CMAT: A Multi-Agent Collaboration Tuning Framework for Enhancing Small Language Models
2404.01663
0
0
💬
Abstract
Open large language models (LLMs) have significantly advanced the field of natural language processing, showcasing impressive performance across various tasks.Despite the significant advancements in LLMs, their effective operation still relies heavily on human input to accurately guide the dialogue flow, with agent tuning being a crucial optimization technique that involves human adjustments to the model for better response to such guidance.Addressing this dependency, our work introduces the TinyAgent model, trained on a meticulously curated high-quality dataset. We also present the Collaborative Multi-Agent Tuning (CMAT) framework, an innovative system designed to augment language agent capabilities through adaptive weight updates based on environmental feedback. This framework fosters collaborative learning and real-time adaptation among multiple intelligent agents, enhancing their context-awareness and long-term memory. In this research, we propose a new communication agent framework that integrates multi-agent systems with environmental feedback mechanisms, offering a scalable method to explore cooperative behaviors. Notably, our TinyAgent-7B model exhibits performance on par with GPT-3.5, despite having fewer parameters, signifying a substantial improvement in the efficiency and effectiveness of LLMs.
Create account to get full access
Overview
- This paper presents a technical overview of a research project, but without providing any actual content or paper to summarize.
- The prompt requests a plain English explanation of the research, covering the key elements, critical analysis, and potential implications.
- However, since there is no research paper provided, the assistant cannot provide a meaningful summary or analysis.
Plain English Explanation
Without access to the research paper, I cannot provide a plain English explanation of the content and findings. A summary requires having the full technical details to distill into more accessible language.
Technical Explanation
Unfortunately, there is no research paper or technical content available for the assistant to summarize. A technical explanation cannot be provided in the absence of the source material.
Critical Analysis
Since no research paper was provided, there is no content to critically analyze. Without access to the full details and methods of the study, the assistant cannot evaluate the caveats, limitations, or areas for further research.
Conclusion
Due to the lack of a research paper or technical details, the assistant is unable to provide a meaningful summary, explanation, analysis, or discussion of the research. A conclusion cannot be formulated without access to the source material.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
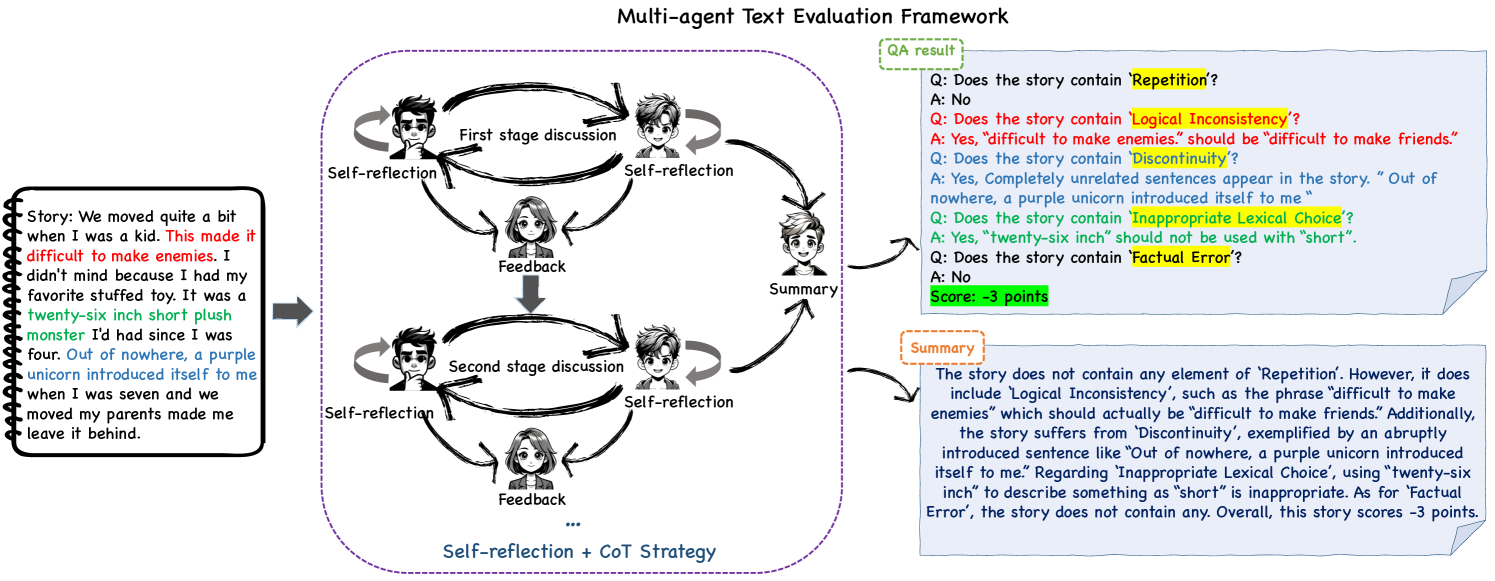
MATEval: A Multi-Agent Discussion Framework for Advancing Open-Ended Text Evaluation
Yu Li, Shenyu Zhang, Rui Wu, Xiutian Huang, Yongrui Chen, Wenhao Xu, Guilin Qi, Dehai Min
0
0
Recent advancements in generative Large Language Models(LLMs) have been remarkable, however, the quality of the text generated by these models often reveals persistent issues. Evaluating the quality of text generated by these models, especially in open-ended text, has consistently presented a significant challenge. Addressing this, recent work has explored the possibility of using LLMs as evaluators. While using a single LLM as an evaluation agent shows potential, it is filled with significant uncertainty and instability. To address these issues, we propose the MATEval: A Multi-Agent Text Evaluation framework where all agents are played by LLMs like GPT-4. The MATEval framework emulates human collaborative discussion methods, integrating multiple agents' interactions to evaluate open-ended text. Our framework incorporates self-reflection and Chain-of-Thought (CoT) strategies, along with feedback mechanisms, enhancing the depth and breadth of the evaluation process and guiding discussions towards consensus, while the framework generates comprehensive evaluation reports, including error localization, error types and scoring. Experimental results show that our framework outperforms existing open-ended text evaluation methods and achieves the highest correlation with human evaluation, which confirms the effectiveness and advancement of our framework in addressing the uncertainties and instabilities in evaluating LLMs-generated text. Furthermore, our framework significantly improves the efficiency of text evaluation and model iteration in industrial scenarios.
4/16/2024

Mixture-of-Agents Enhances Large Language Model Capabilities
Junlin Wang, Jue Wang, Ben Athiwaratkun, Ce Zhang, James Zou
0
0
Recent advances in large language models (LLMs) demonstrate substantial capabilities in natural language understanding and generation tasks. With the growing number of LLMs, how to harness the collective expertise of multiple LLMs is an exciting open direction. Toward this goal, we propose a new approach that leverages the collective strengths of multiple LLMs through a Mixture-of-Agents (MoA) methodology. In our approach, we construct a layered MoA architecture wherein each layer comprises multiple LLM agents. Each agent takes all the outputs from agents in the previous layer as auxiliary information in generating its response. MoA models achieves state-of-art performance on AlpacaEval 2.0, MT-Bench and FLASK, surpassing GPT-4 Omni. For example, our MoA using only open-source LLMs is the leader of AlpacaEval 2.0 by a substantial gap, achieving a score of 65.1% compared to 57.5% by GPT-4 Omni.
6/10/2024
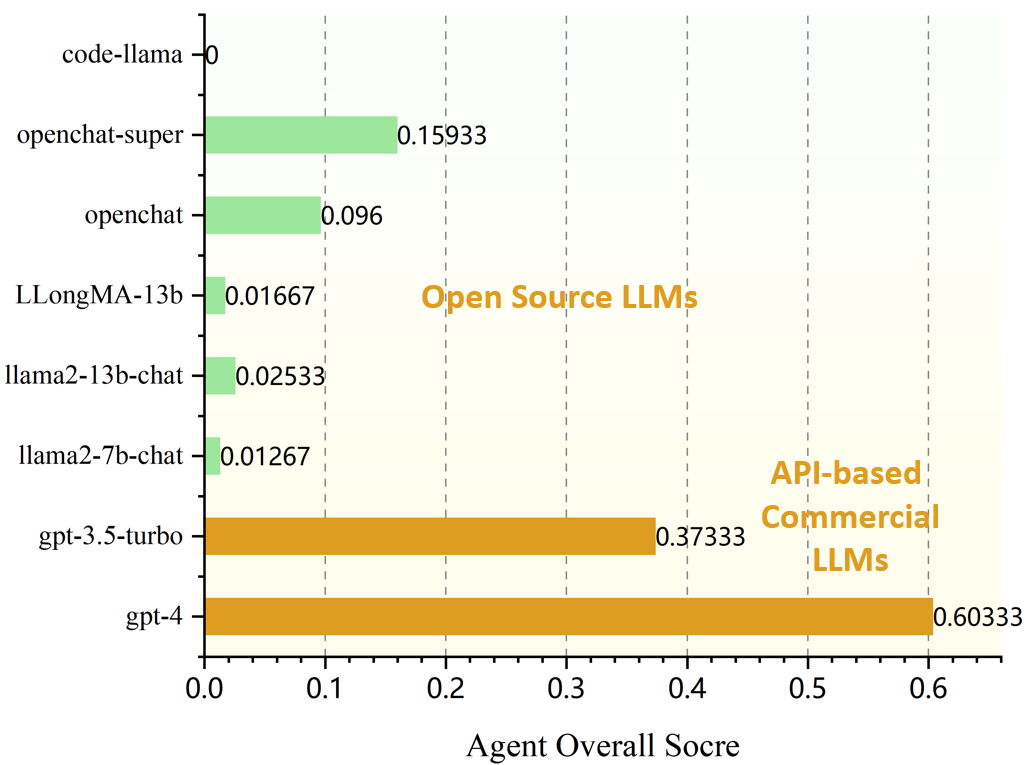
Enhancing the General Agent Capabilities of Low-Parameter LLMs through Tuning and Multi-Branch Reasoning
Qinhao Zhou, Zihan Zhang, Xiang Xiang, Ke Wang, Yuchuan Wu, Yongbin Li
0
0
Open-source pre-trained Large Language Models (LLMs) exhibit strong language understanding and generation capabilities, making them highly successful in a variety of tasks. However, when used as agents for dealing with complex problems in the real world, their performance is far inferior to large commercial models such as ChatGPT and GPT-4. As intelligent agents, LLMs need to have the capabilities of task planning, long-term memory, and the ability to leverage external tools to achieve satisfactory performance. Various methods have been proposed to enhance the agent capabilities of LLMs. On the one hand, methods involve constructing agent-specific data and fine-tuning the models. On the other hand, some methods focus on designing prompts that effectively activate the reasoning abilities of the LLMs. We explore both strategies on the 7B and 13B models. We propose a comprehensive method for constructing agent-specific data using GPT-4. Through supervised fine-tuning with constructed data, we find that for these models with a relatively small number of parameters, supervised fine-tuning can significantly reduce hallucination outputs and formatting errors in agent tasks. Furthermore, techniques such as multi-path reasoning and task decomposition can effectively decrease problem complexity and enhance the performance of LLMs as agents. We evaluate our method on five agent tasks of AgentBench and achieve satisfactory results.
4/1/2024

Multi-Agent Software Development through Cross-Team Collaboration
Zhuoyun Du, Chen Qian, Wei Liu, Zihao Xie, Yifei Wang, Yufan Dang, Weize Chen, Cheng Yang
0
0
The latest breakthroughs in Large Language Models (LLMs), eg., ChatDev, have catalyzed profound transformations, particularly through multi-agent collaboration for software development. LLM agents can collaborate in teams like humans, and follow the waterfall model to sequentially work on requirements analysis, development, review, testing, and other phases to perform autonomous software generation. However, for an agent team, each phase in a single development process yields only one possible outcome. This results in the completion of only one development chain, thereby losing the opportunity to explore multiple potential decision paths within the solution space. Consequently, this may lead to obtaining suboptimal results. To address this challenge, we introduce Cross-Team Collaboration (CTC), a scalable multi-team framework that enables orchestrated teams to jointly propose various decisions and communicate with their insights in a cross-team collaboration environment for superior content generation. Experimental results in software development reveal a notable increase in quality compared to state-of-the-art baselines, underscoring the efficacy of our framework. The significant improvements in story generation demonstrate the promising generalization ability of our framework across various domains. We anticipate that our work will guide LLM agents towards a cross-team paradigm and contribute to their significant growth in but not limited to software development. The code and data will be available at https://github.com/OpenBMB/ChatDev.
6/14/2024