EXCGEC: A Benchmark of Edit-wise Explainable Chinese Grammatical Error Correction

0
Sign in to get full access
Overview
- This paper introduces EXCGEC, a new benchmark for evaluating Chinese Grammatical Error Correction (GEC) systems.
- EXCGEC focuses on edit-wise explanations, providing insights into why a GEC system made specific corrections.
- The paper presents a large-scale dataset with high-quality annotations and a suite of evaluation metrics to assess both the correctness and explainability of GEC systems.
Plain English Explanation
The paper introduces a new benchmark called EXCGEC for evaluating Chinese Grammatical Error Correction (GEC) systems. GEC systems are designed to automatically identify and correct errors in written Chinese text. However, existing GEC benchmarks often only assess the final corrected output, without providing any explanation for why the system made certain corrections.
EXCGEC aims to address this by focusing on "edit-wise explanations" - providing insights into the reasoning behind each individual correction made by a GEC system. The paper presents a large dataset with high-quality annotations that can be used to train and evaluate GEC systems, along with a suite of evaluation metrics to assess both the correctness and explainability of the systems' outputs.
By incorporating explanations into the evaluation process, EXCGEC can help researchers and developers better understand the strengths and weaknesses of their GEC models, and ultimately improve the performance and transparency of these systems.
Technical Explanation
The paper introduces EXCGEC, a new benchmark for evaluating Chinese Grammatical Error Correction (GEC) systems. Unlike previous GEC benchmarks that only assess the final corrected output, EXCGEC focuses on providing "edit-wise explanations" - insights into why a GEC system made specific corrections.
To create EXCGEC, the authors collected a large-scale dataset of Chinese sentences with grammatical errors, and had human annotators provide high-quality corrections along with explanations for each edit. This resulted in a dataset of over 30,000 sentences with detailed annotations.
The authors also developed a suite of evaluation metrics to assess both the correctness and explainability of GEC system outputs. These include traditional GEC metrics like precision and recall, as well as new metrics that measure the quality and faithfulness of the provided explanations.
Evaluating GEC systems with EXCGEC can help researchers and developers better understand the strengths and weaknesses of their models, and identify areas for improvement. By incorporating explanations into the evaluation process, EXCGEC aims to drive progress towards more interpretable and trustworthy GEC systems.
Critical Analysis
The EXCGEC benchmark represents an important step forward in the evaluation of Chinese Grammatical Error Correction systems. By focusing on edit-wise explanations, the authors have addressed a key limitation of previous GEC benchmarks, which only assessed the final corrected output without providing any insight into the model's reasoning.
However, the paper does acknowledge some potential limitations of the EXCGEC dataset and evaluation metrics. For example, the explanations provided by human annotators may not always align with the true reasoning of a GEC system, and the evaluation metrics may not fully capture all aspects of explainability.
Additionally, while EXCGEC is a significant advancement for the Chinese GEC task, it remains to be seen how well the benchmark and evaluation approach can be adapted or extended to other languages and grammatical error correction scenarios. Further research and validation will be needed to understand the broader applicability and generalizability of this framework.
Overall, the EXCGEC benchmark represents an important contribution to the field of Grammatical Error Correction, and its focus on explainability aligns well with the growing emphasis on interpretable and trustworthy AI systems. As the research community continues to build upon this work, we can expect to see further advancements in the transparency and performance of GEC models.
Conclusion
The EXCGEC benchmark introduced in this paper represents a significant advancement in the evaluation of Chinese Grammatical Error Correction systems. By incorporating edit-wise explanations into the assessment process, EXCGEC provides insights into the reasoning behind a GEC system's corrections, going beyond simply measuring the final output quality.
The large-scale dataset and comprehensive evaluation metrics developed as part of this work can help researchers and developers better understand the strengths and weaknesses of their GEC models, and identify opportunities for improvement. As the field of GEC continues to evolve, the EXCGEC framework can serve as a valuable tool for driving progress towards more interpretable and trustworthy systems.
While the paper acknowledges some potential limitations, the overall approach demonstrates the value of incorporating explainability into the evaluation of language technologies. As AI systems become more prevalent in our daily lives, ensuring their transparency and reliability will be increasingly important. The EXCGEC benchmark represents an important step in this direction, with potential implications for a wide range of natural language processing applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
EXCGEC: A Benchmark of Edit-wise Explainable Chinese Grammatical Error Correction
Jingheng Ye, Shang Qin, Yinghui Li, Xuxin Cheng, Libo Qin, Hai-Tao Zheng, Peng Xing, Zishan Xu, Guo Cheng, Zhao Wei
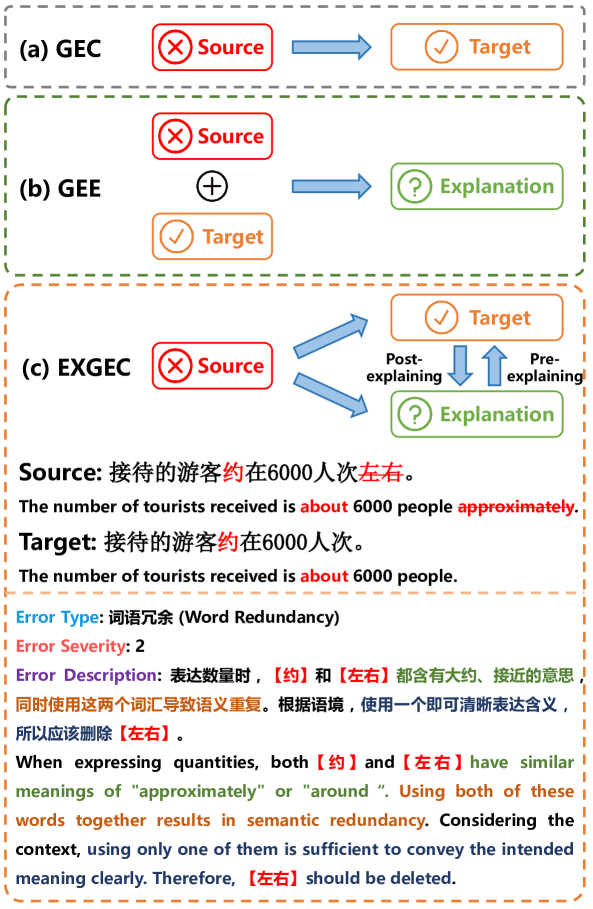
Existing studies explore the explainability of Grammatical Error Correction (GEC) in a limited scenario, where they ignore the interaction between corrections and explanations. To bridge the gap, this paper introduces the task of EXplainable GEC (EXGEC), which focuses on the integral role of both correction and explanation tasks. To facilitate the task, we propose EXCGEC, a tailored benchmark for Chinese EXGEC consisting of 8,216 explanation-augmented samples featuring the design of hybrid edit-wise explanations. We benchmark several series of LLMs in multiple settings, covering post-explaining and pre-explaining. To promote the development of the task, we introduce a comprehensive suite of automatic metrics and conduct human evaluation experiments to demonstrate the human consistency of the automatic metrics for free-text explanations. All the codes and data will be released after the review.
Read more7/2/2024

0
CLEME2.0: Towards More Interpretable Evaluation by Disentangling Edits for Grammatical Error Correction
Jingheng Ye, Zishan Xu, Yinghui Li, Xuxin Cheng, Linlin Song, Qingyu Zhou, Hai-Tao Zheng, Ying Shen, Xin Su
The paper focuses on improving the interpretability of Grammatical Error Correction (GEC) metrics, which receives little attention in previous studies. To bridge the gap, we propose CLEME2.0, a reference-based evaluation strategy that can describe four elementary dimensions of GEC systems, namely hit-correction, error-correction, under-correction, and over-correction. They collectively contribute to revealing the critical characteristics and locating drawbacks of GEC systems. Evaluating systems by Combining these dimensions leads to high human consistency over other reference-based and reference-less metrics. Extensive experiments on 2 human judgement datasets and 6 reference datasets demonstrate the effectiveness and robustness of our method. All the codes will be released after the peer review.
Read more7/2/2024
💬
0
Rethinking the Roles of Large Language Models in Chinese Grammatical Error Correction
Yinghui Li, Shang Qin, Haojing Huang, Yangning Li, Libo Qin, Xuming Hu, Wenhao Jiang, Hai-Tao Zheng, Philip S. Yu
Recently, Large Language Models (LLMs) have been widely studied by researchers for their roles in various downstream NLP tasks. As a fundamental task in the NLP field, Chinese Grammatical Error Correction (CGEC) aims to correct all potential grammatical errors in the input sentences. Previous studies have shown that LLMs' performance as correctors on CGEC remains unsatisfactory due to its challenging task focus. To promote the CGEC field to better adapt to the era of LLMs, we rethink the roles of LLMs in the CGEC task so that they can be better utilized and explored in CGEC. Considering the rich grammatical knowledge stored in LLMs and their powerful semantic understanding capabilities, we utilize LLMs as explainers to provide explanation information for the CGEC small models during error correction to enhance performance. We also use LLMs as evaluators to bring more reasonable CGEC evaluations, thus alleviating the troubles caused by the subjectivity of the CGEC task. In particular, our work is also an active exploration of how LLMs and small models better collaborate in downstream tasks. Extensive experiments and detailed analyses on widely used datasets verify the effectiveness of our thinking intuition and the proposed methods.
Read more9/20/2024
💬
0
How Ready Are Generative Pre-trained Large Language Models for Explaining Bengali Grammatical Errors?
Subhankar Maity, Aniket Deroy, Sudeshna Sarkar
Grammatical error correction (GEC) tools, powered by advanced generative artificial intelligence (AI), competently correct linguistic inaccuracies in user input. However, they often fall short in providing essential natural language explanations, which are crucial for learning languages and gaining a deeper understanding of the grammatical rules. There is limited exploration of these tools in low-resource languages such as Bengali. In such languages, grammatical error explanation (GEE) systems should not only correct sentences but also provide explanations for errors. This comprehensive approach can help language learners in their quest for proficiency. Our work introduces a real-world, multi-domain dataset sourced from Bengali speakers of varying proficiency levels and linguistic complexities. This dataset serves as an evaluation benchmark for GEE systems, allowing them to use context information to generate meaningful explanations and high-quality corrections. Various generative pre-trained large language models (LLMs), including GPT-4 Turbo, GPT-3.5 Turbo, Text-davinci-003, Text-babbage-001, Text-curie-001, Text-ada-001, Llama-2-7b, Llama-2-13b, and Llama-2-70b, are assessed against human experts for performance comparison. Our research underscores the limitations in the automatic deployment of current state-of-the-art generative pre-trained LLMs for Bengali GEE. Advocating for human intervention, our findings propose incorporating manual checks to address grammatical errors and improve feedback quality. This approach presents a more suitable strategy to refine the GEC tools in Bengali, emphasizing the educational aspect of language learning.
Read more6/4/2024