What If the TV Was Off? Examining Counterfactual Reasoning Abilities of Multi-modal Language Models
2310.06627
0
0
💬
Abstract
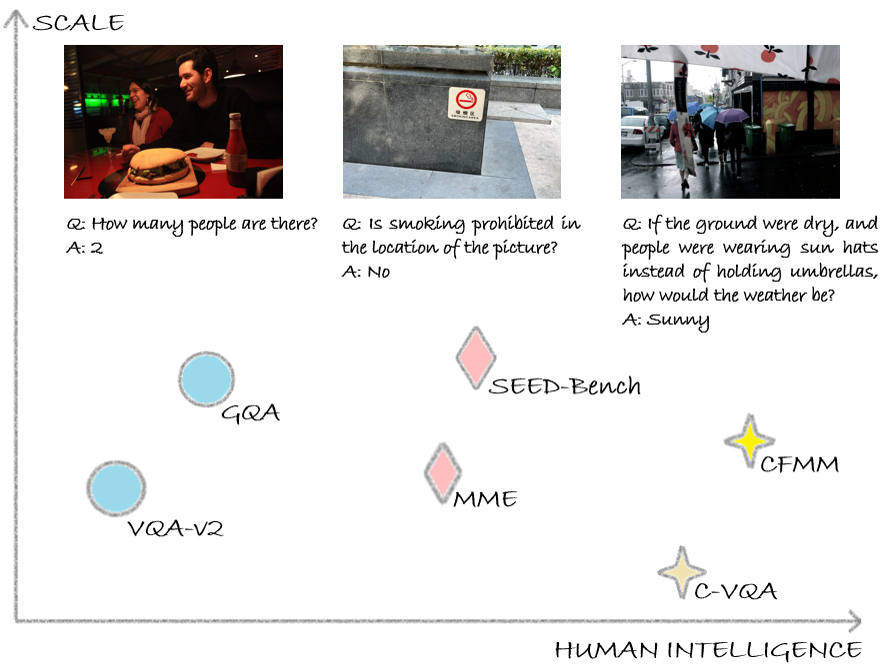
Counterfactual reasoning, a fundamental aspect of human cognition, involves contemplating alternatives to established facts or past events, significantly enhancing our abilities in planning and decision-making. In light of the advancements in current multi-modal large language models, we explore their effectiveness in counterfactual reasoning. To facilitate this investigation, we introduce a novel dataset, C-VQA, specifically designed to test the counterfactual reasoning capabilities of modern multi-modal large language models. This dataset is constructed by infusing original questions with counterfactual presuppositions, spanning various types such as numerical and boolean queries. It encompasses a mix of real and synthetic data, representing a wide range of difficulty levels. Our thorough evaluations of contemporary vision-language models using this dataset have revealed substantial performance drops, with some models showing up to a 40% decrease, highlighting a significant gap between current models and human-like vision reasoning capabilities. We hope our dataset will serve as a vital benchmark for evaluating the counterfactual reasoning capabilities of models. Code and dataset are publicly available at https://bzhao.me/C-VQA/.
Create account to get full access
Overview
- This paper explores the capabilities of current multi-modal large language models in counterfactual reasoning, which involves contemplating alternatives to established facts or past events.
- The researchers introduce a novel dataset called C-VQA, specifically designed to test the counterfactual reasoning abilities of these models.
- The dataset includes questions with counterfactual presuppositions, covering various types such as numerical and boolean queries, and a mix of real and synthetic data.
- Thorough evaluations of contemporary vision-language models using this dataset reveal substantial performance drops, highlighting a significant gap between current models and human-like vision reasoning capabilities.
Plain English Explanation
The paper investigates how well modern large language models can engage in counterfactual reasoning. Counterfactual reasoning is an essential aspect of human cognition, where we contemplate alternatives to established facts or past events. This ability helps us plan better and make more informed decisions.
To test the counterfactual reasoning capabilities of these models, the researchers created a new dataset called C-VQA. This dataset contains questions that include counterfactual assumptions, such as "If the sky was green, what color would the grass be?" The questions cover a range of difficulty levels and include both real and synthetic data.
When the researchers evaluated contemporary vision-language models using this C-VQA dataset, the models showed a significant drop in performance, sometimes up to 40%. This suggests that current models still struggle to match human-like vision reasoning capabilities when it comes to counterfactual reasoning.
The researchers hope that the C-VQA dataset will serve as an important benchmark for evaluating the counterfactual reasoning abilities of future language models and help drive progress in this area of research.
Technical Explanation
The researchers introduce a novel dataset, C-VQA, to investigate the counterfactual reasoning capabilities of current multi-modal large language models. The dataset is constructed by infusing original questions with counterfactual presuppositions, spanning various types such as numerical and boolean queries. It encompasses a mix of real and synthetic data, representing a wide range of difficulty levels.
The researchers then conduct thorough evaluations of contemporary vision-language models using the C-VQA dataset. Their findings reveal substantial performance drops, with some models showing up to a 40% decrease in accuracy, highlighting a significant gap between current models and human-like vision reasoning capabilities.
The researchers hope that the C-VQA dataset will serve as a vital benchmark for evaluating the counterfactual reasoning capabilities of future models, helping to drive progress in this area of research.
Critical Analysis
The paper presents a novel and well-designed dataset, C-VQA, to assess the counterfactual reasoning capabilities of multi-modal large language models. The dataset's inclusion of both real and synthetic data, as well as the variety of question types, adds to its robustness and potential for driving research in this area.
However, the paper does not delve into the specific reasons behind the substantial performance drops observed in the evaluated models. It would be beneficial to understand the underlying limitations or biases that prevent these models from effectively reasoning about counterfactual scenarios. Insights into the model architectures, training data, or other factors that contribute to their weaknesses in this domain could guide future research and model development.
Additionally, the paper does not provide a detailed analysis of the different types of counterfactual questions, their relative difficulty, or the specific areas where the models struggled the most. A more nuanced examination of the dataset's characteristics and the models' performance across different question categories could yield additional insights and inform the design of more targeted training approaches.
Overall, the paper presents a valuable contribution to the field of counterfactual reasoning and highlights the need for further advancements in the capabilities of large language models. The C-VQA dataset is a promising tool for driving progress in this important area of research.
Conclusion
This paper explores the capabilities of current multi-modal large language models in the context of counterfactual reasoning, a fundamental aspect of human cognition. By introducing the novel C-VQA dataset, the researchers have provided a valuable benchmark for evaluating the counterfactual reasoning abilities of these models.
The study's findings reveal a significant gap between the current models and human-like vision reasoning capabilities, with substantial performance drops observed in the evaluations. This highlights the need for further advancements in model architectures and training approaches to address the limitations in counterfactual reasoning.
The C-VQA dataset is a promising tool for driving progress in this important area of research, as it can serve as a platform for testing and comparing the counterfactual reasoning capabilities of future language models. Continued efforts in this direction could lead to more human-like reasoning abilities in AI systems, with potentially significant implications for decision-making, planning, and problem-solving.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Eyes Can Deceive: Benchmarking Counterfactual Reasoning Abilities of Multi-modal Large Language Models
Yian Li, Wentao Tian, Yang Jiao, Jingjing Chen, Yu-Gang Jiang
0
0
Counterfactual reasoning, as a crucial manifestation of human intelligence, refers to making presuppositions based on established facts and extrapolating potential outcomes. Existing multimodal large language models (MLLMs) have exhibited impressive cognitive and reasoning capabilities, which have been examined across a wide range of Visual Question Answering (VQA) benchmarks. Nevertheless, how will existing MLLMs perform when faced with counterfactual questions? To answer this question, we first curate a novel textbf{C}ountertextbf{F}actual textbf{M}ultitextbf{M}odal reasoning benchmark, abbreviated as textbf{CFMM}, to systematically assess the counterfactual reasoning capabilities of MLLMs. Our CFMM comprises six challenging tasks, each including hundreds of carefully human-labeled counterfactual questions, to evaluate MLLM's counterfactual reasoning capabilities across diverse aspects. Through experiments, interestingly, we find that existing MLLMs prefer to believe what they see, but ignore the counterfactual presuppositions presented in the question, thereby leading to inaccurate responses. Furthermore, we evaluate a wide range of prevalent MLLMs on our proposed CFMM. The significant gap between their performance on our CFMM and that on several VQA benchmarks indicates that there is still considerable room for improvement in existing MLLMs toward approaching human-level intelligence. On the other hand, through boosting MLLMs performances on our CFMM in the future, potential avenues toward developing MLLMs with advanced intelligence can be explored.
4/22/2024

What if...?: Thinking Counterfactual Keywords Helps to Mitigate Hallucination in Large Multi-modal Models
Junho Kim, Yeon Ju Kim, Yong Man Ro
0
0
This paper presents a way of enhancing the reliability of Large Multi-modal Models (LMMs) in addressing hallucination, where the models generate cross-modal inconsistent responses. Without additional training, we propose Counterfactual Inception, a novel method that implants counterfactual thinking into LMMs using self-generated counterfactual keywords. Our method is grounded in the concept of counterfactual thinking, a cognitive process where human considers alternative realities, enabling more extensive context exploration. Bridging the human cognition mechanism into LMMs, we aim for the models to engage with and generate responses that span a wider contextual scene understanding, mitigating hallucinatory outputs. We further introduce Plausibility Verification Process (PVP), a simple yet robust keyword constraint that effectively filters out sub-optimal keywords to enable the consistent triggering of counterfactual thinking in the model responses. Comprehensive analyses across various LMMs, including both open-source and proprietary models, corroborate that counterfactual thinking significantly reduces hallucination and helps to broaden contextual understanding based on true visual clues.
6/24/2024
💬
Reasoning or Reciting? Exploring the Capabilities and Limitations of Language Models Through Counterfactual Tasks
Zhaofeng Wu, Linlu Qiu, Alexis Ross, Ekin Akyurek, Boyuan Chen, Bailin Wang, Najoung Kim, Jacob Andreas, Yoon Kim
0
0
The impressive performance of recent language models across a wide range of tasks suggests that they possess a degree of abstract reasoning skills. Are these skills general and transferable, or specialized to specific tasks seen during pretraining? To disentangle these effects, we propose an evaluation framework based on counterfactual task variants that deviate from the default assumptions underlying standard tasks. Across a suite of 11 tasks, we observe nontrivial performance on the counterfactual variants, but nevertheless find that performance substantially and consistently degrades compared to the default conditions. This suggests that while current LMs may possess abstract task-solving skills to an extent, they often also rely on narrow, non-transferable procedures for task-solving. These results motivate a more careful interpretation of language model performance that teases apart these aspects of behavior.
4/1/2024

Evidence from counterfactual tasks supports emergent analogical reasoning in large language models
Taylor Webb, Keith J. Holyoak, Hongjing Lu
0
0
We recently reported evidence that large language models are capable of solving a wide range of text-based analogy problems in a zero-shot manner, indicating the presence of an emergent capacity for analogical reasoning. Two recent commentaries have challenged these results, citing evidence from so-called `counterfactual' tasks in which the standard sequence of the alphabet is arbitrarily permuted so as to decrease similarity with materials that may have been present in the language model's training data. Here, we reply to these critiques, clarifying some misunderstandings about the test materials used in our original work, and presenting evidence that language models are also capable of generalizing to these new counterfactual task variants.
5/1/2024