Task-oriented Embedding Counts: Heuristic Clustering-driven Feature Fine-tuning for Whole Slide Image Classification

0
Sign in to get full access
Overview
- Proposes a novel approach called "Task-oriented Embedding Counts" (TOEC) for whole slide image (WSI) classification
- Utilizes heuristic clustering to fine-tune feature representations and improve model performance
- Focuses on addressing challenges in WSI classification, such as high-dimensional data and limited labeled samples
Plain English Explanation
The paper presents a new method called "Task-oriented Embedding Counts" (TOEC) for classifying whole slide images (WSIs), which are high-resolution digital images of biological samples used in medical diagnosis. WSI classification is a challenging task due to the large size and complexity of the images, as well as the limited availability of labeled training data.
The TOEC approach aims to address these challenges by using a heuristic clustering technique to fine-tune the feature representations learned by the model. The key idea is to group similar image regions together and then use this information to refine the model's understanding of the relevant features for the classification task. This allows the model to focus on the most important aspects of the WSIs, leading to improved performance compared to traditional approaches.
The paper demonstrates the effectiveness of TOEC through experiments on several WSI classification datasets, showing that it outperforms other state-of-the-art methods. This suggests that the TOEC approach could be a valuable tool for medical professionals and researchers working with WSIs, helping to improve the accuracy and efficiency of disease diagnosis and research.
Technical Explanation
The TOEC approach builds upon the well-known Multiple Instance Learning (MIL) framework for WSI classification. MIL treats each WSI as a "bag" of smaller image patches, and the model must learn to classify the entire bag based on the features of the individual patches.
The key innovation in TOEC is the use of heuristic clustering to fine-tune the feature representations learned by the model. Specifically, the authors first train a baseline MIL model to obtain an initial set of patch-level features. They then apply a clustering algorithm to group similar patches together, based on their feature representations.
Next, the authors use these cluster assignments to guide the fine-tuning of the model's feature extractor. The intuition is that by focusing on the most relevant features for each cluster, the model can learn a more task-oriented representation that is better suited for the WSI classification task.
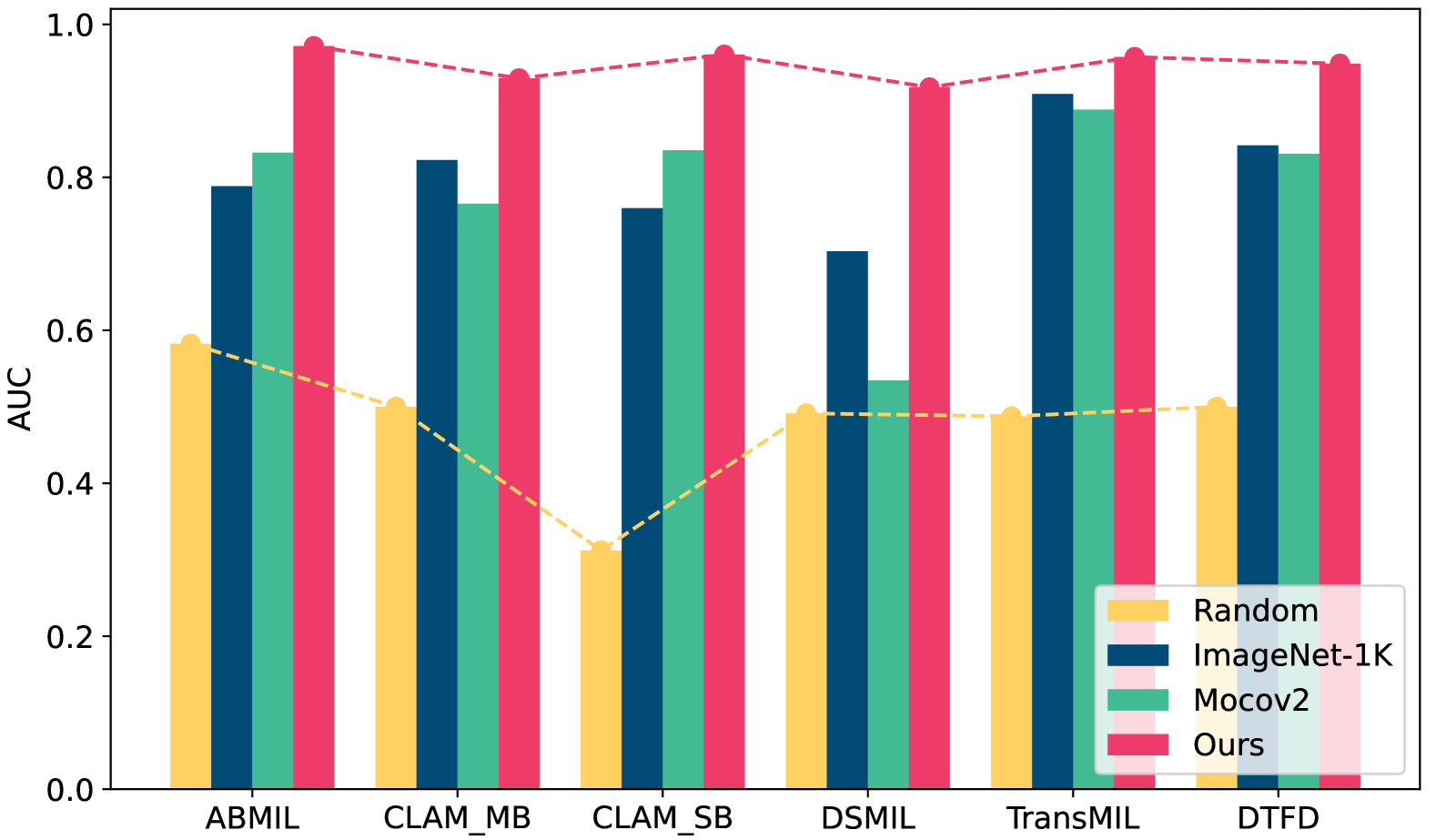
The authors evaluate TOEC on several publicly available WSI datasets, including CAMELYON16, TCGA-BRCA, and BACH. Their results show that TOEC outperforms other state-of-the-art MIL-based approaches, as well as methods that use class-relevant patch embedding selection for few-shot learning.
Critical Analysis
One potential limitation of the TOEC approach is that the choice of clustering algorithm and its hyperparameters may have a significant impact on the performance of the fine-tuned model. The authors acknowledge this and suggest that further research is needed to investigate the sensitivity of TOEC to these choices.
Additionally, the TOEC method relies on the assumption that the initial patch-level features learned by the baseline MIL model are a good starting point for the fine-tuning process. If the baseline features are not sufficiently discriminative, the subsequent fine-tuning may not be as effective. It would be interesting to explore ways of improving the initial feature representation, such as by incorporating attention-based mechanisms or progressive pseudo-bag augmentation.
Despite these potential limitations, the TOEC approach represents an important step forward in addressing the challenges of WSI classification. By leveraging heuristic clustering to fine-tune the model's features, the authors have demonstrated a novel and effective technique that could have significant implications for medical image analysis and diagnosis.
Conclusion
The "Task-oriented Embedding Counts" (TOEC) method proposed in this paper offers a promising solution for whole slide image (WSI) classification, a critical task in medical diagnosis and research. By using heuristic clustering to fine-tune the model's feature representations, TOEC is able to outperform other state-of-the-art approaches on several benchmark datasets.
This work highlights the potential of leveraging the structure and relationships within WSIs to improve model performance, even in the face of high-dimensional data and limited labeled samples. As such, the TOEC approach could have significant impact on the field of medical image analysis, helping to streamline and enhance the accuracy of disease diagnosis and research.
While the method has some potential limitations, the authors have demonstrated the effectiveness of their approach and opened up new avenues for further research and development in this important area of study.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Task-oriented Embedding Counts: Heuristic Clustering-driven Feature Fine-tuning for Whole Slide Image Classification
Xuenian Wang, Shanshan Shi, Renao Yan, Qiehe Sun, Lianghui Zhu, Tian Guan, Yonghong He
In the field of whole slide image (WSI) classification, multiple instance learning (MIL) serves as a promising approach, commonly decoupled into feature extraction and aggregation. In this paradigm, our observation reveals that discriminative embeddings are crucial for aggregation to the final prediction. Among all feature updating strategies, task-oriented ones can capture characteristics specifically for certain tasks. However, they can be prone to overfitting and contaminated by samples assigned with noisy labels. To address this issue, we propose a heuristic clustering-driven feature fine-tuning method (HC-FT) to enhance the performance of multiple instance learning by providing purified positive and hard negative samples. Our method first employs a well-trained MIL model to evaluate the confidence of patches. Then, patches with high confidence are marked as positive samples, while the remaining patches are used to identify crucial negative samples. After two rounds of heuristic clustering and selection, purified positive and hard negative samples are obtained to facilitate feature fine-tuning. The proposed method is evaluated on both CAMELYON16 and BRACS datasets, achieving an AUC of 97.13% and 85.85%, respectively, consistently outperforming all compared methods.
Read more6/4/2024

0
New!Hard Negative Sample Mining for Whole Slide Image Classification
Wentao Huang, Xiaoling Hu, Shahira Abousamra, Prateek Prasanna, Chao Chen
Weakly supervised whole slide image (WSI) classification is challenging due to the lack of patch-level labels and high computational costs. State-of-the-art methods use self-supervised patch-wise feature representations for multiple instance learning (MIL). Recently, methods have been proposed to fine-tune the feature representation on the downstream task using pseudo labeling, but mostly focusing on selecting high-quality positive patches. In this paper, we propose to mine hard negative samples during fine-tuning. This allows us to obtain better feature representations and reduce the training cost. Furthermore, we propose a novel patch-wise ranking loss in MIL to better exploit these hard negative samples. Experiments on two public datasets demonstrate the efficacy of these proposed ideas. Our codes are available at https://github.com/winston52/HNM-WSI
Read more10/4/2024

0
Rethinking Multiple Instance Learning for Whole Slide Image Classification: A Good Instance Classifier is All You Need
Linhao Qu, Yingfan Ma, Xiaoyuan Luo, Manning Wang, Zhijian Song
Weakly supervised whole slide image classification is usually formulated as a multiple instance learning (MIL) problem, where each slide is treated as a bag, and the patches cut out of it are treated as instances. Existing methods either train an instance classifier through pseudo-labeling or aggregate instance features into a bag feature through attention mechanisms and then train a bag classifier, where the attention scores can be used for instance-level classification. However, the pseudo instance labels constructed by the former usually contain a lot of noise, and the attention scores constructed by the latter are not accurate enough, both of which affect their performance. In this paper, we propose an instance-level MIL framework based on contrastive learning and prototype learning to effectively accomplish both instance classification and bag classification tasks. To this end, we propose an instance-level weakly supervised contrastive learning algorithm for the first time under the MIL setting to effectively learn instance feature representation. We also propose an accurate pseudo label generation method through prototype learning. We then develop a joint training strategy for weakly supervised contrastive learning, prototype learning, and instance classifier training. Extensive experiments and visualizations on four datasets demonstrate the powerful performance of our method. Codes are available at https://github.com/miccaiif/INS.
Read more5/14/2024
🖼️
0
Distilling High Diagnostic Value Patches for Whole Slide Image Classification Using Attention Mechanism
Tianhang Nan, Hao Quan, Yong Ding, Xingyu Li, Kai Yang, Xiaoyu Cui
Multiple Instance Learning (MIL) has garnered widespread attention in the field of Whole Slide Image (WSI) classification as it replaces pixel-level manual annotation with diagnostic reports as labels, significantly reducing labor costs. Recent research has shown that bag-level MIL methods often yield better results because they can consider all patches of the WSI as a whole. However, a drawback of such methods is the incorporation of more redundant patches, leading to interference. To extract patches with high diagnostic value while excluding interfering patches to address this issue, we developed an attention-based feature distillation multi-instance learning (AFD-MIL) approach. This approach proposed the exclusion of redundant patches as a preprocessing operation in weakly supervised learning, directly mitigating interference from extensive noise. It also pioneers the use of attention mechanisms to distill features with high diagnostic value, as opposed to the traditional practice of indiscriminately and forcibly integrating all patches. Additionally, we introduced global loss optimization to finely control the feature distillation module. AFD-MIL is orthogonal to many existing MIL methods, leading to consistent performance improvements. This approach has surpassed the current state-of-the-art method, achieving 91.47% ACC (accuracy) and 94.29% AUC (area under the curve) on the Camelyon16 (Camelyon Challenge 2016, breast cancer), while 93.33% ACC and 98.17% AUC on the TCGA-NSCLC (The Cancer Genome Atlas Program: non-small cell lung cancer). Different feature distillation methods were used for the two datasets, tailored to the specific diseases, thereby improving performance and interpretability.
Read more8/19/2024