COS-Mix: Cosine Similarity and Distance Fusion for Improved Information Retrieval

0

Sign in to get full access
Overview
- The paper introduces a new information retrieval method called COS-Mix that combines cosine similarity and distance fusion to improve search performance.
- COS-Mix aims to address limitations of existing retrieval systems by incorporating multiple distance metrics to provide a more comprehensive ranking of relevant documents.
- The authors evaluate COS-Mix on standard information retrieval benchmarks and demonstrate significant improvements over state-of-the-art baselines.
Plain English Explanation
Information retrieval systems are designed to find the most relevant documents or webpages in response to a user's search query. Blended-RAG: Improving RAG Retriever-Augmented Generation and Comparative Analysis of Retrieval Systems for Real-World Applications have explored ways to enhance the performance of these systems.
The key challenge is that search queries can be ambiguous, and the most relevant documents may not always be the closest match based on a single similarity metric, such as cosine similarity. COS-Mix aims to address this by combining multiple distance measures to provide a more holistic assessment of relevance.
The core idea is to use both cosine similarity, which captures semantic relatedness, and distance-based metrics, which can identify documents that may be conceptually distant but still highly relevant. By blending these approaches, COS-Mix can surface documents that may have been overlooked by traditional retrieval systems.
The authors evaluate COS-Mix on standard benchmarks and show that it outperforms state-of-the-art retrieval models, including those that use power-noise: Redefining Retrieval in RAG Systems and Efficient, Interpretable Information Retrieval for Product Question Answering. This suggests that the combined approach of cosine similarity and distance fusion can lead to significant improvements in information retrieval performance.
Technical Explanation
The COS-Mix approach starts by encoding the search query and each document using a language model, such as BERT. This allows the system to capture the semantic relationships between the query and the documents.
Next, COS-Mix computes the cosine similarity between the query and each document. Cosine similarity measures the angle between the vector representations, providing a sense of how semantically related the query and document are.
In parallel, COS-Mix also calculates several distance-based metrics, such as Euclidean distance and Jaccard distance. These measures quantify how similar the documents are in terms of their vector representations, regardless of their semantic relationship to the query.
The final step is to combine the cosine similarity and distance-based scores using a fusion technique, such as a weighted average or a learned model. This allows COS-Mix to leverage the strengths of both approaches to provide a more comprehensive ranking of relevant documents.
The authors evaluate COS-Mix on standard information retrieval benchmarks, including TREC and MS MARCO. They compare its performance to state-of-the-art retrieval models, including those that use Information Retrieval and Entity Linking techniques. The results demonstrate that COS-Mix consistently outperforms these baselines, suggesting that the combination of cosine similarity and distance fusion is a promising approach for improving information retrieval.
Critical Analysis
The paper presents a compelling approach to enhancing information retrieval, but there are a few areas that could be explored further:
-
Generalization to Different Domains: The authors evaluate COS-Mix on general information retrieval benchmarks, but it would be valuable to understand how it performs in more specialized domains, such as product search or medical literature search, where the relevance criteria may differ.
-
Interpretability of the Fusion Mechanism: The paper does not provide much detail on the specific fusion mechanism used to combine the cosine similarity and distance-based scores. A more transparent and interpretable fusion approach could help users understand the reasoning behind the retrieval results.
-
Computational Efficiency: While the authors demonstrate that COS-Mix outperforms state-of-the-art baselines, it's not clear how the additional computational complexity of the combined approach impacts the system's overall efficiency. This could be an important consideration for real-world deployment.
-
Robustness to Noisy or Adversarial Inputs: The paper does not address the system's behavior when faced with noisy or adversarial search queries, which can be a common challenge in practical information retrieval scenarios. Evaluating the robustness of COS-Mix in these conditions could provide valuable insights.
Overall, the COS-Mix approach presents a promising direction for improving information retrieval, but further research is needed to fully understand its strengths, limitations, and practical implications.
Conclusion
The COS-Mix method introduced in this paper represents a significant advancement in information retrieval by combining cosine similarity and distance-based metrics to provide a more comprehensive assessment of document relevance. The authors' experimental results demonstrate that this hybrid approach can outperform state-of-the-art retrieval models on standard benchmarks.
While the paper highlights several promising aspects of COS-Mix, there are also opportunities to further explore its generalization, interpretability, efficiency, and robustness. Addressing these areas could lead to even more impactful improvements in information retrieval systems, which are crucial for enabling effective access to the vast amounts of digital information available today.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
COS-Mix: Cosine Similarity and Distance Fusion for Improved Information Retrieval
Kush Juvekar, Anupam Purwar
This study proposes a novel hybrid retrieval strategy for Retrieval-Augmented Generation (RAG) that integrates cosine similarity and cosine distance measures to improve retrieval performance, particularly for sparse data. The traditional cosine similarity measure is widely used to capture the similarity between vectors in high-dimensional spaces. However, it has been shown that this measure can yield arbitrary results in certain scenarios. To address this limitation, we incorporate cosine distance measures to provide a complementary perspective by quantifying the dissimilarity between vectors. Our approach is experimented on proprietary data, unlike recent publications that have used open-source datasets. The proposed method demonstrates enhanced retrieval performance and provides a more comprehensive understanding of the semantic relationships between documents or items. This hybrid strategy offers a promising solution for efficiently and accurately retrieving relevant information in knowledge-intensive applications, leveraging techniques such as BM25 (sparse) retrieval , vector (Dense) retrieval, and cosine distance based retrieval to facilitate efficient information retrieval.
Read more6/4/2024

0
Efficient Retrieval with Learned Similarities
Bailu Ding, Jiaqi Zhai
Retrieval plays a fundamental role in recommendation systems, search, and natural language processing by efficiently finding relevant items from a large corpus given a query. Dot products have been widely used as the similarity function in such retrieval tasks, thanks to Maximum Inner Product Search (MIPS) that enabled efficient retrieval based on dot products. However, state-of-the-art retrieval algorithms have migrated to learned similarities. Such algorithms vary in form; the queries can be represented with multiple embeddings, complex neural networks can be deployed, the item ids can be decoded directly from queries using beam search, and multiple approaches can be combined in hybrid solutions. Unfortunately, we lack efficient solutions for retrieval in these state-of-the-art setups. Our work investigates techniques for approximate nearest neighbor search with learned similarity functions. We first prove that Mixture-of-Logits (MoL) is a universal approximator, and can express all learned similarity functions. We next propose techniques to retrieve the approximate top K results using MoL with a tight bound. We finally compare our techniques with existing approaches, showing that MoL sets new state-of-the-art results on recommendation retrieval tasks, and our approximate top-k retrieval with learned similarities outperforms baselines by up to two orders of magnitude in latency, while achieving > .99 recall rate of exact algorithms.
Read more8/15/2024

0
Relevance Filtering for Embedding-based Retrieval
Nicholas Rossi, Juexin Lin, Feng Liu, Zhen Yang, Tony Lee, Alessandro Magnani, Ciya Liao
In embedding-based retrieval, Approximate Nearest Neighbor (ANN) search enables efficient retrieval of similar items from large-scale datasets. While maximizing recall of relevant items is usually the goal of retrieval systems, a low precision may lead to a poor search experience. Unlike lexical retrieval, which inherently limits the size of the retrieved set through keyword matching, dense retrieval via ANN search has no natural cutoff. Moreover, the cosine similarity scores of embedding vectors are often optimized via contrastive or ranking losses, which make them difficult to interpret. Consequently, relying on top-K or cosine-similarity cutoff is often insufficient to filter out irrelevant results effectively. This issue is prominent in product search, where the number of relevant products is often small. This paper introduces a novel relevance filtering component (called Cosine Adapter) for embedding-based retrieval to address this challenge. Our approach maps raw cosine similarity scores to interpretable scores using a query-dependent mapping function. We then apply a global threshold on the mapped scores to filter out irrelevant results. We are able to significantly increase the precision of the retrieved set, at the expense of a small loss of recall. The effectiveness of our approach is demonstrated through experiments on both public MS MARCO dataset and internal Walmart product search data. Furthermore, online A/B testing on the Walmart site validates the practical value of our approach in real-world e-commerce settings.
Read more8/12/2024
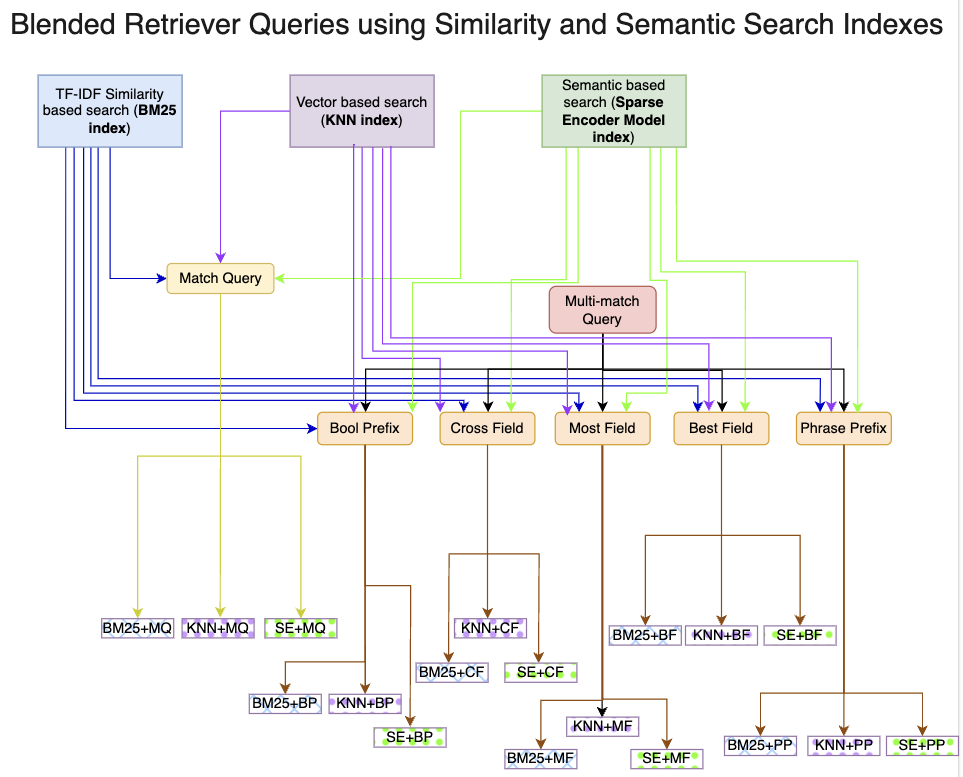
0
Blended RAG: Improving RAG (Retriever-Augmented Generation) Accuracy with Semantic Search and Hybrid Query-Based Retrievers
Kunal Sawarkar, Abhilasha Mangal, Shivam Raj Solanki
Retrieval-Augmented Generation (RAG) is a prevalent approach to infuse a private knowledge base of documents with Large Language Models (LLM) to build Generative Q&A (Question-Answering) systems. However, RAG accuracy becomes increasingly challenging as the corpus of documents scales up, with Retrievers playing an outsized role in the overall RAG accuracy by extracting the most relevant document from the corpus to provide context to the LLM. In this paper, we propose the 'Blended RAG' method of leveraging semantic search techniques, such as Dense Vector indexes and Sparse Encoder indexes, blended with hybrid query strategies. Our study achieves better retrieval results and sets new benchmarks for IR (Information Retrieval) datasets like NQ and TREC-COVID datasets. We further extend such a 'Blended Retriever' to the RAG system to demonstrate far superior results on Generative Q&A datasets like SQUAD, even surpassing fine-tuning performance.
Read more4/12/2024