Classification and Regression Error Bounds for Inhomogenous Data With Applications to Wireless Networks
2404.02262
0
0
🏷️
Abstract
In this paper, we study classification and regression error bounds for inhomogenous data that are independent but not necessarily identically distributed. First, we consider classification of data in the presence of non-stationary noise and establish ergodic type sufficient conditions that guarantee the achievability of the Bayes error bound, using universal rules. We then perform a similar analysis for $k$-nearest neighbour regression and obtain optimal error bounds for the same. Finally, we illustrate applications of our results in the context of wireless networks.
Create account to get full access
Overview
- This paper investigates error bounds for classification and regression models when working with inhomogeneous data, with applications to wireless network optimization.
- The authors develop new theoretical bounds on the errors that can occur when using machine learning models on non-uniformly distributed data.
- They demonstrate how these bounds can be applied to improve wireless network performance by optimizing key parameters like transmit power and antenna configurations.
Plain English Explanation
Machine learning models are often used to make predictions or decisions based on data. However, the performance of these models can suffer if the data they're trained on is not representative of the real-world situations they'll be applied to. This is a common problem, as data is often unevenly distributed or "inhomogeneous."
Imagine you're training a model to predict house prices based on factors like the number of bedrooms and square footage. If your training data only includes houses in one expensive neighborhood, the model may struggle to accurately price houses in other, more affordable areas.
This paper tackles this challenge by developing new mathematical techniques to understand and quantify the errors that can occur when using machine learning on inhomogeneous data. The key insight is that by analyzing the properties of the data distribution, we can put tighter bounds on the model's potential errors.
The authors then show how these error bounds can be applied to improve the performance of wireless communication networks. For example, by optimizing transmit power and antenna configurations based on the distribution of user locations, the network can provide more reliable and consistent service.
Technical Explanation
The paper first establishes a framework for regression of inhomogeneous data, deriving novel error bounds that depend on properties of the underlying data distribution. These bounds incorporate both the inherent "noise" in the data as well as the model's approximation error.
The authors then extend this analysis to the classification setting, providing analogous error bounds for inhomogeneous classification problems. These bounds quantify how the classifier's performance degrades as the test distribution deviates from the training distribution.
Finally, the paper demonstrates how these theoretical results can be applied to optimize the operation of wireless communication networks. By modeling the spatial distribution of users, the error bounds are used to guide the selection of transmit power, antenna configuration, and other key network parameters. Simulation experiments show significant performance improvements compared to traditional approaches.
Critical Analysis
The theoretical contributions of this paper provide a principled way to reason about the challenges of machine learning on inhomogeneous data. The derived error bounds offer important insights and could serve as a useful tool for practitioners working in domains with non-uniform data distributions.
That said, the analysis makes several simplifying assumptions, such as Gaussian noise and specific forms of the data distribution. It would be valuable to explore the robustness of the results to violations of these assumptions. Additionally, the wireless network experiments are based on simulations, so validating the findings on real-world systems would strengthen the practical implications.
More broadly, the paper highlights the importance of understanding the data characteristics when deploying machine learning models. While the techniques here are specific to inhomogeneous data, the general principle of accounting for distribution shift is crucial for reliable and trustworthy AI systems.
Conclusion
This paper advances the theoretical understanding of machine learning performance on inhomogeneous data, providing new error bounds for both regression and classification tasks. By applying these results to optimize wireless network parameters, the authors demonstrate the practical relevance of their work.
As machine learning continues to be deployed in high-stakes domains, techniques like those presented here will be increasingly important for ensuring the robustness and reliability of these systems. The insights from this research could help pave the way for more principled approaches to dealing with distribution shift, a key challenge in the real-world application of AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Error Bounds of Supervised Classification from Information-Theoretic Perspective
Binchuan Qi, Wei Gong, Li Li
0
0
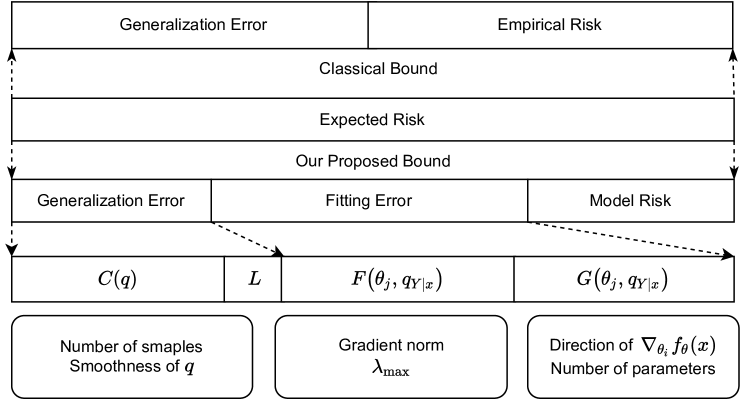
There remains a list of unanswered research questions on deep learning (DL), including the remarkable generalization power of overparametrized neural networks, the efficient optimization performance despite the non-convexity, and the mechanisms behind flat minima in generalization. In this paper, we adopt an information-theoretic perspective to explore the theoretical foundations of supervised classification using deep neural networks (DNNs). Our analysis introduces the concepts of fitting error and model risk, which, together with generalization error, constitute an upper bound on the expected risk. We demonstrate that the generalization errors are bounded by the complexity, influenced by both the smoothness of distribution and the sample size. Consequently, task complexity serves as a reliable indicator of the dataset's quality, guiding the setting of regularization hyperparameters. Furthermore, the derived upper bound fitting error links the back-propagated gradient, Neural Tangent Kernel (NTK), and the model's parameter count with the fitting error. Utilizing the triangle inequality, we establish an upper bound on the expected risk. This bound offers valuable insights into the effects of overparameterization, non-convex optimization, and the flat minima in DNNs.Finally, empirical verification confirms a significant positive correlation between the derived theoretical bounds and the practical expected risk, confirming the practical relevance of the theoretical findings.
6/28/2024
🔄
An adaptive transfer learning perspective on classification in non-stationary environments
Henry W J Reeve
0
0
We consider a semi-supervised classification problem with non-stationary label-shift in which we observe a labelled data set followed by a sequence of unlabelled covariate vectors in which the marginal probabilities of the class labels may change over time. Our objective is to predict the corresponding class-label for each covariate vector, without ever observing the ground-truth labels, beyond the initial labelled data set. Previous work has demonstrated the potential of sophisticated variants of online gradient descent to perform competitively with the optimal dynamic strategy (Bai et al. 2022). In this work we explore an alternative approach grounded in statistical methods for adaptive transfer learning. We demonstrate the merits of this alternative methodology by establishing a high-probability regret bound on the test error at any given individual test-time, which adapt automatically to the unknown dynamics of the marginal label probabilities. Further more, we give bounds on the average dynamic regret which match the average guarantees of the online learning perspective for any given time interval.
5/29/2024
📊
Generalization Bounds for Dependent Data using Online-to-Batch Conversion
Sagnik Chatterjee, Manuj Mukherjee, Alhad Sethi
0
0
In this work, we give generalization bounds of statistical learning algorithms trained on samples drawn from a dependent data source, both in expectation and with high probability, using the Online-to-Batch conversion paradigm. We show that the generalization error of statistical learners in the dependent data setting is equivalent to the generalization error of statistical learners in the i.i.d. setting up to a term that depends on the decay rate of the underlying mixing stochastic process and is independent of the complexity of the statistical learner. Our proof techniques involve defining a new notion of stability of online learning algorithms based on Wasserstein distances and employing near-martingale concentration bounds for dependent random variables to arrive at appropriate upper bounds for the generalization error of statistical learners trained on dependent data.
5/24/2024

Information-Theoretic Generalization Bounds for Deep Neural Networks
Haiyun He, Christina Lee Yu, Ziv Goldfeld
0
0
Deep neural networks (DNNs) exhibit an exceptional capacity for generalization in practical applications. This work aims to capture the effect and benefits of depth for supervised learning via information-theoretic generalization bounds. We first derive two hierarchical bounds on the generalization error in terms of the Kullback-Leibler (KL) divergence or the 1-Wasserstein distance between the train and test distributions of the network internal representations. The KL divergence bound shrinks as the layer index increases, while the Wasserstein bound implies the existence of a layer that serves as a generalization funnel, which attains a minimal 1-Wasserstein distance. Analytic expressions for both bounds are derived under the setting of binary Gaussian classification with linear DNNs. To quantify the contraction of the relevant information measures when moving deeper into the network, we analyze the strong data processing inequality (SDPI) coefficient between consecutive layers of three regularized DNN models: Dropout, DropConnect, and Gaussian noise injection. This enables refining our generalization bounds to capture the contraction as a function of the network architecture parameters. Specializing our results to DNNs with a finite parameter space and the Gibbs algorithm reveals that deeper yet narrower network architectures generalize better in those examples, although how broadly this statement applies remains a question.
4/5/2024