Classic GNNs are Strong Baselines: Reassessing GNNs for Node Classification

0
🏷️
Sign in to get full access
Overview
- The research paper "Classic GNNs are Strong Baselines: Reassessing GNNs for Node Classification" challenges the common perception that recent, complex Graph Neural Network (GNN) models consistently outperform classic GNN baselines on node classification tasks.
- The authors show that with proper hyperparameter tuning, classic GNNs can achieve comparable or even superior performance to more advanced GNN models across a range of node classification benchmarks.
- This paper has important implications for the direction of GNN research, as it suggests that the focus should be on improving fundamental GNN architectures rather than introducing new, overly complex models.
Plain English Explanation
The paper looks at a common type of machine learning model called Graph Neural Networks (GNNs), which are used to analyze data that is organized in a graph format. Graphs are made up of nodes (like individual data points) that are connected by edges (like the relationships between data points).
GNNs have become very popular in recent years, with researchers constantly developing new, more complex versions of these models. However, this paper argues that the older, more basic GNN models are actually still very good at the task of classifying the individual nodes in a graph.
The authors show that if you carefully tune the hyperparameters (the settings) of these classic GNN models, they can actually perform just as well, or even better, than the newer, more complicated GNN models. This is an important finding because it suggests that the focus of GNN research should be on improving the fundamental GNN architectures, rather than constantly creating new, more complex models.
Technical Explanation
The paper examines the performance of classic GNN models, such as Graph Convolutional Networks (GCNs) and Graph Attention Networks (GATs), on node classification tasks. The authors conduct extensive experiments across multiple benchmark datasets, carefully tuning the hyperparameters of the classic GNN models.
Their results show that with proper hyperparameter optimization, classic GNNs are able to achieve comparable or even superior performance to more recent, complex GNN models, such as Dynamic Graph Neural Networks and Hyperbolic GNNs. The authors also demonstrate that classic GNNs are more robust to changes in graph structure and node features compared to more advanced models.
These findings challenge the common perception in the field that newer, more complex GNN architectures are always better. The authors argue that the focus of GNN research should shift towards improving the core GNN building blocks, rather than constantly introducing new, overly complex models.
Critical Analysis
The paper makes a compelling case for re-evaluating the role of classic GNN models in node classification tasks. The authors' rigorous experimental design and extensive comparisons across multiple datasets and benchmarks lend credibility to their findings.
However, the paper does not delve into the potential limitations or caveats of their approach. For example, it would be interesting to see how the classic GNN models perform on larger, more complex graphs or in the presence of noisy or incomplete data. Additionally, the paper does not explore the trade-offs between the simplicity of classic GNNs and the representational power of more advanced models.
Furthermore, the paper could have benefited from a deeper discussion of the implications of their findings for the broader GNN research community. The authors briefly mention the need to focus on improving fundamental GNN architectures, but more details on specific research directions or potential avenues for innovation would have been valuable.
Despite these minor shortcomings, the paper makes a significant contribution to the field of graph representation learning by challenging the prevailing narrative and encouraging researchers to think critically about the role of classic GNN models in node classification tasks.
Conclusion
This paper provides a timely and important re-evaluation of the performance of classic GNN models for node classification tasks. By demonstrating that with proper hyperparameter tuning, classic GNNs can match or even outperform more advanced GNN architectures, the authors challenge the common perception that newer models are always better.
The findings in this paper have important implications for the direction of GNN research, as they suggest that the focus should be on improving the fundamental GNN building blocks rather than constantly introducing new, complex models. This shift in focus could lead to more robust, efficient, and interpretable GNN-based solutions for a wide range of real-world problems.
Overall, this paper serves as a valuable reminder to the research community to continuously re-assess our assumptions and evaluate the performance of both classic and state-of-the-art approaches, ultimately driving the field of graph representation learning forward in a more sustainable and impactful way.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
0
Classic GNNs are Strong Baselines: Reassessing GNNs for Node Classification
Yuankai Luo, Lei Shi, Xiao-Ming Wu
Graph Transformers (GTs) have recently emerged as popular alternatives to traditional message-passing Graph Neural Networks (GNNs), due to their theoretically superior expressiveness and impressive performance reported on standard node classification benchmarks, often significantly outperforming GNNs. In this paper, we conduct a thorough empirical analysis to reevaluate the performance of three classic GNN models (GCN, GAT, and GraphSAGE) against GTs. Our findings suggest that the previously reported superiority of GTs may have been overstated due to suboptimal hyperparameter configurations in GNNs. Remarkably, with slight hyperparameter tuning, these classic GNN models achieve state-of-the-art performance, matching or even exceeding that of recent GTs across 17 out of the 18 diverse datasets examined. Additionally, we conduct detailed ablation studies to investigate the influence of various GNN configurations, such as normalization, dropout, residual connections, network depth, and jumping knowledge mode, on node classification performance. Our study aims to promote a higher standard of empirical rigor in the field of graph machine learning, encouraging more accurate comparisons and evaluations of model capabilities.
Read more6/14/2024
0
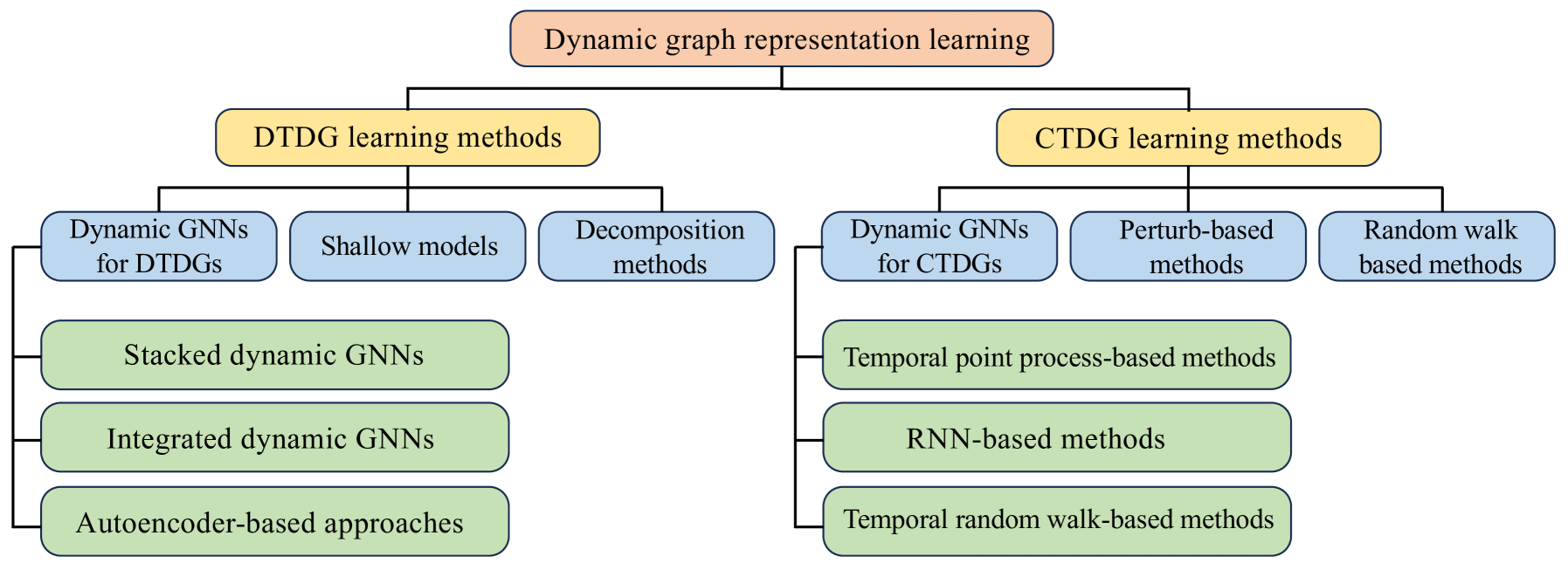
A survey of dynamic graph neural networks
Yanping Zheng, Lu Yi, Zhewei Wei
Graph neural networks (GNNs) have emerged as a powerful tool for effectively mining and learning from graph-structured data, with applications spanning numerous domains. However, most research focuses on static graphs, neglecting the dynamic nature of real-world networks where topologies and attributes evolve over time. By integrating sequence modeling modules into traditional GNN architectures, dynamic GNNs aim to bridge this gap, capturing the inherent temporal dependencies of dynamic graphs for a more authentic depiction of complex networks. This paper provides a comprehensive review of the fundamental concepts, key techniques, and state-of-the-art dynamic GNN models. We present the mainstream dynamic GNN models in detail and categorize models based on how temporal information is incorporated. We also discuss large-scale dynamic GNNs and pre-training techniques. Although dynamic GNNs have shown superior performance, challenges remain in scalability, handling heterogeneous information, and lack of diverse graph datasets. The paper also discusses possible future directions, such as adaptive and memory-enhanced models, inductive learning, and theoretical analysis.
Read more4/30/2024

0
Graph neural network surrogate for strategic transport planning
Nikita Makarov, Santhanakrishnan Narayanan, Constantinos Antoniou
As the complexities of urban environments continue to grow, the modelling of transportation systems become increasingly challenging. This paper explores the application of advanced Graph Neural Network (GNN) architectures as surrogate models for strategic transport planning. Building upon a prior work that laid the foundation with graph convolution networks (GCN), our study delves into the comparative analysis of established GCN with the more expressive Graph Attention Network (GAT). Additionally, we propose a novel GAT variant (namely GATv3) to address over-smoothing issues in graph-based models. Our investigation also includes the exploration of a hybrid model combining both GCN and GAT architectures, aiming to investigate the performance of the mixture. The three models are applied to various experiments to understand their limits. We analyse hierarchical regression setups, combining classification and regression tasks, and introduce fine-grained classification with a proposal of a method to convert outputs to precise values. Results reveal the superior performance of the new GAT in classification tasks. To the best of the authors' knowledge, this is the first GAT model in literature to achieve larger depths. Surprisingly, the fine-grained classification task demonstrates the GCN's unexpected dominance with additional training data. This shows that synthetic data generators can increase the training data, without overfitting issues whilst improving model performance. In conclusion, this research advances GNN based surrogate modelling, providing insights for refining GNN architectures. The findings open avenues for investigating the potential of the newly proposed GAT architecture and the modelling setups for other transportation problems.
Read more8/16/2024

0
On the Topology Awareness and Generalization Performance of Graph Neural Networks
Junwei Su, Chuan Wu
Many computer vision and machine learning problems are modelled as learning tasks on graphs where graph neural networks GNNs have emerged as a dominant tool for learning representations of graph structured data A key feature of GNNs is their use of graph structures as input enabling them to exploit the graphs inherent topological properties known as the topology awareness of GNNs Despite the empirical successes of GNNs the influence of topology awareness on generalization performance remains unexplored, particularly for node level tasks that diverge from the assumption of data being independent and identically distributed IID The precise definition and characterization of the topology awareness of GNNs especially concerning different topological features are still unclear This paper introduces a comprehensive framework to characterize the topology awareness of GNNs across any topological feature Using this framework we investigate the effects of topology awareness on GNN generalization performance Contrary to the prevailing belief that enhancing the topology awareness of GNNs is always advantageous our analysis reveals a critical insight improving the topology awareness of GNNs may inadvertently lead to unfair generalization across structural groups which might not be desired in some scenarios Additionally we conduct a case study using the intrinsic graph metric the shortest path distance on various benchmark datasets The empirical results of this case study confirm our theoretical insights Moreover we demonstrate the practical applicability of our framework by using it to tackle the cold start problem in graph active learning
Read more7/9/2024