CLFT: Camera-LiDAR Fusion Transformer for Semantic Segmentation in Autonomous Driving
2404.17793
0
0
Abstract
Critical research about camera-and-LiDAR-based semantic object segmentation for autonomous driving significantly benefited from the recent development of deep learning. Specifically, the vision transformer is the novel ground-breaker that successfully brought the multi-head-attention mechanism to computer vision applications. Therefore, we propose a vision-transformer-based network to carry out camera-LiDAR fusion for semantic segmentation applied to autonomous driving. Our proposal uses the novel progressive-assemble strategy of vision transformers on a double-direction network and then integrates the results in a cross-fusion strategy over the transformer decoder layers. Unlike other works in the literature, our camera-LiDAR fusion transformers have been evaluated in challenging conditions like rain and low illumination, showing robust performance. The paper reports the segmentation results over the vehicle and human classes in different modalities: camera-only, LiDAR-only, and camera-LiDAR fusion. We perform coherent controlled benchmark experiments of CLFT against other networks that are also designed for semantic segmentation. The experiments aim to evaluate the performance of CLFT independently from two perspectives: multimodal sensor fusion and backbone architectures. The quantitative assessments show our CLFT networks yield an improvement of up to 10% for challenging dark-wet conditions when comparing with Fully-Convolutional-Neural-Network-based (FCN) camera-LiDAR fusion neural network. Contrasting to the network with transformer backbone but using single modality input, the all-around improvement is 5-10%.
Create account to get full access
Overview
- This paper proposes a Camera-LiDAR Fusion Transformer (CLFT) for semantic segmentation in autonomous driving.
- CLFT combines visual information from cameras and depth information from LiDAR sensors to improve the accuracy of semantic segmentation, which is crucial for autonomous vehicles to understand their surroundings.
- The authors leverage the power of transformers to effectively fuse the multi-modal data and capture long-range dependencies.
Plain English Explanation
The goal of this research is to help autonomous vehicles better understand their environment. Autonomous vehicles rely on sensors like cameras and LiDAR (light detection and ranging) to "see" the world around them. Cameras provide visual information, while LiDAR provides depth information. By combining these two data sources using a LMFNet: Efficient Multimodal Fusion Approach for Semantic Segmentation, the researchers aim to create a more accurate and comprehensive understanding of the vehicle's surroundings.
The key innovation in this paper is the use of a Transformer model to fuse the camera and LiDAR data. Transformers are a type of deep learning model that are particularly good at capturing long-range dependencies and relationships in data. By using a Transformer, the researchers can better integrate the visual and depth information from the two sensors, leading to improved semantic segmentation performance.
Semantic segmentation is the process of identifying and labeling different objects and elements in an image or scene, such as roads, buildings, vehicles, pedestrians, etc. This is a crucial capability for autonomous vehicles, as it allows them to understand their environment and make safe and appropriate decisions while driving.
Technical Explanation
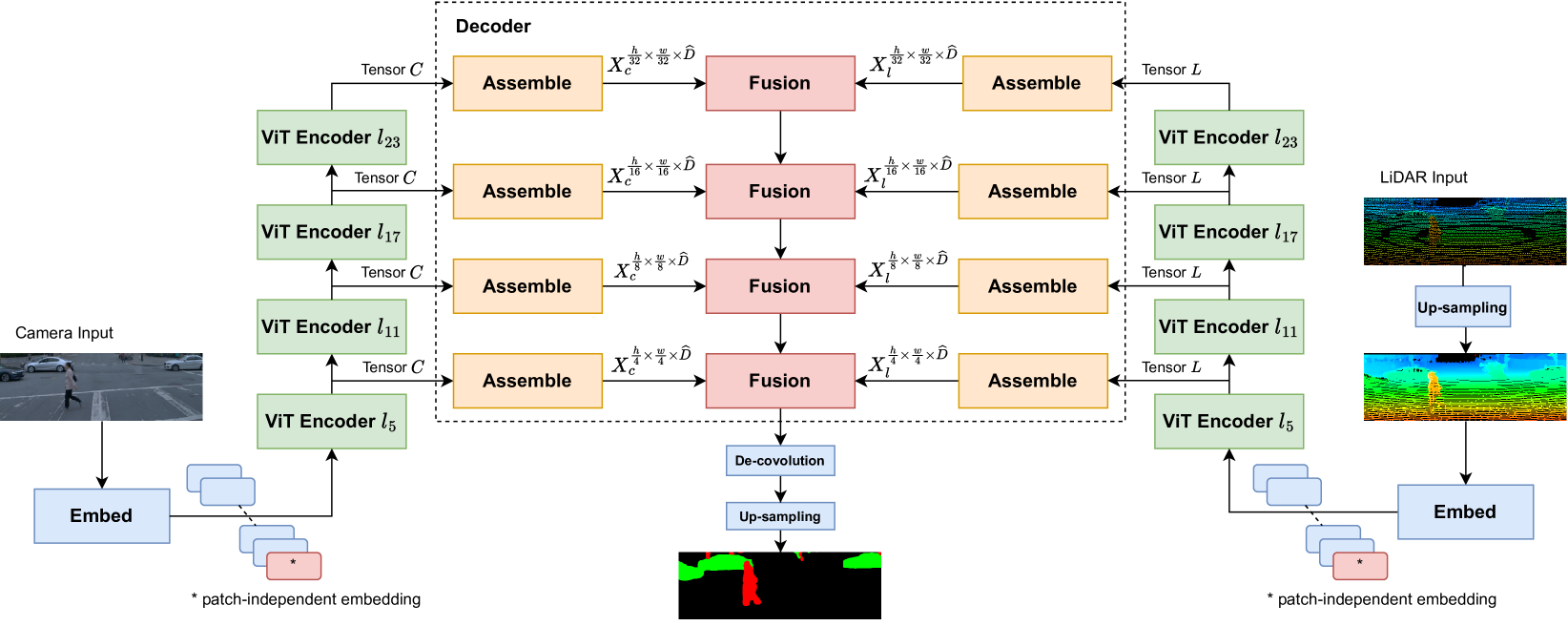
The proposed Camera-LiDAR Fusion Transformer (CLFT) consists of several key components:
- Camera and LiDAR Feature Extraction: The visual and depth features are extracted from the camera and LiDAR inputs using convolutional neural networks.
- Camera-LiDAR Fusion Transformer: This is the core of the model, where the extracted features are fused using a Transformer architecture. The Transformer captures long-range dependencies between the camera and LiDAR features, allowing the model to better integrate the multi-modal information.
- Semantic Segmentation Head: The fused features from the Transformer are then passed through a segmentation head to produce the final semantic segmentation output.
The authors evaluate the CLFT model on several standard autonomous driving datasets, including TFNet: Exploiting Temporal Cues for Fast and Accurate LiDAR Semantic Segmentation and DPFT: Dual Perspective Fusion Transformer for Camera-Radar Semantic Segmentation. The results show that the CLFT model outperforms previous state-of-the-art camera-LiDAR fusion approaches, demonstrating the effectiveness of the Transformer-based fusion strategy.
Critical Analysis
The paper provides a comprehensive evaluation of the CLFT model, including comparisons to various baseline and state-of-the-art methods. However, the authors do acknowledge some limitations of their approach:
- The model's performance may be affected by the quality and calibration of the camera and LiDAR sensors, as well as environmental conditions like lighting and weather.
- The Transformer-based fusion strategy may be computationally more expensive than some earlier fusion approaches, which could be a concern for real-time autonomous driving applications.
Additionally, the paper does not explore the potential for further performance improvements through the use of more advanced fusion techniques, such as those explored in Learning Optical Flow and Scene Flow with Bidirectional Camera-LiDAR Fusion or LUCFNet: Lightweight U-shaped Cascade Fusion Network for Accurate Semantic Segmentation. Investigating these alternatives could be a valuable direction for future research.
Conclusion
The Camera-LiDAR Fusion Transformer (CLFT) proposed in this paper represents an innovative approach to improving semantic segmentation for autonomous driving. By effectively fusing visual and depth information using a Transformer-based architecture, the model is able to outperform previous state-of-the-art camera-LiDAR fusion methods.
The successful integration of Transformer-based fusion is a significant contribution to the field of autonomous driving, as it demonstrates the potential of advanced deep learning techniques to enhance the perception capabilities of self-driving vehicles. As the development of autonomous driving technologies continues to progress, the insights and techniques presented in this paper could have important implications for improving the safety and reliability of future autonomous systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Lift-Attend-Splat: Bird's-eye-view camera-lidar fusion using transformers
James Gunn, Zygmunt Lenyk, Anuj Sharma, Andrea Donati, Alexandru Buburuzan, John Redford, Romain Mueller
0
0
Combining complementary sensor modalities is crucial to providing robust perception for safety-critical robotics applications such as autonomous driving (AD). Recent state-of-the-art camera-lidar fusion methods for AD rely on monocular depth estimation which is a notoriously difficult task compared to using depth information from the lidar directly. Here, we find that this approach does not leverage depth as expected and show that naively improving depth estimation does not lead to improvements in object detection performance. Strikingly, we also find that removing depth estimation altogether does not degrade object detection performance substantially, suggesting that relying on monocular depth could be an unnecessary architectural bottleneck during camera-lidar fusion. In this work, we introduce a novel fusion method that bypasses monocular depth estimation altogether and instead selects and fuses camera and lidar features in a bird's-eye-view grid using a simple attention mechanism. We show that our model can modulate its use of camera features based on the availability of lidar features and that it yields better 3D object detection on the nuScenes dataset than baselines relying on monocular depth estimation.
5/22/2024
🌐
LUCF-Net: Lightweight U-shaped Cascade Fusion Network for Medical Image Segmentation
Songkai Sun, Qingshan She, Yuliang Ma, Rihui Li, Yingchun Zhang
0
0
In this study, the performance of existing U-shaped neural network architectures was enhanced for medical image segmentation by adding Transformer. Although Transformer architectures are powerful at extracting global information, its ability to capture local information is limited due to its high complexity. To address this challenge, we proposed a new lightweight U-shaped cascade fusion network (LUCF-Net) for medical image segmentation. It utilized an asymmetrical structural design and incorporated both local and global modules to enhance its capacity for local and global modeling. Additionally, a multi-layer cascade fusion decoding network was designed to further bolster the network's information fusion capabilities. Validation results achieved on multi-organ datasets in CT format, cardiac segmentation datasets in MRI format, and dermatology datasets in image format demonstrated that the proposed model outperformed other state-of-the-art methods in handling local-global information, achieving an improvement of 1.54% in Dice coefficient and 2.6 mm in Hausdorff distance on multi-organ segmentation. Furthermore, as a network that combines Convolutional Neural Network and Transformer architectures, it achieves competitive segmentation performance with only 6.93 million parameters and 6.6 gigabytes of floating point operations, without the need of pre-training. In summary, the proposed method demonstrated enhanced performance while retaining a simpler model design compared to other Transformer-based segmentation networks.
4/12/2024

Generative AI Empowered LiDAR Point Cloud Generation with Multimodal Transformer
Mohammad Farzanullah, Han Zhang, Akram Bin Sediq, Ali Afana, Melike Erol-Kantarci
0
0
Integrated sensing and communications is a key enabler for the 6G wireless communication systems. The multiple sensing modalities will allow the base station to have a more accurate representation of the environment, leading to context-aware communications. Some widely equipped sensors such as cameras and RADAR sensors can provide some environmental perceptions. However, they are not enough to generate precise environmental representations, especially in adverse weather conditions. On the other hand, the LiDAR sensors provide more accurate representations, however, their widespread adoption is hindered by their high cost. This paper proposes a novel approach to enhance the wireless communication systems by synthesizing LiDAR point clouds from images and RADAR data. Specifically, it uses a multimodal transformer architecture and pre-trained encoding models to enable an accurate LiDAR generation. The proposed framework is evaluated on the DeepSense 6G dataset, which is a real-world dataset curated for context-aware wireless applications. Our results demonstrate the efficacy of the proposed approach in accurately generating LiDAR point clouds. We achieve a modified mean squared error of 10.3931. Visual examination of the images indicates that our model can successfully capture the majority of structures present in the LiDAR point cloud for diverse environments. This will enable the base stations to achieve more precise environmental sensing. By integrating LiDAR synthesis with existing sensing modalities, our method can enhance the performance of various wireless applications, including beam and blockage prediction.
6/28/2024
📈
TFNet: Exploiting Temporal Cues for Fast and Accurate LiDAR Semantic Segmentation
Rong Li, ShiJie Li, Xieyuanli Chen, Teli Ma, Juergen Gall, Junwei Liang
0
0
LiDAR semantic segmentation plays a crucial role in enabling autonomous driving and robots to understand their surroundings accurately and robustly. A multitude of methods exist within this domain, including point-based, range-image-based, polar-coordinate-based, and hybrid strategies. Among these, range-image-based techniques have gained widespread adoption in practical applications due to their efficiency. However, they face a significant challenge known as the ``many-to-one'' problem caused by the range image's limited horizontal and vertical angular resolution. As a result, around 20% of the 3D points can be occluded. In this paper, we present TFNet, a range-image-based LiDAR semantic segmentation method that utilizes temporal information to address this issue. Specifically, we incorporate a temporal fusion layer to extract useful information from previous scans and integrate it with the current scan. We then design a max-voting-based post-processing technique to correct false predictions, particularly those caused by the ``many-to-one'' issue. We evaluated the approach on two benchmarks and demonstrated that the plug-in post-processing technique is generic and can be applied to various networks.
4/16/2024