Generative AI Empowered LiDAR Point Cloud Generation with Multimodal Transformer
2406.18542
0
0

Abstract
Integrated sensing and communications is a key enabler for the 6G wireless communication systems. The multiple sensing modalities will allow the base station to have a more accurate representation of the environment, leading to context-aware communications. Some widely equipped sensors such as cameras and RADAR sensors can provide some environmental perceptions. However, they are not enough to generate precise environmental representations, especially in adverse weather conditions. On the other hand, the LiDAR sensors provide more accurate representations, however, their widespread adoption is hindered by their high cost. This paper proposes a novel approach to enhance the wireless communication systems by synthesizing LiDAR point clouds from images and RADAR data. Specifically, it uses a multimodal transformer architecture and pre-trained encoding models to enable an accurate LiDAR generation. The proposed framework is evaluated on the DeepSense 6G dataset, which is a real-world dataset curated for context-aware wireless applications. Our results demonstrate the efficacy of the proposed approach in accurately generating LiDAR point clouds. We achieve a modified mean squared error of 10.3931. Visual examination of the images indicates that our model can successfully capture the majority of structures present in the LiDAR point cloud for diverse environments. This will enable the base stations to achieve more precise environmental sensing. By integrating LiDAR synthesis with existing sensing modalities, our method can enhance the performance of various wireless applications, including beam and blockage prediction.
Create account to get full access
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Multi-Modal Data-Efficient 3D Scene Understanding for Autonomous Driving
Lingdong Kong, Xiang Xu, Jiawei Ren, Wenwei Zhang, Liang Pan, Kai Chen, Wei Tsang Ooi, Ziwei Liu
0
0
Efficient data utilization is crucial for advancing 3D scene understanding in autonomous driving, where reliance on heavily human-annotated LiDAR point clouds challenges fully supervised methods. Addressing this, our study extends into semi-supervised learning for LiDAR semantic segmentation, leveraging the intrinsic spatial priors of driving scenes and multi-sensor complements to augment the efficacy of unlabeled datasets. We introduce LaserMix++, an evolved framework that integrates laser beam manipulations from disparate LiDAR scans and incorporates LiDAR-camera correspondences to further assist data-efficient learning. Our framework is tailored to enhance 3D scene consistency regularization by incorporating multi-modality, including 1) multi-modal LaserMix operation for fine-grained cross-sensor interactions; 2) camera-to-LiDAR feature distillation that enhances LiDAR feature learning; and 3) language-driven knowledge guidance generating auxiliary supervisions using open-vocabulary models. The versatility of LaserMix++ enables applications across LiDAR representations, establishing it as a universally applicable solution. Our framework is rigorously validated through theoretical analysis and extensive experiments on popular driving perception datasets. Results demonstrate that LaserMix++ markedly outperforms fully supervised alternatives, achieving comparable accuracy with five times fewer annotations and significantly improving the supervised-only baselines. This substantial advancement underscores the potential of semi-supervised approaches in reducing the reliance on extensive labeled data in LiDAR-based 3D scene understanding systems.
5/9/2024
📊
Empowering Urban Traffic Management: Elevated 3D LiDAR for Data Collection and Advanced Object Detection Analysis
Nawfal Guefrachi, Hakim Ghazzai, Ahmad Alsharoa
0
0
The 3D object detection capabilities in urban environments have been enormously improved by recent developments in Light Detection and Range (LiDAR) technology. This paper presents a novel framework that transforms the detection and analysis of 3D objects in traffic scenarios by utilizing the power of elevated LiDAR sensors. We are presenting our methodology's remarkable capacity to collect complex 3D point cloud data, which allows us to accurately and in detail capture the dynamics of urban traffic. Due to the limitation in obtaining real-world traffic datasets, we utilize the simulator to generate 3D point cloud for specific scenarios. To support our experimental analysis, we firstly simulate various 3D point cloud traffic-related objects. Then, we use this dataset as a basis for training and evaluating our 3D object detection models, in identifying and monitoring both vehicles and pedestrians in simulated urban traffic environments. Next, we fine tune the Point Voxel-Region-based Convolutional Neural Network (PV-RCNN) architecture, making it more suited to handle and understand the massive volumes of point cloud data generated by our urban traffic simulations. Our results show the effectiveness of the proposed solution in accurately detecting objects in traffic scenes and highlight the role of LiDAR in improving urban safety and advancing intelligent transportation systems.
5/24/2024

LidarDM: Generative LiDAR Simulation in a Generated World
Vlas Zyrianov, Henry Che, Zhijian Liu, Shenlong Wang
0
0
We present LidarDM, a novel LiDAR generative model capable of producing realistic, layout-aware, physically plausible, and temporally coherent LiDAR videos. LidarDM stands out with two unprecedented capabilities in LiDAR generative modeling: (i) LiDAR generation guided by driving scenarios, offering significant potential for autonomous driving simulations, and (ii) 4D LiDAR point cloud generation, enabling the creation of realistic and temporally coherent sequences. At the heart of our model is a novel integrated 4D world generation framework. Specifically, we employ latent diffusion models to generate the 3D scene, combine it with dynamic actors to form the underlying 4D world, and subsequently produce realistic sensory observations within this virtual environment. Our experiments indicate that our approach outperforms competing algorithms in realism, temporal coherency, and layout consistency. We additionally show that LidarDM can be used as a generative world model simulator for training and testing perception models.
4/4/2024
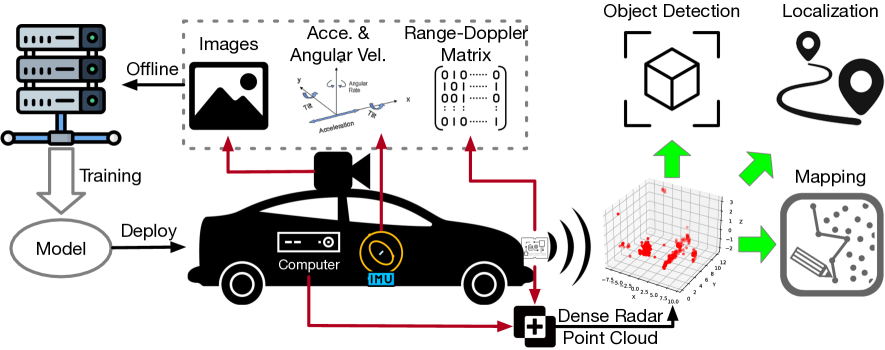
Enhancing mmWave Radar Point Cloud via Visual-inertial Supervision
Cong Fan, Shengkai Zhang, Kezhong Liu, Shuai Wang, Zheng Yang, Wei Wang
0
0
Complementary to prevalent LiDAR and camera systems, millimeter-wave (mmWave) radar is robust to adverse weather conditions like fog, rainstorms, and blizzards but offers sparse point clouds. Current techniques enhance the point cloud by the supervision of LiDAR's data. However, high-performance LiDAR is notably expensive and is not commonly available on vehicles. This paper presents mmEMP, a supervised learning approach that enhances radar point clouds using a low-cost camera and an inertial measurement unit (IMU), enabling crowdsourcing training data from commercial vehicles. Bringing the visual-inertial (VI) supervision is challenging due to the spatial agnostic of dynamic objects. Moreover, spurious radar points from the curse of RF multipath make robots misunderstand the scene. mmEMP first devises a dynamic 3D reconstruction algorithm that restores the 3D positions of dynamic features. Then, we design a neural network that densifies radar data and eliminates spurious radar points. We build a new dataset in the real world. Extensive experiments show that mmEMP achieves competitive performance compared with the SOTA approach training by LiDAR's data. In addition, we use the enhanced point cloud to perform object detection, localization, and mapping to demonstrate mmEMP's effectiveness.
4/29/2024