Cluster-Aware Similarity Diffusion for Instance Retrieval

0
Sign in to get full access
Overview
- The paper proposes a method called "Cluster-Aware Similarity Diffusion" for improving instance retrieval performance.
- It leverages the inherent cluster structure in data to adaptively diffuse similarities between instances.
- The method aims to better capture the underlying relationships between instances and improve retrieval accuracy.
Plain English Explanation
The paper introduces a new technique called "Cluster-Aware Similarity Diffusion" to enhance instance retrieval. The key idea is to take advantage of the natural grouping or clustering of data points to better understand the relationships between them.
Traditionally, instance retrieval relies on calculating the similarity between a query instance and the database instances. However, this can miss important connections that aren't captured by simple similarity scores. The Cluster-Aware Similarity Diffusion method addresses this by diffusing the similarity information across data clusters.
Imagine you're trying to find similar images to a query image in a large database. The Cluster-Aware Similarity Diffusion approach would first identify the clusters or groups of similar images in the database. It would then use this cluster information to adjust the similarity scores, essentially spreading the similarity throughout each cluster.
This allows the method to better capture the underlying relationships between images, even if they don't have the highest direct similarity scores. By considering the cluster structure, it can identify images that may be indirectly related to the query, improving the overall retrieval performance.
Technical Explanation
The paper proposes a "Cluster-Aware Similarity Diffusion" method to enhance instance retrieval. The key components are:
- Cluster-Aware Similarity Computation: The method first computes a "Reliable Node Similarity Matrix" to capture the inherent cluster structure of the data.
- Adaptive Similarity Diffusion: It then diffuses the similarity information across the clusters, using an "Adaptive Similarity Diffusion" process to capture the underlying relationships between instances.
- Instance Retrieval: The diffused similarity scores are used to rank the database instances and retrieve the most relevant ones for a given query.
The experiments demonstrate that this "Cluster-Aware Similarity Diffusion" approach outperforms traditional instance retrieval methods, particularly on datasets with strong cluster structures.
Critical Analysis
The paper provides a novel and promising approach to improving instance retrieval performance by leveraging the inherent cluster structure in data. However, some potential limitations and areas for further research are worth considering:
-
Sensitivity to Clustering Quality: The effectiveness of the Cluster-Aware Similarity Diffusion method may depend heavily on the quality of the initial clustering. If the clustering is not accurate or does not capture the true underlying structure, the subsequent diffusion process may not be as effective.
-
Computational Complexity: The paper does not explicitly discuss the computational complexity of the proposed method, which could be a concern for large-scale applications. The "Adaptive Similarity Diffusion" process, in particular, may add significant computational overhead.
-
Generalization to Other Domains: The experiments in the paper focus on image-based instance retrieval. It would be valuable to explore the performance of the Cluster-Aware Similarity Diffusion method in other domains, such as text-based or multi-modal retrieval, to assess its broader applicability.
-
Comparison to Alternative Clustering-based Approaches: While the paper compares the proposed method to traditional instance retrieval techniques, it would be informative to compare it to other clustering-based or graph-based approaches that aim to capture the underlying structure of the data.
Conclusion
The "Cluster-Aware Similarity Diffusion" method presented in this paper offers a promising approach to improving instance retrieval performance by leveraging the inherent cluster structure of data. By adaptively diffusing similarity information across clusters, the method can better capture the underlying relationships between instances, leading to more accurate retrieval results.
The key contribution of this work is the integration of cluster-aware similarity computation and adaptive diffusion, which represents an interesting advancement in the field of instance retrieval. While the method shows promising results, further research is needed to address potential limitations and explore its broader applicability across different domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Cluster-Aware Similarity Diffusion for Instance Retrieval
Jifei Luo, Hantao Yao, Changsheng Xu
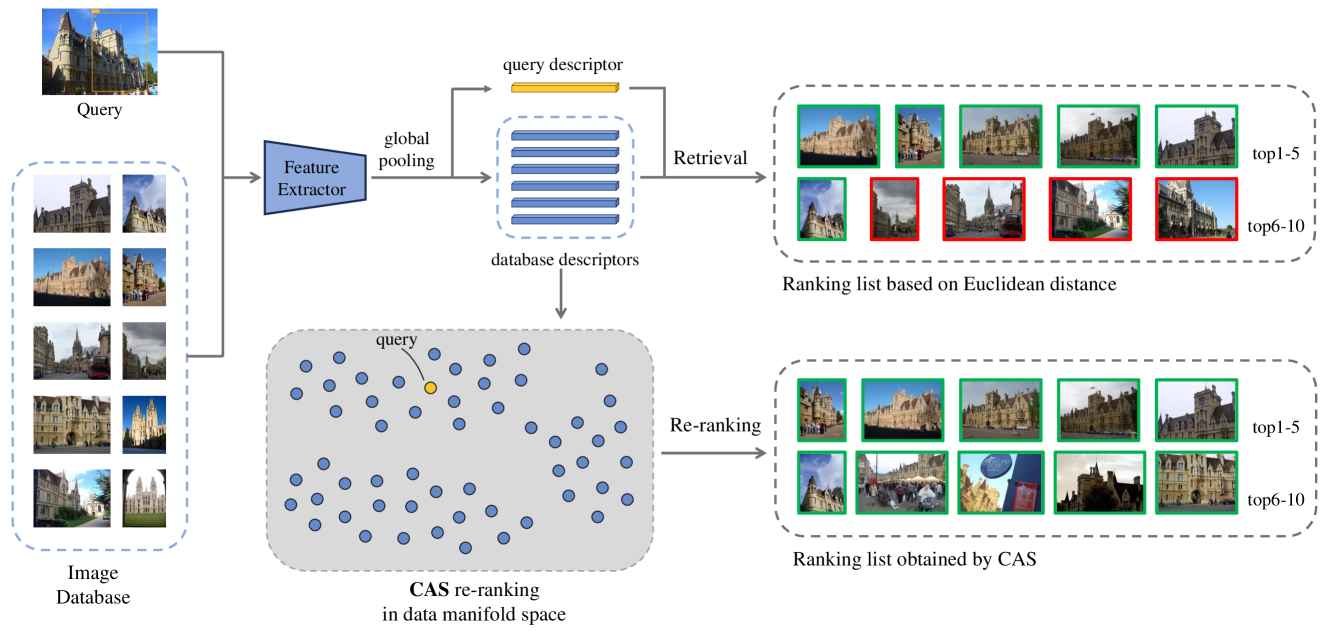
Diffusion-based re-ranking is a common method used for retrieving instances by performing similarity propagation in a nearest neighbor graph. However, existing techniques that construct the affinity graph based on pairwise instances can lead to the propagation of misinformation from outliers and other manifolds, resulting in inaccurate results. To overcome this issue, we propose a novel Cluster-Aware Similarity (CAS) diffusion for instance retrieval. The primary concept of CAS is to conduct similarity diffusion within local clusters, which can reduce the influence from other manifolds explicitly. To obtain a symmetrical and smooth similarity matrix, our Bidirectional Similarity Diffusion strategy introduces an inverse constraint term to the optimization objective of local cluster diffusion. Additionally, we have optimized a Neighbor-guided Similarity Smoothing approach to ensure similarity consistency among the local neighbors of each instance. Evaluations in instance retrieval and object re-identification validate the effectiveness of the proposed CAS, our code is publicly available.
Read more6/7/2024

0
Reliable Node Similarity Matrix Guided Contrastive Graph Clustering
Yunhui Liu, Xinyi Gao, Tieke He, Tao Zheng, Jianhua Zhao, Hongzhi Yin
Graph clustering, which involves the partitioning of nodes within a graph into disjoint clusters, holds significant importance for numerous subsequent applications. Recently, contrastive learning, known for utilizing supervisory information, has demonstrated encouraging results in deep graph clustering. This methodology facilitates the learning of favorable node representations for clustering by attracting positively correlated node pairs and distancing negatively correlated pairs within the representation space. Nevertheless, a significant limitation of existing methods is their inadequacy in thoroughly exploring node-wise similarity. For instance, some hypothesize that the node similarity matrix within the representation space is identical, ignoring the inherent semantic relationships among nodes. Given the fundamental role of instance similarity in clustering, our research investigates contrastive graph clustering from the perspective of the node similarity matrix. We argue that an ideal node similarity matrix within the representation space should accurately reflect the inherent semantic relationships among nodes, ensuring the preservation of semantic similarities in the learned representations. In response to this, we introduce a new framework, Reliable Node Similarity Matrix Guided Contrastive Graph Clustering (NS4GC), which estimates an approximately ideal node similarity matrix within the representation space to guide representation learning. Our method introduces node-neighbor alignment and semantic-aware sparsification, ensuring the node similarity matrix is both accurate and efficiently sparse. Comprehensive experiments conducted on $8$ real-world datasets affirm the efficacy of learning the node similarity matrix and the superior performance of NS4GC.
Read more8/9/2024

0
COS-Mix: Cosine Similarity and Distance Fusion for Improved Information Retrieval
Kush Juvekar, Anupam Purwar
This study proposes a novel hybrid retrieval strategy for Retrieval-Augmented Generation (RAG) that integrates cosine similarity and cosine distance measures to improve retrieval performance, particularly for sparse data. The traditional cosine similarity measure is widely used to capture the similarity between vectors in high-dimensional spaces. However, it has been shown that this measure can yield arbitrary results in certain scenarios. To address this limitation, we incorporate cosine distance measures to provide a complementary perspective by quantifying the dissimilarity between vectors. Our approach is experimented on proprietary data, unlike recent publications that have used open-source datasets. The proposed method demonstrates enhanced retrieval performance and provides a more comprehensive understanding of the semantic relationships between documents or items. This hybrid strategy offers a promising solution for efficiently and accurately retrieving relevant information in knowledge-intensive applications, leveraging techniques such as BM25 (sparse) retrieval , vector (Dense) retrieval, and cosine distance based retrieval to facilitate efficient information retrieval.
Read more6/4/2024

0
Collaborative Filtering Based on Diffusion Models: Unveiling the Potential of High-Order Connectivity
Yu Hou, Jin-Duk Park, Won-Yong Shin
A recent study has shown that diffusion models are well-suited for modeling the generative process of user-item interactions in recommender systems due to their denoising nature. However, existing diffusion model-based recommender systems do not explicitly leverage high-order connectivities that contain crucial collaborative signals for accurate recommendations. Addressing this gap, we propose CF-Diff, a new diffusion model-based collaborative filtering (CF) method, which is capable of making full use of collaborative signals along with multi-hop neighbors. Specifically, the forward-diffusion process adds random noise to user-item interactions, while the reverse-denoising process accommodates our own learning model, named cross-attention-guided multi-hop autoencoder (CAM-AE), to gradually recover the original user-item interactions. CAM-AE consists of two core modules: 1) the attention-aided AE module, responsible for precisely learning latent representations of user-item interactions while preserving the model's complexity at manageable levels, and 2) the multi-hop cross-attention module, which judiciously harnesses high-order connectivity information to capture enhanced collaborative signals. Through comprehensive experiments on three real-world datasets, we demonstrate that CF-Diff is (a) Superior: outperforming benchmark recommendation methods, achieving remarkable gains up to 7.29% compared to the best competitor, (b) Theoretically-validated: reducing computations while ensuring that the embeddings generated by our model closely approximate those from the original cross-attention, and (c) Scalable: proving the computational efficiency that scales linearly with the number of users or items.
Read more4/23/2024