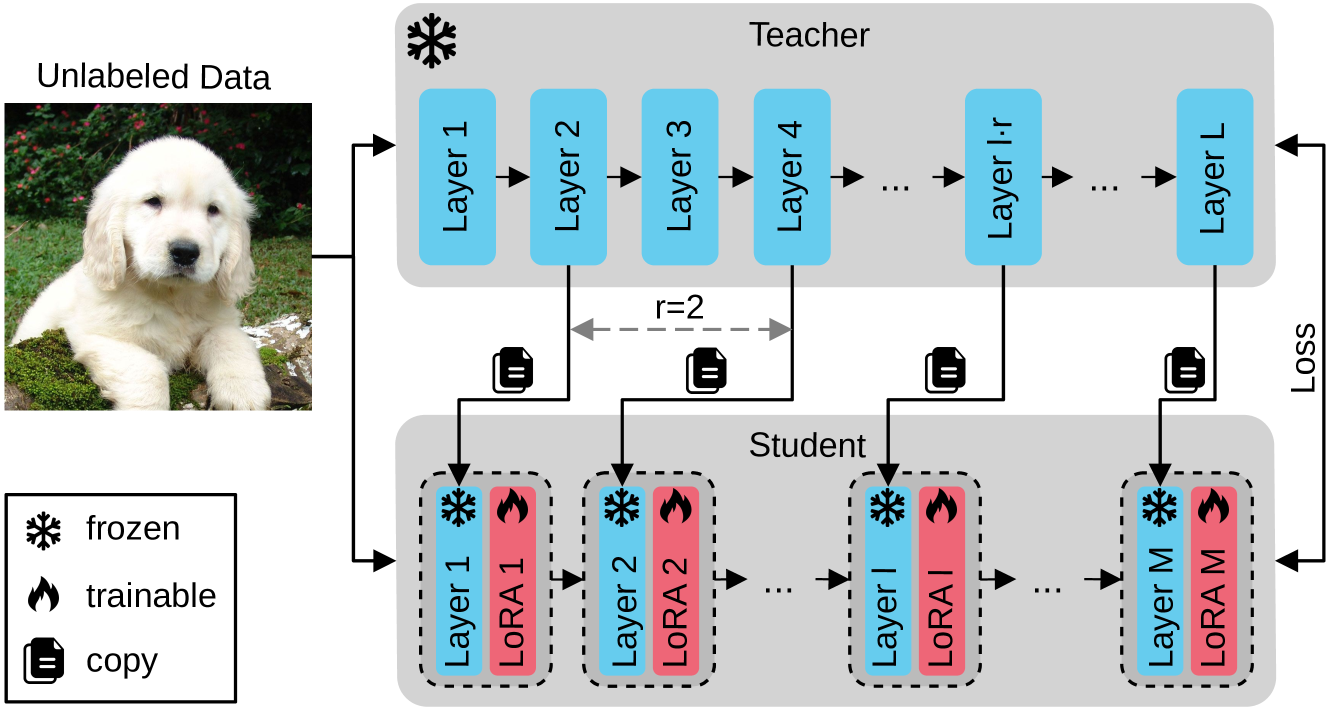
Weight Copy and Low-Rank Adaptation for Few-Shot Distillation of Vision Transformers
Diana-Nicoleta Grigore, Mariana-Iuliana Georgescu, Jon Alvarez Justo, Tor Johansen, Andreea Iuliana Ionescu, Radu Tudor Ionescu
0
0
Few-shot knowledge distillation recently emerged as a viable approach to harness the knowledge of large-scale pre-trained models, using limited data and computational resources. In this paper, we propose a novel few-shot feature distillation approach for vision transformers. Our approach is based on two key steps. Leveraging the fact that vision transformers have a consistent depth-wise structure, we first copy the weights from intermittent layers of existing pre-trained vision transformers (teachers) into shallower architectures (students), where the intermittence factor controls the complexity of the student transformer with respect to its teacher. Next, we employ an enhanced version of Low-Rank Adaptation (LoRA) to distill knowledge into the student in a few-shot scenario, aiming to recover the information processing carried out by the skipped teacher layers. We present comprehensive experiments with supervised and self-supervised transformers as teachers, on five data sets from various domains, including natural, medical and satellite images. The empirical results confirm the superiority of our approach over competitive baselines. Moreover, the ablation results demonstrate the usefulness of each component of the proposed pipeline.
4/16/2024
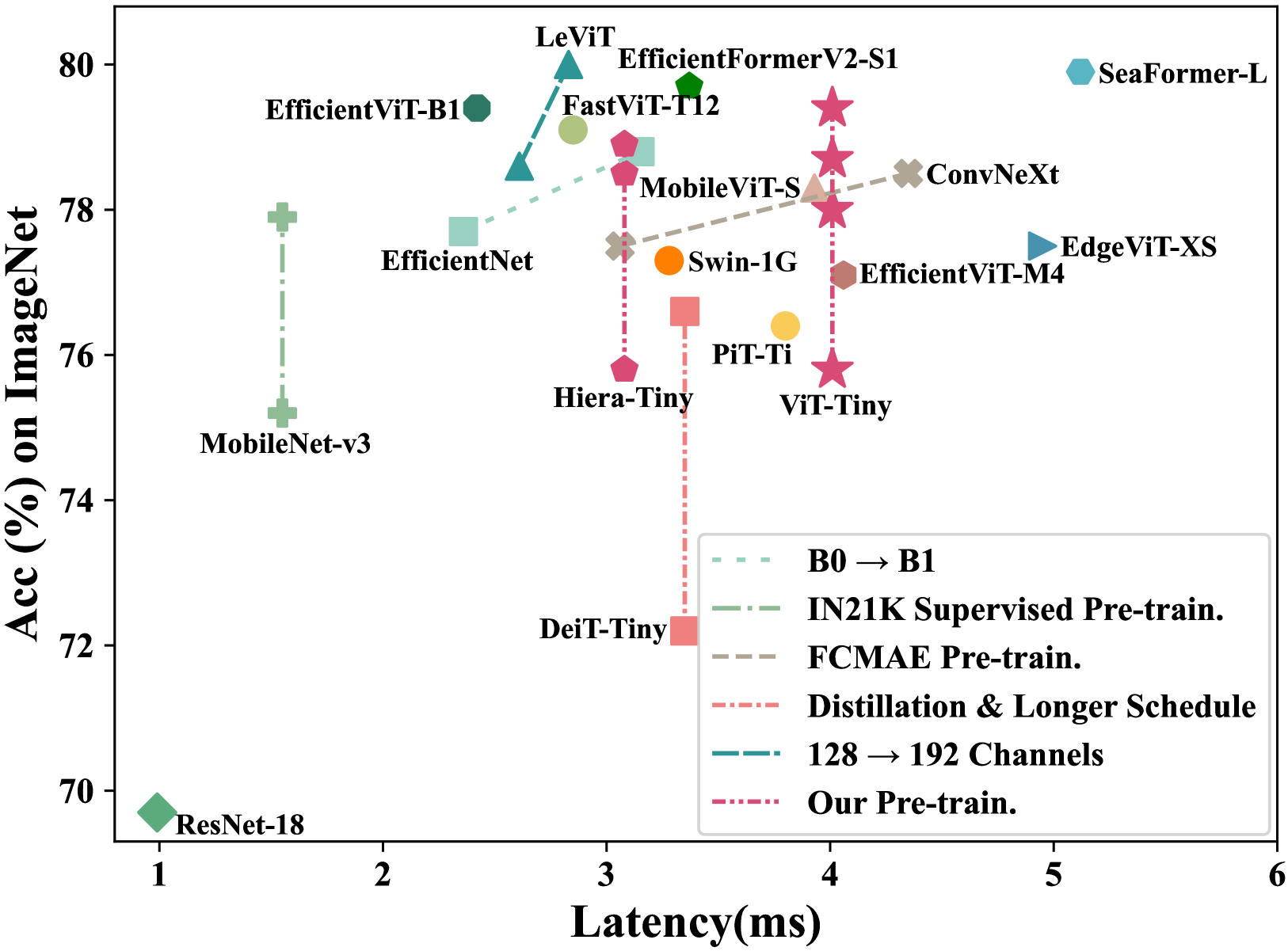
Observation, Analysis, and Solution: Exploring Strong Lightweight Vision Transformers via Masked Image Modeling Pre-Training
Jin Gao, Shubo Lin, Shaoru Wang, Yutong Kou, Zeming Li, Liang Li, Congxuan Zhang, Xiaoqin Zhang, Yizheng Wang, Weiming Hu
0
0
Masked image modeling (MIM) pre-training for large-scale vision transformers (ViTs) has enabled promising downstream performance on top of the learned self-supervised ViT features. In this paper, we question if the textit{extremely simple} lightweight ViTs' fine-tuning performance can also benefit from this pre-training paradigm, which is considerably less studied yet in contrast to the well-established lightweight architecture design methodology. We use an observation-analysis-solution flow for our study. We first systematically observe different behaviors among the evaluated pre-training methods with respect to the downstream fine-tuning data scales. Furthermore, we analyze the layer representation similarities and attention maps across the obtained models, which clearly show the inferior learning of MIM pre-training on higher layers, leading to unsatisfactory transfer performance on data-insufficient downstream tasks. This finding is naturally a guide to designing our distillation strategies during pre-training to solve the above deterioration problem. Extensive experiments have demonstrated the effectiveness of our approach. Our pre-training with distillation on pure lightweight ViTs with vanilla/hierarchical design ($5.7M$/$6.5M$) can achieve $79.4%$/$78.9%$ top-1 accuracy on ImageNet-1K. It also enables SOTA performance on the ADE20K segmentation task ($42.8%$ mIoU) and LaSOT tracking task ($66.1%$ AUC) in the lightweight regime. The latter even surpasses all the current SOTA lightweight CPU-realtime trackers.
5/28/2024