CLOMO: Counterfactual Logical Modification with Large Language Models
2311.17438
0
0

Abstract
In this study, we delve into the realm of counterfactual reasoning capabilities of large language models (LLMs). Our primary objective is to cultivate the counterfactual thought processes within LLMs and rigorously assess these processes for their validity. Specifically, we introduce a novel task, Counterfactual Logical Modification (CLOMO), and a high-quality human-annotated benchmark. In this task, LLMs must adeptly alter a given argumentative text to uphold a predetermined logical relationship. To effectively evaluate a generation model's counterfactual capabilities, we propose an innovative evaluation metric, the decomposed Self-Evaluation Score (SES) to directly evaluate the natural language output of LLMs instead of modeling the task as a multiple-choice problem. Analysis shows that the proposed automatic metric aligns well with human preference. Our experimental results show that while LLMs demonstrate a notable capacity for logical counterfactual thinking, there remains a discernible gap between their current abilities and human performance. Code and data are available at https://github.com/Eleanor-H/CLOMO.
Create account to get full access
Overview
- This paper introduces CLoMo, a novel method for modifying the logic and reasoning of large language models (LLMs) to generate counterfactual scenarios.
- Counterfactual reasoning - the ability to imagine "what-if" scenarios and understand their implications - is a crucial skill for both humans and AI systems.
- CLoMo aims to enhance the counterfactual reasoning capabilities of LLMs, enabling them to generate more meaningful and logically consistent counterfactual outputs.
Plain English Explanation
Counterfactual reasoning is the ability to imagine "what-if" scenarios - to think about how things could have been different if certain events or conditions had been changed. This is an important skill for both humans and AI systems, as it allows us to explore alternative possibilities, understand causal relationships, and make more informed decisions.
The paper presents a new method called CLoMo (Counterfactual Logical Modification) that enhances the counterfactual reasoning capabilities of large language models (LLMs) - powerful AI systems that can generate human-like text. CLoMo aims to enable LLMs to generate more meaningful and logically consistent counterfactual outputs, rather than just producing random variations.
Technical Explanation
The key idea behind CLoMo is to modify the internal logic and reasoning of LLMs, rather than just tweaking their input or output. The researchers developed a framework that allows them to "steer" the LLM's decision-making process towards generating more coherent and plausible counterfactual scenarios.
CLoMo works by introducing additional "counterfactual prompts" that guide the LLM to consider alternative possibilities and their consequences. The researchers also developed techniques to ensure the generated counterfactuals are logically consistent and avoid contradictions.
Critical Analysis
The paper presents a compelling approach to enhancing the counterfactual reasoning abilities of LLMs, which is an important step forward in the development of more capable and trustworthy AI systems. However, the researchers acknowledge that CLoMo is not a panacea, and there are still significant challenges and limitations to address.
One potential concern is the risk of LLMs generating harmful or biased counterfactuals, particularly when applied to sensitive topics. The researchers emphasize the need for careful monitoring and control measures to ensure the responsible use of this technology.
Another area for further research is the integration of CLoMo with other counterfactual reasoning techniques, such as those based on causal models or reinforcement learning. Combining multiple approaches could lead to even more robust and versatile counterfactual reasoning capabilities.
Conclusion
The CLoMo method presented in this paper represents an important step forward in enhancing the counterfactual reasoning abilities of large language models. By directly modifying the internal logic and decision-making processes of LLMs, the researchers have demonstrated the potential to generate more meaningful and logically consistent counterfactual scenarios.
As AI systems become increasingly capable and influential, the ability to understand and reason about alternative possibilities will be crucial for ensuring their safe and beneficial deployment. The CLoMo approach highlights the importance of developing advanced counterfactual reasoning capabilities in LLMs, which could have far-reaching implications for a wide range of applications, from policy analysis to strategic planning and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

LLMs for Generating and Evaluating Counterfactuals: A Comprehensive Study
Van Bach Nguyen, Paul Youssef, Jorg Schlotterer, Christin Seifert
0
0
As NLP models become more complex, understanding their decisions becomes more crucial. Counterfactuals (CFs), where minimal changes to inputs flip a model's prediction, offer a way to explain these models. While Large Language Models (LLMs) have shown remarkable performance in NLP tasks, their efficacy in generating high-quality CFs remains uncertain. This work fills this gap by investigating how well LLMs generate CFs for two NLU tasks. We conduct a comprehensive comparison of several common LLMs, and evaluate their CFs, assessing both intrinsic metrics, and the impact of these CFs on data augmentation. Moreover, we analyze differences between human and LLM-generated CFs, providing insights for future research directions. Our results show that LLMs generate fluent CFs, but struggle to keep the induced changes minimal. Generating CFs for Sentiment Analysis (SA) is less challenging than NLI where LLMs show weaknesses in generating CFs that flip the original label. This also reflects on the data augmentation performance, where we observe a large gap between augmenting with human and LLMs CFs. Furthermore, we evaluate LLMs' ability to assess CFs in a mislabelled data setting, and show that they have a strong bias towards agreeing with the provided labels. GPT4 is more robust against this bias and its scores correlate well with automatic metrics. Our findings reveal several limitations and point to potential future work directions.
5/3/2024
🏋️
Interactive Analysis of LLMs using Meaningful Counterfactuals
Furui Cheng, Vil'em Zouhar, Robin Shing Moon Chan, Daniel Furst, Hendrik Strobelt, Mennatallah El-Assady
0
0
Counterfactual examples are useful for exploring the decision boundaries of machine learning models and determining feature attributions. How can we apply counterfactual-based methods to analyze and explain LLMs? We identify the following key challenges. First, the generated textual counterfactuals should be meaningful and readable to users and thus can be mentally compared to draw conclusions. Second, to make the solution scalable to long-form text, users should be equipped with tools to create batches of counterfactuals from perturbations at various granularity levels and interactively analyze the results. In this paper, we tackle the above challenges and contribute 1) a novel algorithm for generating batches of complete and meaningful textual counterfactuals by removing and replacing text segments in different granularities, and 2) LLM Analyzer, an interactive visualization tool to help users understand an LLM's behaviors by interactively inspecting and aggregating meaningful counterfactuals. We evaluate the proposed algorithm by the grammatical correctness of its generated counterfactuals using 1,000 samples from medical, legal, finance, education, and news datasets. In our experiments, 97.2% of the counterfactuals are grammatically correct. Through a use case, user studies, and feedback from experts, we demonstrate the usefulness and usability of the proposed interactive visualization tool.
5/3/2024
Eyes Can Deceive: Benchmarking Counterfactual Reasoning Abilities of Multi-modal Large Language Models
Yian Li, Wentao Tian, Yang Jiao, Jingjing Chen, Yu-Gang Jiang
0
0
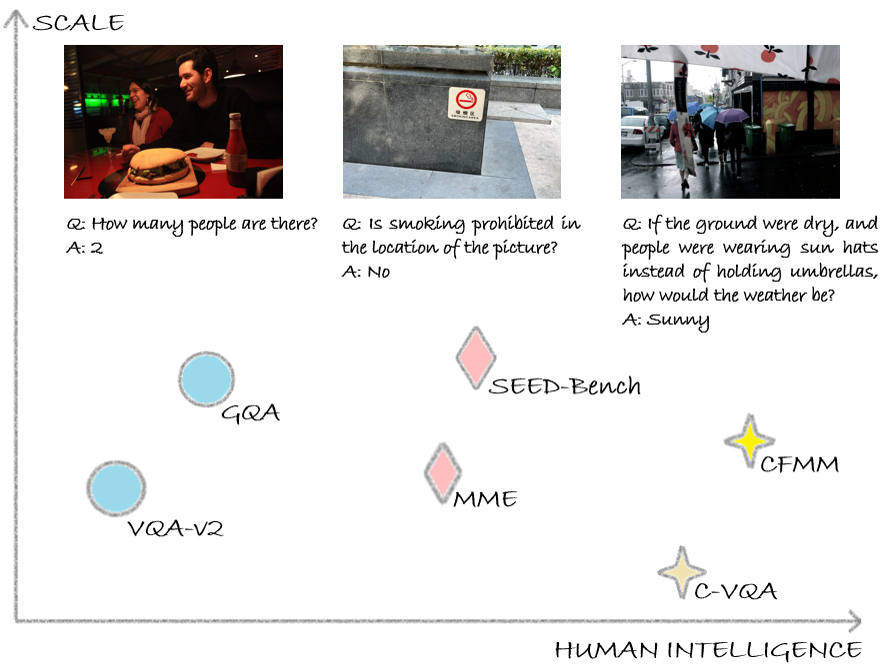
Counterfactual reasoning, as a crucial manifestation of human intelligence, refers to making presuppositions based on established facts and extrapolating potential outcomes. Existing multimodal large language models (MLLMs) have exhibited impressive cognitive and reasoning capabilities, which have been examined across a wide range of Visual Question Answering (VQA) benchmarks. Nevertheless, how will existing MLLMs perform when faced with counterfactual questions? To answer this question, we first curate a novel textbf{C}ountertextbf{F}actual textbf{M}ultitextbf{M}odal reasoning benchmark, abbreviated as textbf{CFMM}, to systematically assess the counterfactual reasoning capabilities of MLLMs. Our CFMM comprises six challenging tasks, each including hundreds of carefully human-labeled counterfactual questions, to evaluate MLLM's counterfactual reasoning capabilities across diverse aspects. Through experiments, interestingly, we find that existing MLLMs prefer to believe what they see, but ignore the counterfactual presuppositions presented in the question, thereby leading to inaccurate responses. Furthermore, we evaluate a wide range of prevalent MLLMs on our proposed CFMM. The significant gap between their performance on our CFMM and that on several VQA benchmarks indicates that there is still considerable room for improvement in existing MLLMs toward approaching human-level intelligence. On the other hand, through boosting MLLMs performances on our CFMM in the future, potential avenues toward developing MLLMs with advanced intelligence can be explored.
4/22/2024
🛸
Zero-shot LLM-guided Counterfactual Generation for Text
Amrita Bhattacharjee, Raha Moraffah, Joshua Garland, Huan Liu
0
0
Counterfactual examples are frequently used for model development and evaluation in many natural language processing (NLP) tasks. Although methods for automated counterfactual generation have been explored, such methods depend on models such as pre-trained language models that are then fine-tuned on auxiliary, often task-specific datasets. Collecting and annotating such datasets for counterfactual generation is labor intensive and therefore, infeasible in practice. Therefore, in this work, we focus on a novel problem setting: textit{zero-shot counterfactual generation}. To this end, we propose a structured way to utilize large language models (LLMs) as general purpose counterfactual example generators. We hypothesize that the instruction-following and textual understanding capabilities of recent LLMs can be effectively leveraged for generating high quality counterfactuals in a zero-shot manner, without requiring any training or fine-tuning. Through comprehensive experiments on various downstream tasks in natural language processing (NLP), we demonstrate the efficacy of LLMs as zero-shot counterfactual generators in evaluating and explaining black-box NLP models.
5/9/2024