Lift-Attend-Splat: Bird's-eye-view camera-lidar fusion using transformers
2312.14919
0
0

Abstract
Combining complementary sensor modalities is crucial to providing robust perception for safety-critical robotics applications such as autonomous driving (AD). Recent state-of-the-art camera-lidar fusion methods for AD rely on monocular depth estimation which is a notoriously difficult task compared to using depth information from the lidar directly. Here, we find that this approach does not leverage depth as expected and show that naively improving depth estimation does not lead to improvements in object detection performance. Strikingly, we also find that removing depth estimation altogether does not degrade object detection performance substantially, suggesting that relying on monocular depth could be an unnecessary architectural bottleneck during camera-lidar fusion. In this work, we introduce a novel fusion method that bypasses monocular depth estimation altogether and instead selects and fuses camera and lidar features in a bird's-eye-view grid using a simple attention mechanism. We show that our model can modulate its use of camera features based on the availability of lidar features and that it yields better 3D object detection on the nuScenes dataset than baselines relying on monocular depth estimation.
Create account to get full access
Overview
- This paper presents "Lift-Attend-Splat," a novel approach for fusing camera and LiDAR data for 3D object detection in autonomous driving.
- The proposed method uses transformer-based architectures to effectively combine the complementary information from camera and LiDAR sensors.
- The paper demonstrates improved 3D detection performance compared to existing camera-LiDAR fusion techniques.
Plain English Explanation
Autonomous vehicles rely on sensors like cameras and LiDAR (Light Detection and Ranging) to perceive the world around them. Camera-LiDAR fusion is a key technique for combining the strengths of these two sensor modalities to improve 3D object detection, which is crucial for safe navigation.
In this paper, the researchers introduce "Lift-Attend-Splat," a new way of fusing camera and LiDAR data using transformer neural networks. Transformers are a type of machine learning model that can efficiently capture dependencies and relationships in complex data, making them well-suited for this task.
The "Lift-Attend-Splat" process works as follows:
- Lift: The camera and LiDAR data are first transformed into a common feature representation.
- Attend: The transformer network then learns to attend to the most relevant features from both sensors, identifying the key information for accurate 3D detection.
- Splat: The attended features are then combined and "splattered" back onto a 3D grid, which is used to generate the final 3D object detections.
By effectively fusing the complementary information from cameras and LiDAR, the Lift-Attend-Splat method demonstrates improved 3D object detection performance compared to other camera-LiDAR fusion approaches. This advancement can contribute to the development of safer and more reliable autonomous driving systems.
Technical Explanation
The paper presents a novel camera-LiDAR fusion approach called "Lift-Attend-Splat" for 3D object detection in autonomous driving. The method leverages transformer-based architectures to effectively combine the strengths of both sensor modalities.
The core components of the Lift-Attend-Splat approach are:
- Lift: The camera and LiDAR data are first processed through separate "lifting" networks, which transform the sensor-specific features into a common feature representation.
- Attend: A transformer-based fusion module then learns to attend to the most relevant features from the camera and LiDAR data, identifying the key information for accurate 3D detection.
- Splat: The attended features are then "splattered" back onto a 3D grid, which is used to generate the final 3D object detections.
The transformer-based fusion module is a key innovation of this work. By utilizing the attention mechanism of transformers, the model can effectively capture the complex dependencies and relationships between the camera and LiDAR features, leading to improved 3D detection performance.
The paper evaluates the Lift-Attend-Splat approach on popular autonomous driving datasets, such as KITTI and nuScenes. The results demonstrate that the proposed method outperforms existing camera-LiDAR fusion techniques, particularly for challenging object categories and under varying weather conditions.
Critical Analysis
The Lift-Attend-Splat approach presents a promising advancement in camera-LiDAR fusion for 3D object detection, but it also has some potential limitations and areas for further research:
-
Computational Complexity: The transformer-based fusion module may introduce additional computational overhead compared to simpler fusion methods. The authors mention that they have optimized the architecture to mitigate this, but the real-world deployment implications should be further investigated.
-
Robustness to Sensor Failures: The paper does not explicitly address the robustness of the Lift-Attend-Splat approach to sensor failures or degradation, which is a critical concern for autonomous driving systems. Techniques like multi-sensor fusion could be explored to improve the system's resilience.
-
Generalization to Other Sensor Modalities: While the paper focuses on camera-LiDAR fusion, the principles of the Lift-Attend-Splat approach could potentially be extended to incorporate other sensor modalities, such as radar or stereo cameras. Exploring these extensions could further enhance the versatility of the method.
Overall, the Lift-Attend-Splat technique represents a significant advancement in camera-LiDAR fusion for 3D object detection, and the authors have made valuable contributions to the field of autonomous driving perception. Further research and real-world validation will be necessary to address the identified limitations and fully realize the potential of this approach.
Conclusion
The Lift-Attend-Splat method presented in this paper offers a novel and effective way to fuse camera and LiDAR data for 3D object detection in autonomous driving. By leveraging transformer-based architectures, the approach can better capture the complex relationships between the sensor modalities, leading to improved detection performance.
This research represents an important step forward in the development of robust and reliable perception systems for autonomous vehicles. As autonomous driving continues to advance, techniques like Lift-Attend-Splat will play a crucial role in enabling safer and more intelligent transportation solutions that can navigate the complex real-world environment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Better Monocular 3D Detectors with LiDAR from the Past
Yurong You, Cheng Perng Phoo, Carlos Andres Diaz-Ruiz, Katie Z Luo, Wei-Lun Chao, Mark Campbell, Bharath Hariharan, Kilian Q Weinberger
0
0
Accurate 3D object detection is crucial to autonomous driving. Though LiDAR-based detectors have achieved impressive performance, the high cost of LiDAR sensors precludes their widespread adoption in affordable vehicles. Camera-based detectors are cheaper alternatives but often suffer inferior performance compared to their LiDAR-based counterparts due to inherent depth ambiguities in images. In this work, we seek to improve monocular 3D detectors by leveraging unlabeled historical LiDAR data. Specifically, at inference time, we assume that the camera-based detectors have access to multiple unlabeled LiDAR scans from past traversals at locations of interest (potentially from other high-end vehicles equipped with LiDAR sensors). Under this setup, we proposed a novel, simple, and end-to-end trainable framework, termed AsyncDepth, to effectively extract relevant features from asynchronous LiDAR traversals of the same location for monocular 3D detectors. We show consistent and significant performance gain (up to 9 AP) across multiple state-of-the-art models and datasets with a negligible additional latency of 9.66 ms and a small storage cost.
4/11/2024
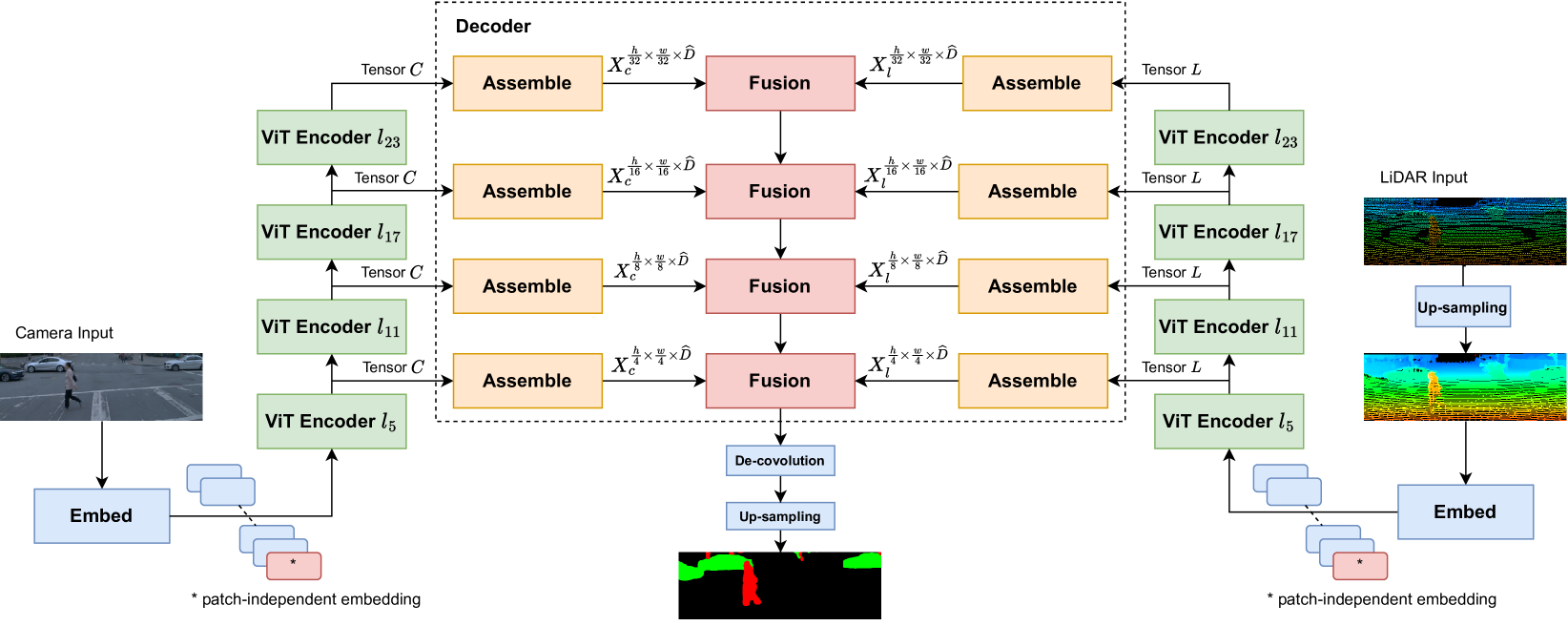
CLFT: Camera-LiDAR Fusion Transformer for Semantic Segmentation in Autonomous Driving
Junyi Gu, Mauro Bellone, Tom'av{s} Pivov{n}ka, Raivo Sell
0
0
Critical research about camera-and-LiDAR-based semantic object segmentation for autonomous driving significantly benefited from the recent development of deep learning. Specifically, the vision transformer is the novel ground-breaker that successfully brought the multi-head-attention mechanism to computer vision applications. Therefore, we propose a vision-transformer-based network to carry out camera-LiDAR fusion for semantic segmentation applied to autonomous driving. Our proposal uses the novel progressive-assemble strategy of vision transformers on a double-direction network and then integrates the results in a cross-fusion strategy over the transformer decoder layers. Unlike other works in the literature, our camera-LiDAR fusion transformers have been evaluated in challenging conditions like rain and low illumination, showing robust performance. The paper reports the segmentation results over the vehicle and human classes in different modalities: camera-only, LiDAR-only, and camera-LiDAR fusion. We perform coherent controlled benchmark experiments of CLFT against other networks that are also designed for semantic segmentation. The experiments aim to evaluate the performance of CLFT independently from two perspectives: multimodal sensor fusion and backbone architectures. The quantitative assessments show our CLFT networks yield an improvement of up to 10% for challenging dark-wet conditions when comparing with Fully-Convolutional-Neural-Network-based (FCN) camera-LiDAR fusion neural network. Contrasting to the network with transformer backbone but using single modality input, the all-around improvement is 5-10%.
6/21/2024

New!BiCo-Fusion: Bidirectional Complementary LiDAR-Camera Fusion for Semantic- and Spatial-Aware 3D Object Detection
Yang Song, Lin Wang
0
0
3D object detection is an important task that has been widely applied in autonomous driving. Recently, fusing multi-modal inputs, i.e., LiDAR and camera data, to perform this task has become a new trend. Existing methods, however, either ignore the sparsity of Lidar features or fail to preserve the original spatial structure of LiDAR and the semantic density of camera features simultaneously due to the modality gap. To address issues, this letter proposes a novel bidirectional complementary Lidar-camera fusion framework, called BiCo-Fusion that can achieve robust semantic- and spatial-aware 3D object detection. The key insight is to mutually fuse the multi-modal features to enhance the semantics of LiDAR features and the spatial awareness of the camera features and adaptatively select features from both modalities to build a unified 3D representation. Specifically, we introduce Pre-Fusion consisting of a Voxel Enhancement Module (VEM) to enhance the semantics of voxel features from 2D camera features and Image Enhancement Module (IEM) to enhance the spatial characteristics of camera features from 3D voxel features. Both VEM and IEM are bidirectionally updated to effectively reduce the modality gap. We then introduce Unified Fusion to adaptively weight to select features from the enchanted Lidar and camera features to build a unified 3D representation. Extensive experiments demonstrate the superiority of our BiCo-Fusion against the prior arts. Project page: https://t-ys.github.io/BiCo-Fusion/.
6/28/2024

Unleashing HyDRa: Hybrid Fusion, Depth Consistency and Radar for Unified 3D Perception
Philipp Wolters, Johannes Gilg, Torben Teepe, Fabian Herzog, Anouar Laouichi, Martin Hofmann, Gerhard Rigoll
0
0
Low-cost, vision-centric 3D perception systems for autonomous driving have made significant progress in recent years, narrowing the gap to expensive LiDAR-based methods. The primary challenge in becoming a fully reliable alternative lies in robust depth prediction capabilities, as camera-based systems struggle with long detection ranges and adverse lighting and weather conditions. In this work, we introduce HyDRa, a novel camera-radar fusion architecture for diverse 3D perception tasks. Building upon the principles of dense BEV (Bird's Eye View)-based architectures, HyDRa introduces a hybrid fusion approach to combine the strengths of complementary camera and radar features in two distinct representation spaces. Our Height Association Transformer module leverages radar features already in the perspective view to produce more robust and accurate depth predictions. In the BEV, we refine the initial sparse representation by a Radar-weighted Depth Consistency. HyDRa achieves a new state-of-the-art for camera-radar fusion of 64.2 NDS (+1.8) and 58.4 AMOTA (+1.5) on the public nuScenes dataset. Moreover, our new semantically rich and spatially accurate BEV features can be directly converted into a powerful occupancy representation, beating all previous camera-based methods on the Occ3D benchmark by an impressive 3.7 mIoU. Code and models are available at https://github.com/phi-wol/hydra.
6/7/2024