CLEME2.0: Towards More Interpretable Evaluation by Disentangling Edits for Grammatical Error Correction

0

Sign in to get full access
Overview
• This paper introduces CLEME2.0, a new evaluation method for Grammatical Error Correction (GEC) systems that aims to provide more interpretable and disentangled assessments.
• GEC systems are AI models that can identify and correct grammatical errors in text, but evaluating their performance has been challenging. CLEME2.0 addresses this by breaking down the evaluation into separate components that measure different aspects of the GEC process.
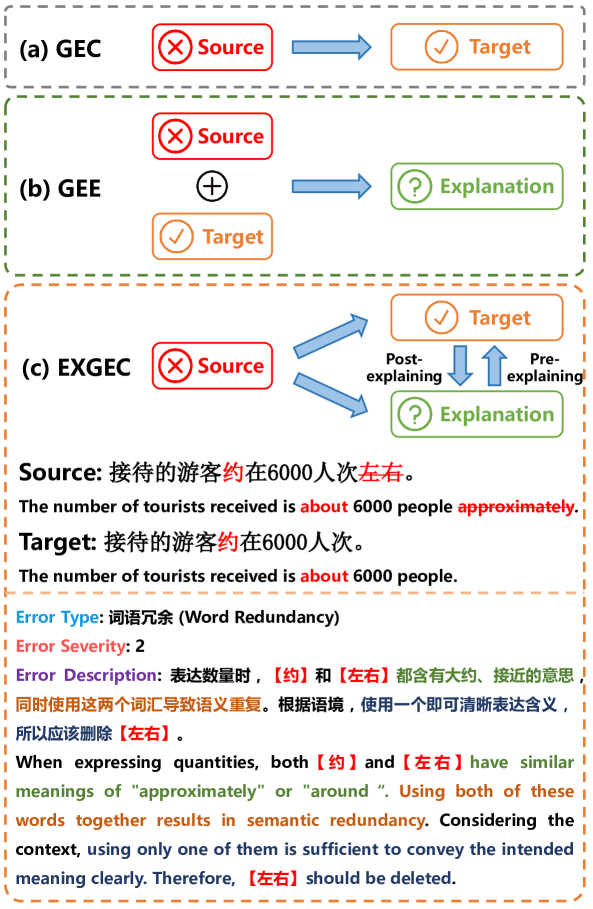
• The paper also describes a new GEC dataset, EXCGEC, which is designed to support the CLEME2.0 evaluation approach by providing more granular information about the types of errors present in the text.
Plain English Explanation
Grammatical Error Correction (GEC) is a task where AI models try to identify and fix mistakes in written text, such as incorrect grammar, spelling, or word choice. Evaluating the performance of these GEC models has been tricky because it's hard to pinpoint exactly where the models are succeeding or failing.
The researchers behind this paper have come up with a new evaluation method called CLEME2.0 that aims to provide a more detailed and interpretable assessment of GEC models. Instead of just giving an overall score, CLEME2.0 breaks down the evaluation into separate components that measure different aspects of the GEC process, like how well the model can detect errors, how well it can suggest corrections, and how the corrections impact the overall quality of the text.
To support this new evaluation approach, the researchers also created a new GEC dataset called EXCGEC. This dataset includes more detailed information about the types of errors present in the text, which allows the CLEME2.0 evaluation to be even more granular and insightful.
By disentangling the different components of GEC performance, CLEME2.0 and the EXCGEC dataset provide a more comprehensive and interpretable way to assess the strengths and weaknesses of GEC models. This can help researchers and developers better understand how to improve these models and make them more effective.
Technical Explanation
The paper introduces CLEME2.0, a new evaluation framework for Grammatical Error Correction (GEC) systems that aims to provide more interpretable and disentangled assessments. Unlike traditional GEC evaluations that focus on overall performance metrics, CLEME2.0 breaks down the evaluation into separate components that measure different aspects of the GEC process, such as error detection, error correction, and the impact of corrections on overall text quality.
To support this new evaluation approach, the researchers also present a new GEC dataset called EXCGEC, which includes detailed annotations about the types of errors present in the text. This allows the CLEME2.0 evaluation to provide a more granular analysis of GEC model performance.
The paper also discusses how the CLEME2.0 framework can be used to better understand the strengths and weaknesses of GEC models, and how it can inform the development of more effective GEC systems. The authors highlight how this approach can lead to more interpretable and actionable insights compared to traditional GEC evaluation methods.
Critical Analysis
The CLEME2.0 evaluation framework and the EXCGEC dataset represent a significant advancement in GEC model assessment, as they provide a more comprehensive and nuanced way to analyze model performance. By disentangling the different components of the GEC process, researchers and developers can gain valuable insights into the specific areas where their models excel or struggle.
However, the paper acknowledges that the CLEME2.0 evaluation is more complex and time-consuming than traditional GEC assessments, which may limit its practical adoption. Additionally, the EXCGEC dataset is currently limited in size and scope, and the researchers note that further work is needed to expand and diversify the dataset to make it more representative of real-world GEC scenarios.
Another potential limitation is that the CLEME2.0 framework still relies on human-annotated data for evaluation, which can introduce biases and inconsistencies. Exploring ways to automate the evaluation process or incorporate more objective measures of text quality could help address this issue and further improve the interpretability and reliability of the assessment.
Conclusion
The CLEME2.0 evaluation framework and the EXCGEC dataset represent an important step forward in the assessment of Grammatical Error Correction systems. By providing a more granular and interpretable evaluation approach, these tools can help researchers and developers better understand the strengths and weaknesses of their GEC models, and guide them towards the development of more effective and reliable systems.
While the CLEME2.0 framework has some practical limitations, its potential to drive more meaningful improvements in GEC technology makes it a valuable contribution to the field. As the dataset and evaluation methods continue to evolve, they have the capacity to significantly impact the way GEC systems are designed, trained, and deployed in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CLEME2.0: Towards More Interpretable Evaluation by Disentangling Edits for Grammatical Error Correction
Jingheng Ye, Zishan Xu, Yinghui Li, Xuxin Cheng, Linlin Song, Qingyu Zhou, Hai-Tao Zheng, Ying Shen, Xin Su
The paper focuses on improving the interpretability of Grammatical Error Correction (GEC) metrics, which receives little attention in previous studies. To bridge the gap, we propose CLEME2.0, a reference-based evaluation strategy that can describe four elementary dimensions of GEC systems, namely hit-correction, error-correction, under-correction, and over-correction. They collectively contribute to revealing the critical characteristics and locating drawbacks of GEC systems. Evaluating systems by Combining these dimensions leads to high human consistency over other reference-based and reference-less metrics. Extensive experiments on 2 human judgement datasets and 6 reference datasets demonstrate the effectiveness and robustness of our method. All the codes will be released after the peer review.
Read more7/2/2024

0
Revisiting Meta-evaluation for Grammatical Error Correction
Masamune Kobayashi, Masato Mita, Mamoru Komachi
Metrics are the foundation for automatic evaluation in grammatical error correction (GEC), with their evaluation of the metrics (meta-evaluation) relying on their correlation with human judgments. However, conventional meta-evaluations in English GEC encounter several challenges including biases caused by inconsistencies in evaluation granularity, and an outdated setup using classical systems. These problems can lead to misinterpretation of metrics and potentially hinder the applicability of GEC techniques. To address these issues, this paper proposes SEEDA, a new dataset for GEC meta-evaluation. SEEDA consists of corrections with human ratings along two different granularities: edit-based and sentence-based, covering 12 state-of-the-art systems including large language models (LLMs), and two human corrections with different focuses. The results of improved correlations by aligning the granularity in the sentence-level meta-evaluation, suggest that edit-based metrics may have been underestimated in existing studies. Furthermore, correlations of most metrics decrease when changing from classical to neural systems, indicating that traditional metrics are relatively poor at evaluating fluently corrected sentences with many edits.
Read more5/28/2024
0
EXCGEC: A Benchmark of Edit-wise Explainable Chinese Grammatical Error Correction
Jingheng Ye, Shang Qin, Yinghui Li, Xuxin Cheng, Libo Qin, Hai-Tao Zheng, Peng Xing, Zishan Xu, Guo Cheng, Zhao Wei
Existing studies explore the explainability of Grammatical Error Correction (GEC) in a limited scenario, where they ignore the interaction between corrections and explanations. To bridge the gap, this paper introduces the task of EXplainable GEC (EXGEC), which focuses on the integral role of both correction and explanation tasks. To facilitate the task, we propose EXCGEC, a tailored benchmark for Chinese EXGEC consisting of 8,216 explanation-augmented samples featuring the design of hybrid edit-wise explanations. We benchmark several series of LLMs in multiple settings, covering post-explaining and pre-explaining. To promote the development of the task, we introduce a comprehensive suite of automatic metrics and conduct human evaluation experiments to demonstrate the human consistency of the automatic metrics for free-text explanations. All the codes and data will be released after the review.
Read more7/2/2024
💬
0
Pillars of Grammatical Error Correction: Comprehensive Inspection Of Contemporary Approaches In The Era of Large Language Models
Kostiantyn Omelianchuk, Andrii Liubonko, Oleksandr Skurzhanskyi, Artem Chernodub, Oleksandr Korniienko, Igor Samokhin
In this paper, we carry out experimental research on Grammatical Error Correction, delving into the nuances of single-model systems, comparing the efficiency of ensembling and ranking methods, and exploring the application of large language models to GEC as single-model systems, as parts of ensembles, and as ranking methods. We set new state-of-the-art performance with F_0.5 scores of 72.8 on CoNLL-2014-test and 81.4 on BEA-test, respectively. To support further advancements in GEC and ensure the reproducibility of our research, we make our code, trained models, and systems' outputs publicly available.
Read more4/24/2024